Category: Uncategorized
Recently, I spoke at NoSQL Matters in Barcelona about database history. As somebody with a history background, I was pretty excited to dig into the past, beyond the hype and marketing fluff, and look specifically at what technical problems each generation of database solved and where they in-turn fell short.
However, I got stuck at one moment in time I found utterly fascinating: the original development of relational databases. So much of the NoSQL movement feels like a rebellion against the “old timey” feeling relational databases. So I thought it would be fascinating to be a contrarian, to dig into what value relational databases have added to the world. Something everyone thinks is obvious but nobody really understands.
It’s very easy and popular to criticize relational databases. What folks don’t seem to do is go back and appreciate how revolutionary relational databases were when they came out. We forget what problems they solved. We forget how earlier databases fell short, and how relational databases solved the problems of the first generation of databases. In short, relational databases were the noSomething, and I aimed to find out what that something was.
And from that apply those lessons to todays NoSQL databases. Are todays databases repeating mistakes of the past? Or are they filling an important niche (or both?).
The First Databases
To appreciate how revolutionary the relational model is, we need to appreciate what the earliest, pre-relational databases looked like. These databases largely reflect what we would build if we were tasked by our boss to “build a database”. Maybe, if we’re tracking movie rentals, in our ignorance we might start out with a line-by-line csv listing of customers and what movies they’ve rented. Maybe something silly that looks like this:

Poor Mans Database
We might also add an “index” to the back of the file to help us find specific records, in the same way we’d use an index in a book. Here the index is telling us that the “doug” record is 512 characters into the file while the “rick” record is 9212 characters into the file.
Now the earliest designers of these data storage systems would have had to face the problem, “How do I store movies as their own record?”. For example, we’re going to need to start storing how much a movie costs to rent and how many we have in stock. Should movies like “Top Gun” be treated as top-level records? Or should they be as parts-of (something owned by) the user records we already have? With movies as their own records, we don’t have to duplicate all the inventory and price data everywhere, but we’ll need to create another construct (an additional record type?) to specify the relationship.
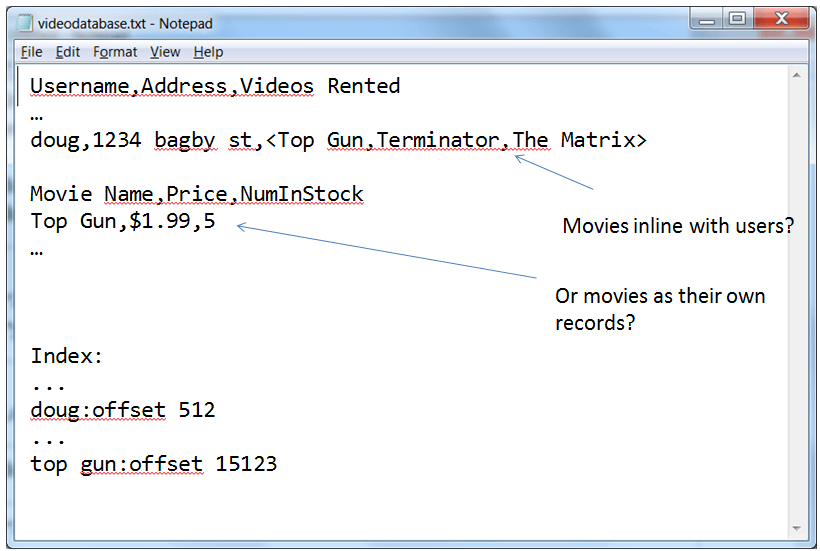
Poor Mans Database
The databases that aggregate videos into users are considered to be following the “hierarchical” model. The databases that break out movies into their own records with the ability to link records fall into the “navigational” model.
