Category: Uncategorized
A proof of concept in Chorus OpenSearch Edition
TL;DR:
Team draft interleaving provides a path to faster A/B testing. Our proof of concept implementation within the Chorus Ecommerce search system provides a clear example of its potential. By making good use of the User Behavior Insights and Search Relevance Workbench provided in OpenSearch (3.1+) we see a way forward for integrated A/B testing support in the search engine API.
Introduction
A/B Testing Is Important
No one ever said, “I’m going to go out to the garage and search.” Search is not an end unto itself. Rather, it is an enabling technology. The proof of the pudding is in the quality of the results returned from the point of view of the one who did the searching. As search professionals, we know a number of ways to evaluate that quality. One well used tool is the A/B test. We put the question directly to the consumers of the search, using their choices as the measure of success. While the specific KPI or metric you may want to use for your system may be unique, the general model of click through rate (CTR) can be applied to most search systems.A/B testing requires partitioning your site traffic into two (or more) arms. The A arm running your current algorithm, the B arm running the alternative to be considered. Having done this, you have effectively cut your traffic in half. AB Test Guide sample size calculator provides a tool (there are many others) to calculate the number of visitors you need for each arm to achieve a specific power and confidence level goal for your test. If you play with numbers for a bit, you will find that you need quite a bit of traffic to obtain meaningful results. This is problematic.
But It’s Too Slow
One approach that reduces the amount of traffic required, and the associated time to complete your A/B test, is to employ an interleaving approach, such as Team Draft Interleaving (TDI).
TDI merges the results of the A and B arms into a single result list that is then presented to the users. The benefits of this approach include requiring less traffic, as each arm is seen by all users, and ensuring that the users who see the B arm aren’t left out in the cold if algorithm B turns out to be a dud.
To evaluate the performance of the two arms, we again appeal to our KPI or metric, computable from tracking data. At a minimum, we need to know for every query, the views and clicks at each rank for each of the returned results, based on which of the two algorithms produced each result.
This blog post will walk through how we realized TDI in the context of our Chorus OpenSearch Edition Ecommerce reference platform. We use OpenSearch to take advantage of tooling provided to both collect user data and provision experimental configurations. This PoC could be the basis for incorporating the TDI functionality directly into OpenSearch.
Team Draft Interleaving
Team Draft Interleaving is an algorithm for combining two result lists into a single unified list. The basic algorithm is very similar to Reciprocal Rank Fusion. Abstractly, it could be presented as an alternative result list combination to those used in an OpenSearch hybrid search pipeline.
We begin with two lists of results, one provided by Algorithm A, the other by Algorithm B. Each list is of length less than or equal to k, the size parameter for the final merged result list.
At each iteration, we examine the current rank of the next element in each list. When A’s rank is greater than B’s (ranks are increasing as we traverse the list), we select that element as our next result. When B’s rank is less than A’s we select B’s element. When the ranks are tied, we flip a coin to decide whether to take A or take B. Items that have already been added to the result list are dropped. We stop when k elements have been selected, or when we run out of elements in both lists. Once one list is empty, the remaining elements up to k are drawn from the other list. Each item is tagged with the team name that it was selected from.
The use of the random choice of A or B helps to mitigate ordering bias (but does not completely do so). Because both algorithms are represented in every search results page, all users see both the control and treatment algorithms at the same time. This helps to mitigate the risks associated with presenting an experimental algorithm to the users. Harm could be done if it were a dud.
Goal – TDI in Chorus OpenSearch Edition
Using the resources provided by User Behavior Insights (UBI) and Search Relevance Workbench (SRW), we would like to enable A/B testing that requires no external orchestration, front-end modification, nor third-party instrumentation. We want to provide an implementation of TDI, an algorithm for A/B testing that presents a single result list to each user, with the competing search algorithms both represented in the list. This facilitates faster A/B testing, as the user pool is not divided into treatment groups.
We would also like to build an A/B test visualization component, taking advantage of a UBI event simulator to generate test results.
The architectural plan follows the following diagram.
