Category: Solr
On a recent enterprise search project we were tasked with taking over six million documents and making them searchable by the general public, all within a very short development window.
Our solution was to build a lightweight search application in Javascript that would return results directly from Solr. Using this architecture allowed us to bypass the conventional server requirements, and meant that we could make the application fast and performant on client machines without having to spend tons on server resources. This model also gave us a lot of flexibility during projects development phase and enabled us to complete the application within a condensed timeframe.
To illustrate the difference in approach: in the traditional model the load is placed on the server to render resources and relay database queries.
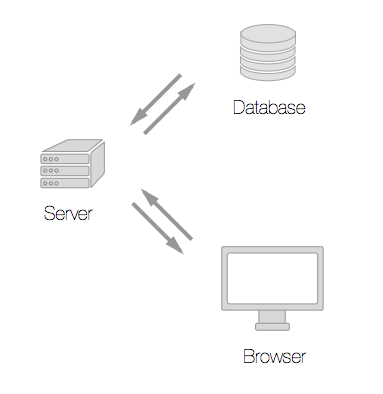
But, in the client-side model once the application is downloaded it talks directly to the database.
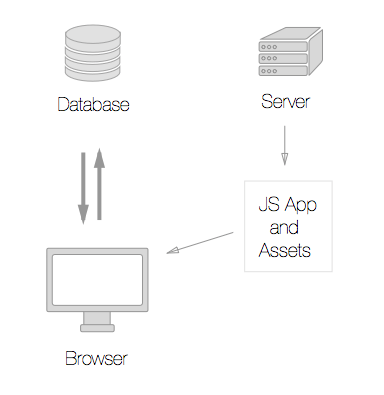
So how does it all work? The javascript search application interfaces directly with a Solr database through JSON which means that there are no intermediary servers in the conventional sense. We decided to develop the application with EmberJS. Using Ember allowed us to cut down our development time and focus on the core functionality instead of re-inventing data bindings, routing, or memory management. While building the application we attempted to make the code as modular and database-agnostic as possible. This lead to a reusable codebase for full-text search interfaces that we are calling Spyglass.
Spyglass is built with EmberJS and comes with many of the search components you need to create a lightweight search interface right out of the box. In Spyglass there is the concept of:
- Searchers that return a result from a given url,
- a Search Box which is a simple input tied to its searcher,
- Result Sets that automatically show the results returned by their searchers, and
- Facets which toggle search parameters. Both result sets and facets are extensions of
SearcherObservers which update automatically when their linkedsearcher has new objects.
This framework is something that we have been working on over the last few months and will be open sourcing soon. Stay tuned.
Conclusion
Deciding to build a client-side search application allowed OpenSource Connections to rapidly iterate through development, and deliver a product that will maximize scalability while minimizing costs. It was an exciting project to work on and one where we really learned a lot about application design and working with massive amounts of data. In the end we proved that search applications can be built rapidly, with a minimal set of application components, while still functioning at a very large scale.
We look forward to sharing more about SpyGlass and the details of this specific client project in the near future. If you are interested in working with us on a client-side search application, drop us a line.