You can imagine, if we were interacting with this database, our first reaction would be to create a rather primitive interface – create something low-level that talked only in movies and users. Luckily, others saw past this and realized that patterns like the ones in our video rental and other data stores could be generalized–that we could abstract the notion of “record” and “ownership” into something much more powerful. Eventually this is exactly what Codasyl/DBTG (Database Task Group) did, creating a standard language for creating and interacting with navigational and hierarchical databases.
So reflecting on our data model, you could create a record in one of these databases by using the RECORD command:
Record Name is USER Location Mode is Calc Using username Duplicates are not allowed username Type character 25 address Type character 50 phonenumber Type character 10And when we want to declare a relationship between two records, we can define a set that maps them in an owner-ownee relationship.
Set Name is USER-VIDEOS Order is Next Retention is Mandatory Owner is USER Member is VIDEOThis model reflects first building many databases and then attempting to generalize important abstractions. We can think of the early history of databases like our video rental example. Since the advent of storage media, folks needed to store all kinds of data. Eventually somebody did something laudable, reflected on all the patterns being used in data storage and management and created a generalized database that was codified in the DBTG language.
Enter Codd
Whereas the first database’s abstractions grew out of patterns learned building from the bottom-up, the relational model did just the opposite. The relational model creates an amazingly powerful abstraction rooted in predicate calculus, and then expects the implementation details to follow (which as we all know they did).
When Codd wrote his paper, he criticized the DBTG databases of the day around the area of how the application interacted with the databases abstractions. Low-level abstractions leaked into user applications. Application logic became dependent on aspects of the databases: Specifically, he cites three criticisms:
- Access Dependencies: We often need to navigate from users -> videos to get at the videos. Application logic depends on how records are linked or aggregated. I must use one record type to get another record type.
- Order Dependencies: Applications depend on how data is physically stored in the database. Notice the “ORDER is NEXT” line in the Set declaration above. This specifies storage based on insert order, so retrieval will in turn happen on index order.
- Index Dependencies: When accessing indices, these databases required database indices be referred to explicitly by name.
Codd proposed to get around these limitations by focusing on a specific abstraction: relations. A relation is simply a tuple of elements. The ith element of each tuple is a member of some set, known as that element’s domain. Perhaps a given element’s domain is the set of users, user ids, possible movies to rent, etc. So for our videos, a tuple might look like:
(user=u, address=a, list of movies rented=l)Or in other words
(doug, 1234 Bagby St, [Top Gun 3.99, Terminator 12.99])One can interpret this relation to “mean” any number of things. We might equate this to a statement that “Doug rents Top Gun at 3.99 and Terminator at 12.99” or “Doug lives at 1234 Bagby St”.
Adding to this, Codd proposes an idea known as normalization. Codd only touches on the basics of normalization in this first paper. Suffice it to say, one important goal of normalization is to create flatter and less-redundant relations, creating simpler sentences from our relations. In Codd’s first-order normalization, what he introduces in his paper, we’d rather say “Doug rents Top Gun at 3.99” and “Doug rents Terminator at 12.99” instead of including both movies in the sentence. In relation terms, this would look like:
Users Relations(user=doug, address=1234 BagbySt)Movies-Rented Relations(user=doug, movie=Top Gun, price=3.99)(user=doug, movie=Terminator, price=12.99)With simpler and normalized relations, we can use Codds new JOIN operator that can derive relations from other, simpler and normalized relations. This is extremely powerful. In other words with JOIN we can construct knowledge from smaller units of knowledge. For example, what if our database contained these relations:
Peoples Relations(name=Socrates, Occupation=Philosopher)Occupation-Characteristic Relations(Occupation=Philosopher, Characteristics=Drunk)We can do a JOIN on Occupation=Philosopher and learn that Socrates was a drunk! This is neat because, in my Artificial Intelligence class in college, this kind of “reasoning” is presented as something advanced. In fact there’s a whole language, Prolog, that’s whole job is to take assertions about the world and give you extra facts. I had to learn all that stuff in AI when mundane-old SQL was right under my nose giving me the tools to learn anything I want about the world my relations represented!