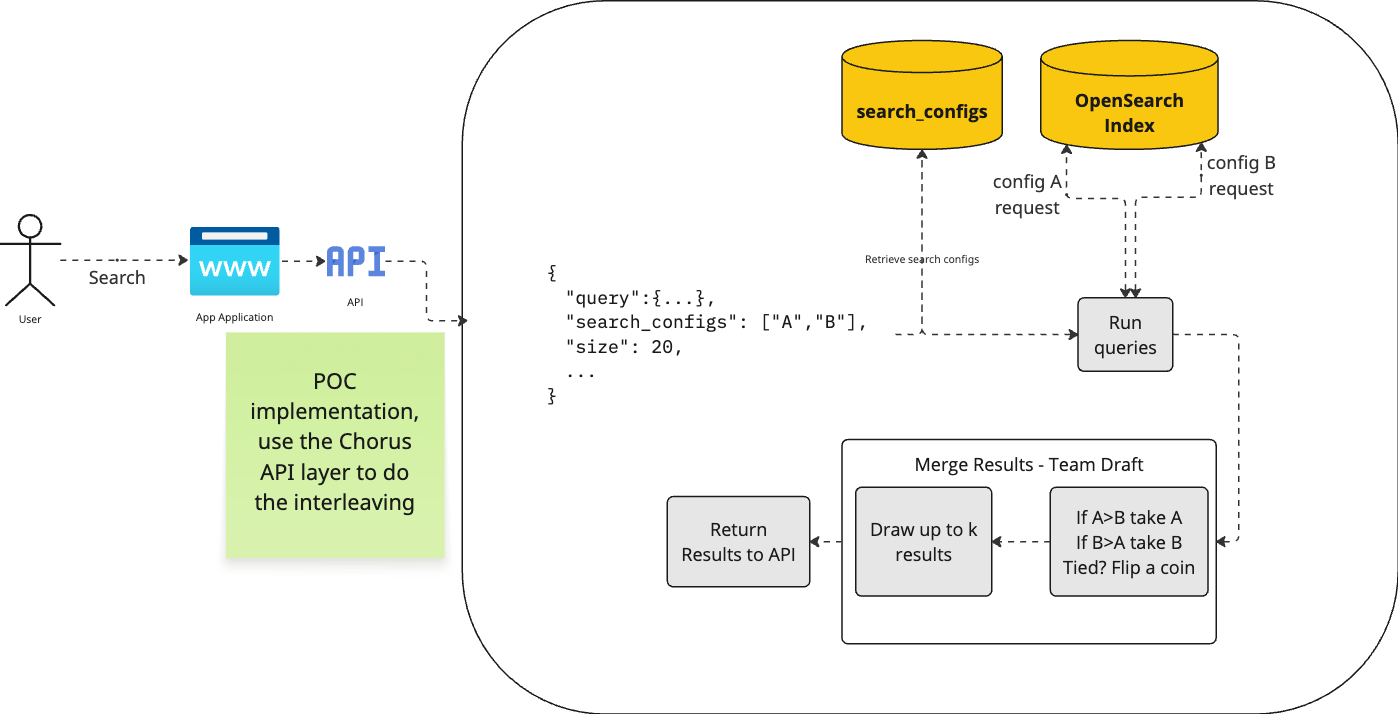
Using TDI A/B Testing
We anticipate two personas using A/B testing to evaluate search systems.
The Developer
Wants to use the per query results to drill down into search relevance performance issues. They will likely want to flag the problem children for closer examination in SRW. While aggregate measures are of value, the primary need is to identify trouble spots.
The Business
Wants to evaluate the aggregate performance of competing search algorithms with respect to performance on specific KPIs. They will be the likely consumers of the visualizations. Here the individual query performance is not as interesting as the overall performance. As the primary consumer of A/B test evaluation, we focus our dashboard example on this user.
Implementation
Chorus
Reactive Search Front End
Chorus already had alternative algorithms for searching. To enable an A/B test configuration, we add one more item to the “Pick your Algo” drop down selector. When selected, two text entries are presented to collect the two search configuration names. When the algorithm is AB, the search configuration names are passed along in the query requests to the middleware.
Chorus is already configured to collect UBI events. What it did not do is record the search configuration used to produce the result items. The application has been updated to record that data when it is returned by the middleware.
Middleware
We add a straightforward implementation of TDI. The _msearch route is updated to check for search configuration names in the query request. When present, each search configuration is instantiated with the user’s original query terms. Both queries are then retrieved, with the final results updated to be the TDI of the two, with the credited search configuration recorded directly in each hit.
