Category: Uncategorized
I’m Jonathan Thompson, a rising 4th year CS major at UVA. This is my first blog post as an intern at OSC, I hope you enjoy it!
\n\n
While my teammate Krystal worked on integrating OSCAR, the OSC Automated Robot, with Solr, I forked the project and used it as an opportunity to demo Elasticsearch. Was a multi-node distributed solution overkill for this relatively simple project? Probably, but I learned a lot about Elasticsearch and had fun setting everything up. I’m going to give you my impressions of Elasticsearch from the past few days of researching and using it.
\n\n
Elasticsearch is a real time “distributed RESTful search and analytics” engine. The easiest way to explore Elasticsearch is to download it, but here’s a synopsis. JSON documents are stored in primary shards. These primary shards are associated with any number of replica shards. These shards are stored on different nodes in your cluster. A node is a single Elasticsearch instance (usually corresponding to a single server). A cluster is a logical partitioning of nodes that contains one master node. This master node controls the distribution of shards across nodes, cluster health, and node status. This network is completely peer to peer and distributed, so any queries (URI or http post with a JSON payload) can go to any node in the cluster to be handled. If any nodes go offline, the data will be redistributed accordingly, and if a master node goes offline, the cluster will automatically elect a new one. An index with multiple types is similar to a Solr instance with multiple collections, but with Elasticsearch, any number of indicies can be stored over any number of nodes or clusters. What this means is that a single index with a large number of documents of a single type can be split among many machines, but also many indicies with many types can be run on a single machine, assuming a small number of documents for each type. You can start your build with a single server or EC2 instance, and easily add more as your database grows.
\n\n
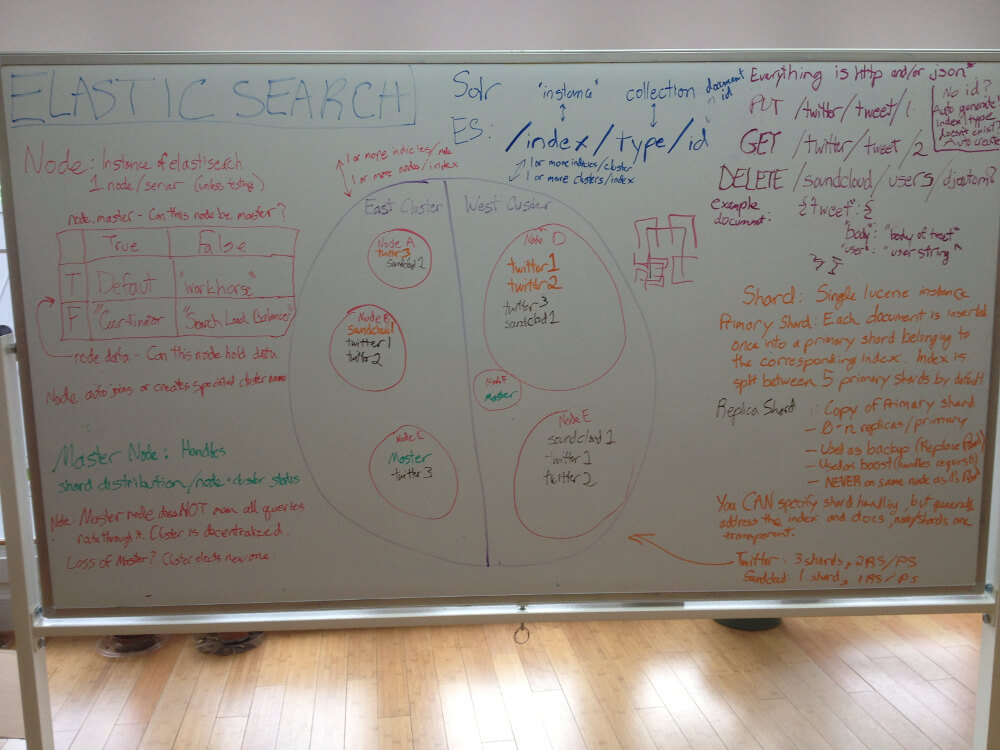
{kind=link}
\n\n
When Elasticsearch is brought up in conversation Solr has to be mentioned as well, seeing as both are open source search and analytic engines built on top of Lucene. Solr is the stable incumbent with many advanced and refined features. Solr has some distributed capabilities, but these have only been added on fairly recently. Elasticsearch is the challenger, and it lacks some of the advanced features of Solr, but it is built from the ground up for distributed search, and offers fast spin up times, powerful automatic configuration and management options, and lots of flexibility.
\n\n
I’m probably going to tackle a direct comparison of the two in a later post, but for more information now, Sematext wrote an excellent 6 part breakdown of Solr vs Elasticsearch. Without further adieu, here are my impressions of Elasticsearch.
\n\n
Elasticsearch is fast and easy
\n\n
For spin up, I downloaded the code, ran an elasticsearch “node”, and sent it a http PUT request with my data in json form as the payload. Elasticsearch automatically created an index, determined the data type of each field, and created a mapping for the “type” of document I had just submitted. If that weren’t cool enough, just by starting another node in another terminal, it detected the second node and started to distribute the index load among the nodes. Realistically, each node in your system should correspond to a single server or EC2 instance, but for testing you can run multiple nodes on a single machine. I started another few nodes just for kicks, and in 5 minutes had a distributed system that could handle node removals and additions with ease!
\n\n
“Schema free” is a lie… but in a good way!
\n\n
Elasticsearch is schema free by default, but you can very easily specify “mappings” to override the auto-indexing features. In fact, this principle holds to many other features of Elasticsearch. All cluster, node, and shard management is automatically handled, but you can directly control almost anything if necessary. For example, you can specify document and shard placement on nodes explicitly with “routing”, create advanced network topologies by altering per node options, and change cluster wide configuration settings with ease.
\n\n
Powerful plugins and flexibility
\n\n
In addition to the main API being exposed over http, thrift, and memcached, there are also many other ways to access and extend Elasticsearch. An official Java and Groovy API give you access to the main API and more. The “River” system pulls streams of data into your cluster. Last, but not least, Elasticsearch’s plugin system lets you extend and tweak Elasticsearch to fit your needs. There’s everything from custom mapping types, analyzers, request handlers, and network management plugins to site plugins that let you build a web front end that lives on your cluster. A few quick examples I found useful:
\n\n
- \n
- The elasticsearch adapter for Ember.js lets you use elasticsearch as a storage engine. I was able to quickly modify elasticsearch’s Ember integration tutorial to create a Task list from all emails sent to OSCAR that contained “task” in the email subject line.
- An EC2 discovery module is included, and other plugins available add features to make deployment to EC2 even easier.
- A Solr plugin parses incoming queries in Solr format and emulates Solr responses, and a Solr River plugin lets you import data from a Solr instance.
\n
\n
\n
\n\n
In summary, Elasticsearch is a young but powerful open source solution for distributed search solutions, and while a specialized search problem will probably benefit greatly from Solr’s optimizations, both Solr and Elasticsearch should be carefully compared if a problem appears to need a large distributed solution.
\n\n