So now that we’ve presented this model, let’s reflect on how it matches up against Codd’s criticisms:
- Access Dependencies: As relations, data is split out into independent relations. There’s no “links” between them to follow.
- Order Dependencies: The order of a set of relations is not specified. Sets in math don’t have a notion of order. In practice, a relational query language, like SQL, allows you to sort by whatever criteria you want
- Index Dependencies: What’s an index? This data model does not mention indices. Indices are, for better-or-worse, a knob that gets tuned at a place the application does not interact with the database.
In short, Codd created a beautiful abstraction that turned out to be reasonable to implement. Instead of building on what had been done with databases, he went to the roots of predicate calculus and created a clean and beautiful way of interacting with data.
It’s a pretty singular and daring achievement in fact to assert “this is the abstraction we should use” and have it be largely successful. There was not much anticipating Codd’s invention of relational databases. It wasn’t, as is common today, a minor innovation on previous innovations. Instead it was simply Codds vision. Pretty cool stuff!
The wrench-in-the-spokes of-course came when we decided to build horizontally scalable systems “webscale” as all the kiddies say. Doing a JOIN over a distributed system turns out not to scale well. Because of this, we started to see old themes reintroduced, specifically the denormalized, hierarchical databases of yore in the form of many of today’s NoSQL stores.
NoSQL – Have we come full circle?
Yeah… in a way we’ve come full circle back to pre SQL days. Hierarchical data stores, once forgotten, have risen again. They certainly suffer from the same kinds of criticisms that Codd lays out. They leak lower-level details, access dependencies, order dependencies, and index dependencies up to the user application. Using Cassandra databases requires holding in high respect the primary row key, using that-and-only-that to access data. These are index and access dependencies. A database like HBase will impose order dependencies, storing your rows sorted based on the row key, allowing/requiring you to consider the order when your application scans keys.
Most importantly, when using a NoSQL store, your opportunities for ad-hoc querying becomes much more limited. Whereas relational databases hold sacred the goal of allowing you to define more complex information from more primitive information, NoSQL databases require performing massive batch processing through map-reduce to create derived information.
Moreover, the lack of normalization requires potentially large amounts of data duplication. If tracking users renting videos in a hierarchical data store, how does one update the inventory successfully? If users own videos, does this require a map reduce job to visit every user record and update the count. Will this occur atomically across all the records?
In short, denormalization stinks!
Ok Eeeyore

Databases are hard
But denormalization is extremely powerful.
When we can denormalize we can do amazing things with horizontal scalability. We can simplify the task of atomically moving data around boxes. We can avoid having to worry about difficult distributed joins (all the data is in one place). Databases like Cassandra can be built that do beautiful things with distributed systems.
My point is that it’s dangerous to just grab a database off the shelf because its fun and trendy. You might end up creating a lot of technical debt for yourself. Do you know you’re handling an extremely high volume of a single somewhat-well-defined “thing”? Then the hierarchical model might be an amazing bet for you. Do you have many different kinds of records that link together, but don’t necessarily contain parts of the whole? A relational data store might be the ideal solution.
With Quepid, I started out using Redis as the primary database. Its been amazing for doing some simple storage of search query/document ratings. Once we started needing to add user accounts. With user accounts relating to sets of search problems, it became clear that Redis wasn’t good at this. My code started to look like a pseudo-relational database on top of Redis. So I’ve been working now (not a year from now) to transition to FoundationDB. FoundationDB will be great for my problem because I can mix-match different kinds of models in a single database, storing both hierarchical ratings for documents, and relational users.
In conclusion, “a foolish consistency is a hobgoblin of little minds”. Its important as a data architect to understand these tradeoffs in your bones. Its easy to get lost in hype and marketing material, but really appreciate what you’re gaining and measure if that gain is worth the potentially very real and painful cost.
Do you need help choosing the right data store for your application? Contact us!. We can help you! Do you have feedback for this article? I’d love to hear what you have to say or critique and learn more about database history! So please leave a comment.