OpenSearch Backend
No modifications are required in OpenSearch. We use version 3.1, which ships with both UBI and SRW.
UBI
To create sampled UBI queries and synthetic UBI events, we cloned the ESCI data set and User Behavior Insights repositories and used the UBI Data Generator to generate 100,000 query events for 1,000 unique queries. The command line is shown below.
python ubi_data_generator.py –esci-dataset ../../esci-data/shopping_queries_dataset –num-unique-queries 1000 –num-query-events 100000 –generate-OpenSearch –datetime-start=2025/06/20 –time-period-days=7
These events are generated with the search config labels TeamA and TeamB, with TeamA having a 60% chance of a click event, and TeamB having a 40% chance. Both have an equal chance of an impression event. Using this synthetic data, we can view the effective lift (negative in this case) over the week long period events are generated for in the Team Draft Interleaving dashboard.
SRW
The Search Relevance Workbench must be enabled in OpenSearch 3.1. See Search Relevance Tools for the Dashboard setting.
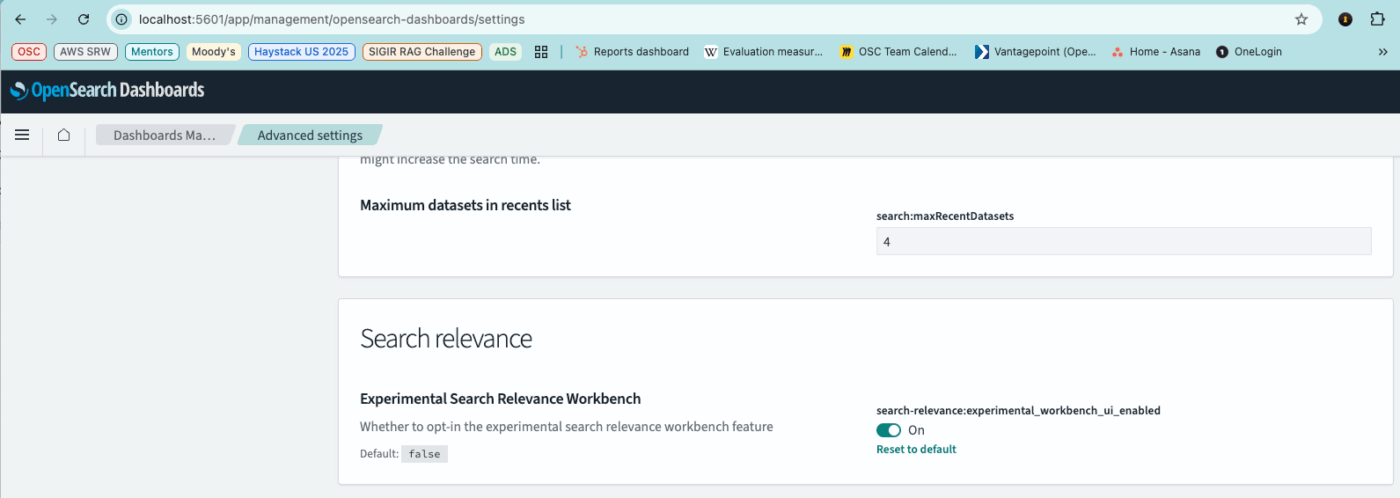
Additionally, the plugin must be enabled. This can be done via curl:
curl -X PUT “http://localhost:9200/_cluster/settings” -H ‘Content-Type: application/json’ -d'{
“persistent” : {
“plugins.search_relevance.workbench_enabled” : true
}
}’
Search Configurations
See SRW Search Configs for how to manually create search configurations. For this example, only two search configurations are required. They can be installed via curl.
