Category: Solr
Over the past few years as Ive worked with search, and Solr in particular, I have witnessed a commonly recurring problem associated with multiple objective search and how documents are scored. Perhaps the best way to understand this problem is to look at an example:
Lets say that you are Zappos and you sell apparel online. When your users search for “green shoes”, you want to display green shoes, but you also want to promote the newest product first. So you set up your Solr request handler like so:
http://www.zappos.com/solr/select?green shoes &defType=dismax &qf=product_description &pf=product_description &bf=recip(ms(NOW,product_date),3.16e-11,1,1)In this case part of the score is based upon how well “green shoes” matches in the product description, and (thought its a bit cryptic) part of the score is based upon how new the product is. These two score components are summed together to form the final score. Or in equation format, for a given product,
(total score for product) = (how well product matches the search) + (newness of product)
Now that search has been appropriately configured, you issue the search for “green shoes” and to your chagrin, you find that instead of green shoes, you have a mixture of a bunch of really new products that happen to be either green or shoes, but rarely both at the same time. This stinks, because you know there are plenty of green shoes in the index, but theres just not any recent products!
Well no problem, you can just change the weight the text match so that its more important than the newness of the product:
http://www.zappos.com/solr/select?green shoes &defType=dismax &qf=product_description^10 &pf=product_description^10 &bf=recip(ms(NOW,product_date),3.16e-11,1,1)Or again in equation form:
(total score for product) = 10* (how well product matches the search) + (newness of product)
And upon issuing the search again, you see a lineup of the newest green shoes you have to offer.
Problem solved! Right?
Not so fast. Do a search for “dress shoes”. To your surprise youll find, not dress shoes, but a collection of recently introduced sun dressed and tennis shoes! What on earth happened?!
Here is what happened: Dresses and dress shoes are much more common in the index than “green shoes”, and because they are so much more common, they get a lower score! (See TF-IDF scoring for more information.) Because “dress shoes” are weighted so much lower, the relative importance of newness is increased and you get this mess were talking about here.
From this point its not difficult to see that there is no best setting. For instance, if we again increase the weight on text match, then in all likelihood we would match too heavily on the text “green shoes”, ignore the newness, the results would now contain only the oldest, most out-of-style green shoes in our inventory!
A visual interpretation
Perhaps youre like me. I always feel a lot better when Im looking at a visual interpretation of new concept. So here is a good visual way of thinking about the problem above.
Considering the “green shoes” search, every product in the inventory has a certain score for the text match and a certain score for the newness as seen here.

But based on these two scoring dimension, theres no real obvious order for displaying these products? So we do the best thing that we can think of, and we sum the scores together and turn them into one score. This can be represented as a 45˚ line on the diagram. And the further along this line the product is, the higher its total score.
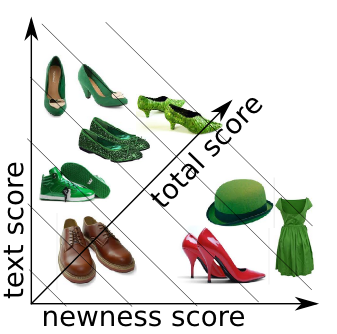
But as illustrated here, there are far too many high-scoring items that are not “green shoes” – theyre just newer. So we boost the text score – effectively stretching their placement along the vertical axis. The more we do this, the more influential the text match becomes on the result ordering.

And, as we saw in the “dress shoes” example, our choice for the best text match weight for “green shoes” might not be appropriate at all for “dress shoes”.

Exploring Better Options
The most obvious way of dealing with multiple objective search is to simply sum the individual scores together. However weve proven above that the best thing you can do for this approach is to optimize for a single search and then hope that the rest of searches arent too bad. Theres got to be something better. In the following sections Ill discuss two ideas that weve recently been exploring.
Auto-Scaled Weights
Perhaps you know that one of the objectives is more important and that the other objectives should be secondary. For instance, in both of the examples above, the text matching is primary. If a customer searches for “green shoes” then by golly they should show them green shoes, and only after that should we care about the newness of the green shoes. Ditto for “dress shoes”.
One way of achieving this is to have two pass scoring as follows. In the first pass, the text score and the newness score are handled individually and we collect statistics for both scores. For instance, it will probably be useful to track the maximum, average, and lowest score along both dimensions, along with the variance of those stores. Then, on the second scoring pass, we add the two scores together, but we give the newness component a weight based upon the statistics that weve captured for the other components of score:
(total score) = (text score) + (newness score weight)* (newness score)
There are certainly several ways to automatically determine the values for the secondary scoring weight. One example for now is to make the newness score weight equal the to the average text score divided by the average newness score. This way average contribution of the newness to the total score will be equal to the average contribution of the text score; the two components will be on equal footing.
The principle drawback here is that all matching documents have to be scored twice, however it might be possible mitigate this problem by smart use of caches.
Non-Dominated Results “Ordering”
A completely different approach would be to return results sorted so that so-called “non-dominated” results are shown first. Whats a non-dominated result? Consider a new example: Lets now imagine that we are CareerBuilder and our users use our search engine to find new jobs. A user is going to be interested in simultaneously optimizing several criteria. For now we consider two of these criteria: distance and salary. In a particular search, a user sees the following results scored according to both criteria:
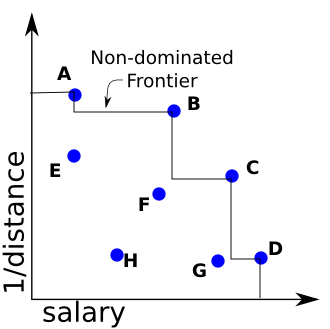
A “non-dominated” result is any result X for which there is no other result that is in every way better that X. The collection of all such non-dominated results is called the non-dominated frontier (or sometimes the Pareto frontier).
Now since weve defined what a non-dominated result is, it should be easier to understand why you would want to present your user with these results first. For example, why on earth would our user want to see result H before seeing results B or C which in both cases are both closer and provide a higher salary?
One of greatest reasons that a non-dominated ordering of results is beneficial is because we cant ask our users how strongly they weight salary vs. distance. For some users, they simply dont want to move and therefore salary is secondary to distance. For others, the oposite will be true. The great thing about a non-dominated ordering is that you dont have to ask, the user will only be presented with results that are not dominated in either dimension.
While this non-dominated ordering provides some great benefits, there are drawbacks as well. For one, its not a strict ordering. There are several items that are equally non-dominated (those on the non-dominated frontier). What order do we present these results to the user? Also, once weve exhausted the completely non-dominated results, how do we present the remaining results? Finally, calculating the non-dominated frontier is computationally much more complex that simply sorting the documents by some scalar score. This complexity, however, might be mitigated by making some approximations in our ordering of the results.
Implementing this in Solr
And all of this begs the question, “How do you actually build this in Solr?” The answer, for now at least, is that we dont quite know. We know the component that does the scoring; its called the Similarity. And we know the component that searches the index; its called the IndexSearcher. And we even know the thing that collects all of the documents from the searcher; its called TopDocs. But we dont know if all of the necessary requirements above are met. (For instance, do document scores have to be scalars?) – But what I do know is that our clients need this type of search. And the sooner the better!
If you are such a client, then tell us! The more people that are mutually benefitted by this, the better and the faster well get this implemented! Are you a developer? Were fun to hack with. If youre interested, help us build this!