curl -s -X PUT “http://localhost:9200/_plugins/_search_relevance/search_configurations” \
-H “Content-type: application/json” \
-d'{
“name”: “baseline”,
“query”: “{\”query\”:{\”multi_match\”:{\”query\”:\”%SearchText%\”,\”fields\”:[\”id\”,\”title\”,\”category\”,\”bullets\”,\”description\”,\”attrs.Brand\”,\”attrs.Color\”]}}}”,
“index”: “ecommerce”
}’
curl -s -X PUT “http://localhost:9200/_plugins/_search_relevance/search_configurations” \
-H “Content-type: application/json” \
-d'{
“name”: “baseline with title weight”,
“query”: “{\”query\”:{\”multi_match\”:{\”query\”:\”%SearchText%\”,\”fields\”:[\”id\”,\”title^25\”,\”category\”,\”bullets\”,\”description\”,\”attrs.Brand\”,\”attrs.Color\”]}}}”,
“index”: “ecommerce”
}’
OpenSearch Dashboard
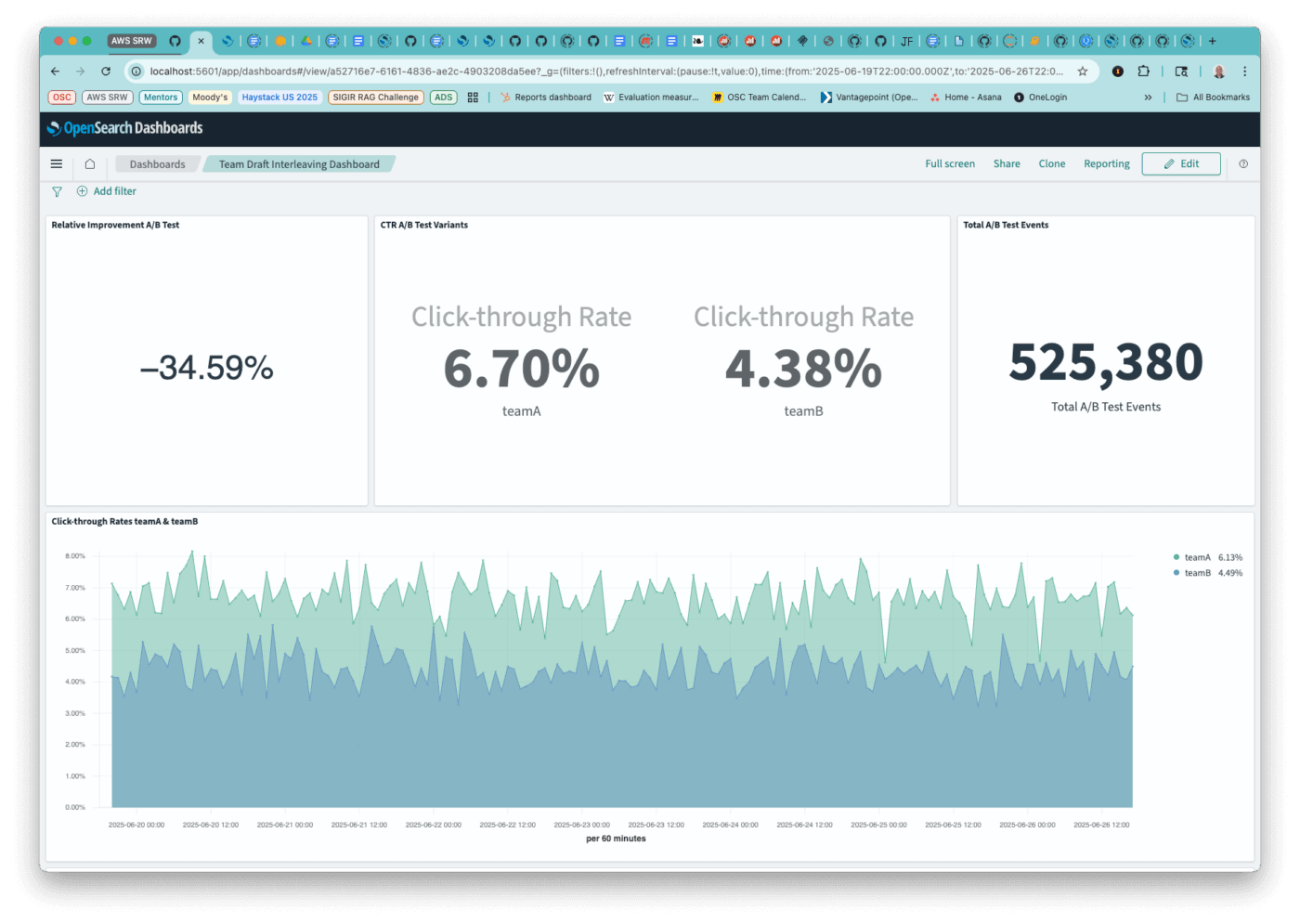
We created an OpenSearch Dashboard to visualize the click through rate and relative change (lift) of the recorded ubi events. Using the dashboard to visualize actual search configurations will require modifying the elements to use the search configuration names in place of the hard coded TeamA and TeamB.
We use the synthetic UBI events that we generated to demonstrate the power of these visualizations. As seen below, TeamB underperforms TeamA to the tune of -35%. This is exactly as expected given that TeamB had a 40% chance of getting a click event, and TeamA had a 60% chance. We expect the lift to be -⅓ or so. Lift is (CTR(TeamB)-CTR(TeamA))/CTR(TeamA).
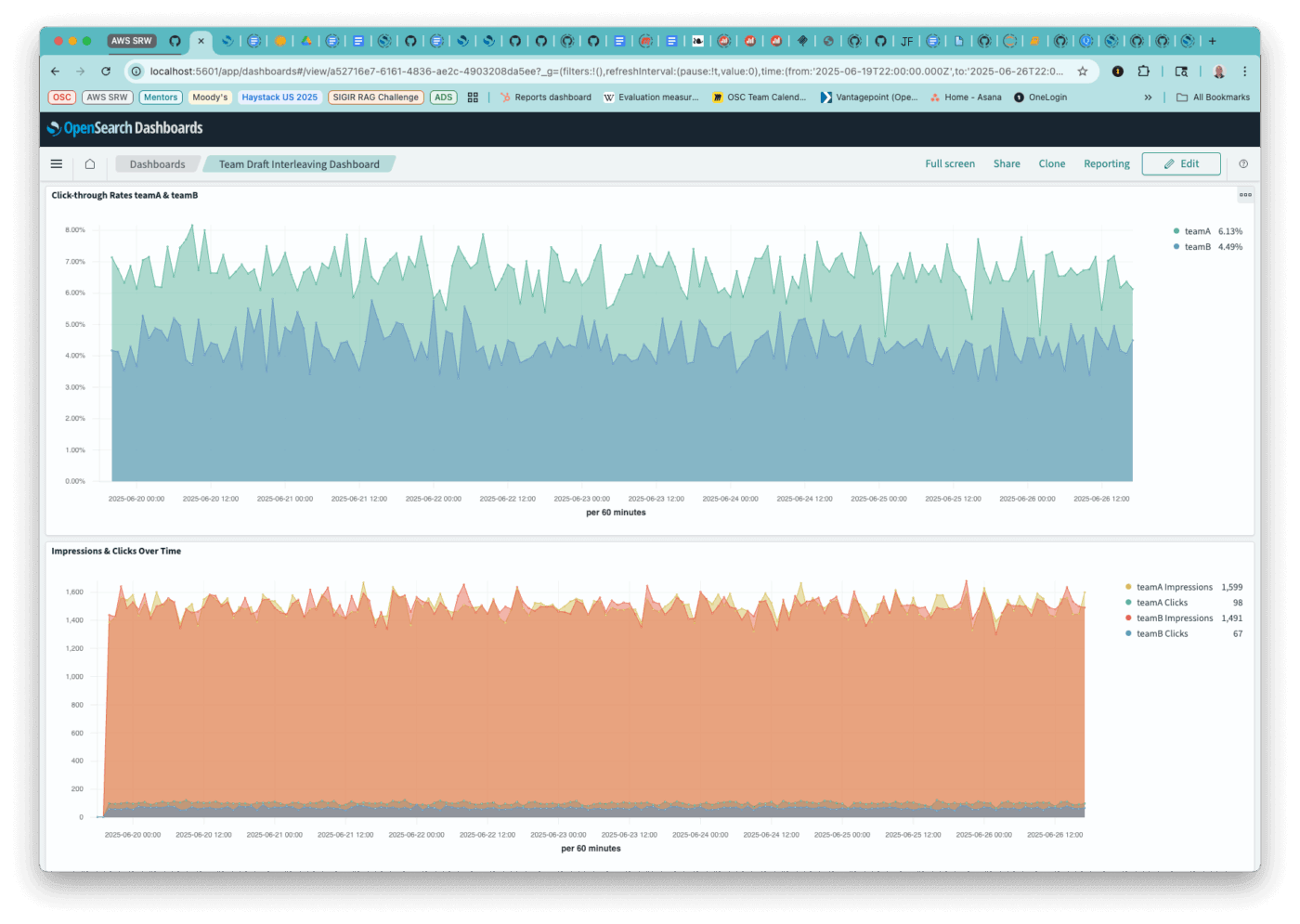
The Dashboard also shows Click-through Rates and total number of events.
The two graphs show the clicks, impressions and click-through rates over time.
Now that we have all the pieces, let’s look at how to set things up within Chorus.
Running Chorus
This section covers part of the Chorus kata, katas/007_configure_AB_with_TDI.md.
Quick Start
Use quickstart.sh –full_dataset to run the Chorus setup. It will perform the following tasks:
- Create and start the docker containers for
- OpenSearch 3.1
- OpenSearch 3.1 dashboards
- Chorus middleware
- Chorus ReactiveSearch
- Download and transform the ESCI product data set
- Update the ML plugin and install a model group for neural search
- Create the ingestion pipeline to use that model
- Index the product data
- Create the neural and hybrid search pipelines
- Update the index with embeddings
- Install the UBI dashboard
- Install the TDI dashboard
- Create and start the dataprepper docker container
Configuring an AB test
Now that Chorus is up and running, load up the home page. On the left hand side, select AB from the Pick your Algo drop down menu:
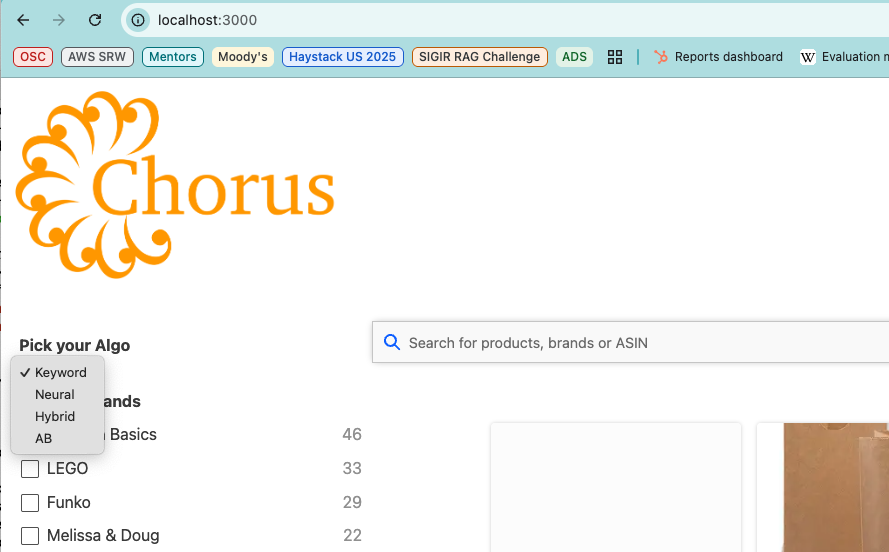
Two text entry boxes will appear. In the first, enter baseline and in the second enter baseline with title weight

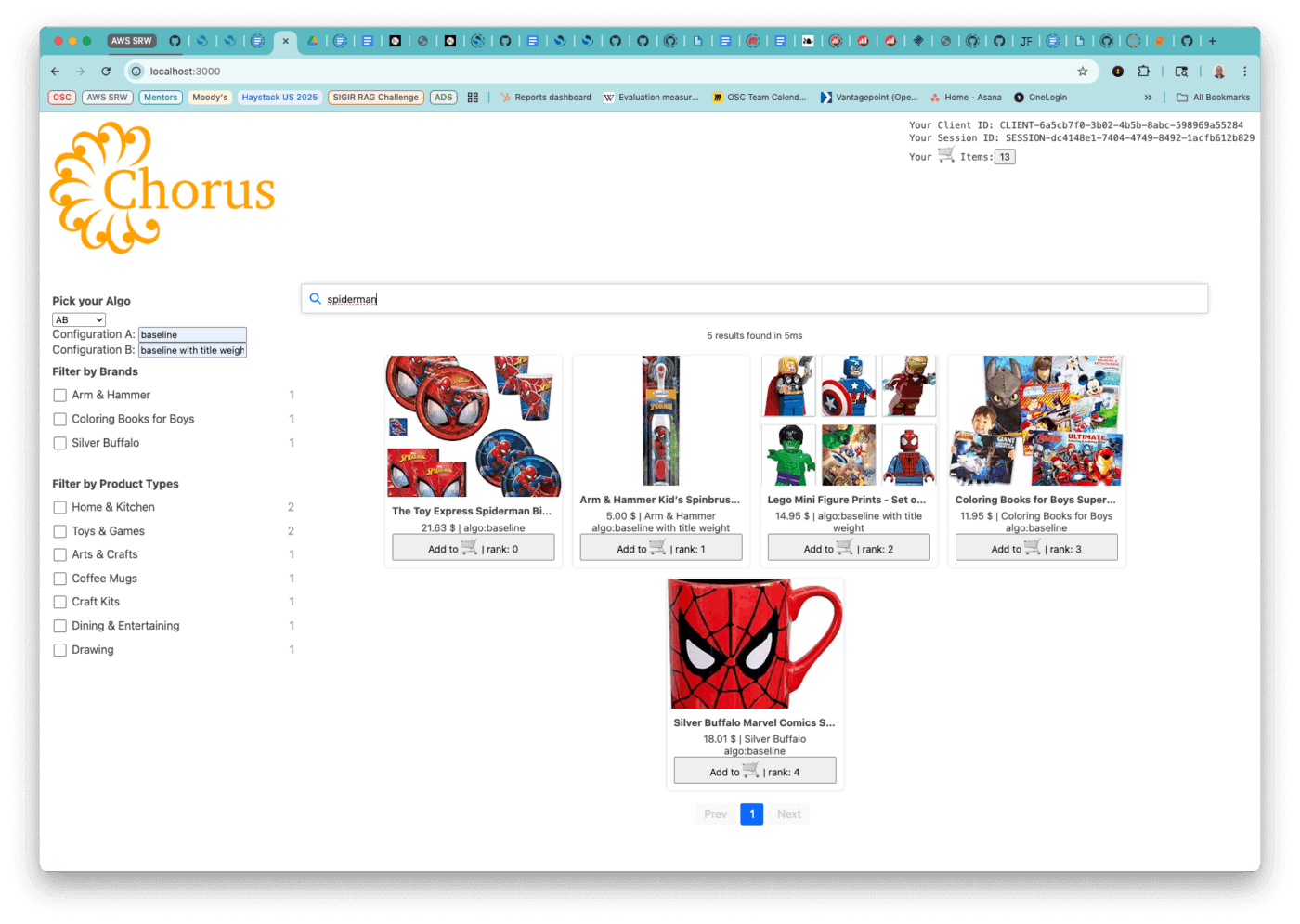
Now, when you enter a query in the search box, both chosen configurations will be executed, with their result lists interleaved. As shown below, the query “spiderman” produces a total of 5 results. Inspecting the items, you can see that the algorithm interleaving began with configuration B.
- baseline with title weight
- baseline
- baseline with title weight
- baseline
- baseline
Running the query a second time may yield baseline as the first item.
Conclusion
By leveraging the power of UBI and the creation of Search Configurations with SRW, it is straightforward to add support for A/B testing to a reasonably complex search system, Chorus. Employing TDI in the search API component enables orchestrating the running of the test arms with minimal impact on the search system. As such, there is reason to believe that a comparable API-level call belongs in OpenSearch (or any other search engine).
The act of interleaving results, regardless of the algorithm, is well represented within the search pipeline capabilities of OpenSearch. One possible implementation would be to define a combination method that implements the TDI algorithm. Incorporating TDI, or other more complex interleaving algorithms, will enable faster evaluation of individual search systems and wider adoption of both SRW and UBI.
It is our hope that this sparks further conversation and consideration of [RFC] Team Draft Interleaving for A/B Testing by the community at large.
Further Reading and Related Work
User Behavior Insights – OpenSearch Documentation
How does clickthrough data reflect retrieval quality?
Comparing the Sensitivity of Information Retrieval Metrics – Microsoft Research