Category: Uncategorized
When a Solr schema changes, us Solr devs know whats next – a large reindex of all of our data to capture any changes to index-time analysis. When we deliver solutions to our customers, we frequently need to build this in as a feature. Many cases, we cant easily access the source system to reindex. Perhaps the original data is not easily available, having taken a circuitous route through the Sahara to get to Solr. Perhaps the sys admins dont want us to run a nasty SQL query with 15 joins to pull in all the data.
How does your data flow into Solr?
In these cases, we might save docs in an easy-to-digest, already denormalized form, perhaps in the form of solr XML or JSON files on disk, so that we can kick off a reindex job by simply replaying these prebuilt documents through Solr. It mostly works. Of course now weve got new problems. Now were maintaining and keeping in sync a large set of pre-chewed data in a third scratch space.
So why not just use Solr as a source for its own data? We could, for example store all of our fields, then upon a need to reindex: (1) create a new collection with the new schema & configuration (2) read data from the original Solr collection and one-by-one (3) write the read data to the new collection. Once done, we could blow away the old collection, and viola everything is in place!
Step (1) is fairly straightforward, a matter of using the collections API or modifying solr.xml to suit our needs. Step (3) is just a matter of a simple translation from whats read to Solr back to what we write to Solr.
The “Deep Paging” Problem
What about step(2)? Well Solr has “start” and “rows” params, cant we just set rows=100 and increment start by 100 everytime to page through all the documents? Successive queries of q=:&start=0&rows=100 then q=:&start=100&rows=100 etc?
Turns out Solr has typically been very slow at scanning through a set of search results. Solr gets progressively slower as you go deeper and deeper into the search results. How slow? Well I have numbers to show you! Writing my own tests (comparable to hossman’s in his blog post) show for a fairly small data set (70,000 documents) just pulling back just the id field. Pulling back 100 fields at a time, we see a gradual degradation of each subsequent query to pull back the next set of documents. As we get farther down the result set, we plateau around 200ms per query. This quickly adds up – the whole process takes about 120 seconds.
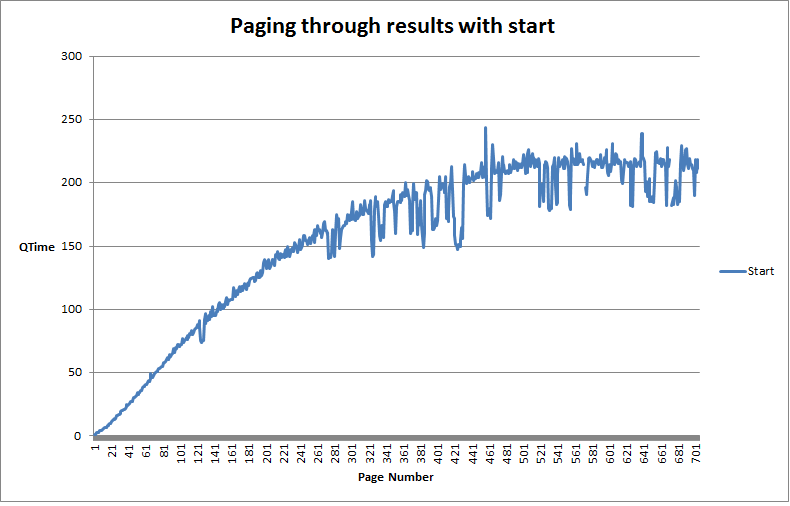
Deep Paging Problem: using start, each progressive page retrieval gets progressively worse
Why does this happen? Search engines are built around the idea of sorting on a relevancy score. Its based on the assumption that you’ll likely only care about the ten or so most relevant results. The underlying data structures therefore are built to keep track of some top N documents. When the data structure fills up, we can safely discard anything that can’t compete with what’s already in the top N. A runner that finishes a marathon in 3 hours, clearly isn’t going to be in the top 10 if the current top 10 finisher finished in 1hour 30 minutes.
Digging one step deeper, as Solr (really Lucene) iterates through matching documents for a query, they get scored. These docs get picked up they get collected by a Lucene class knows as a “Collector”. What is Collector’s job? Its job is to store the match for later (or perhaps throw it away) based on the kind of query the user is executing.
With searches where relevancy is the primary sort value, a TopDocsCollector collects matching documents. TopDocsCollector uses a priority queue. The queue is sized based on how many results need to be evaluated. In the case of a Solr query of rows=100 and start=10000, this means 10100 documents need to be collected before a definitive judgement on what are the ranked 10000-10100 documents. Imagine a marathon with 11000 participants. We can’t tell you who placed 10,000th without knowing something about the first 9,999 racers.
Giving Lucene Hints
However, we can make a huge improvement if we know the time of the 9,999th racer. We can scan over the times of all the racers and quickly determine whether racers beat the 9,999th racer and decide to ignore those. We don’t need to store them or anything, we can safely discard the fastest runners. Lucene exposes this strategy in IndexSearcher’s searchAfter method that lets you provide an “after” value to the IndexSearcher.
This value (one of the search documents produced by a previous query) gives Lucene the “value” of the 9999th document (or time of the 9999th racer). The after value might wrap a score of actual field value (in the case of sorting on a field) that can help Lucene pick up where it left off. When searching, Lucene does what it usually does – iterating through docs that match query, scoring them, and then forwarding them to a collector. In this case, Lucene forwards to a paging collector. This collector is the smarts that knows to throw away the 1-9999th runners (this runner is faster than this 9999th runner I know about, throw them away!). By looking at the after doc it has access to, this collector can more intelligently save the data it needs to save (the 10000-10100th runners).
This strategy means we only store 100 documents. Not 10100 like we would in a typical search. Just like that we can more quickly page through search results!
So how would we take advantage of this functionality in Solr? Well there’s no obvious after parameter to send Solr that says “look I’ve already seen runners that finished before time X, just give me the next 100”. Or in other words “heres where I left off in the search results, you can safely ignore anything that compares before this marker”.
Solr Cursors
Well actually, now there is! Solr’s new cursor support effectively emulates Lucene’s after parameter when searching. How does this work? After every search, Solr serializes out a marker back to the client in the response. This marker may take the form of encoding a score, or it might represent a pointer to a place in the part of Lucene’s FieldCache that presorts fields for segments. When Solr gets this marker again (in the form of cursorMark) it can use Lucene’s field cache to reconstruct the after document. This marker is sent back on subsequent requests instead of a “start” parameter to help Solr pickup where it left off.
(I’m not going to cover the exact details on how to use this, but if you’re interested hossman’s original blog article as well as the Solr Reference Guide’s page on cursors are great resources.)
You can see the performance improvements here. Paging through 70,000 results takes about 12 seconds total (compared to about ten times as long for non-cursor). An interesting note is that with more documents, the difference gets relatively much larger. Theres not a linear relationship between these times. Cursor time is not always ten times better than using start. With very large document sets, the factor between the two is much much larger. At small sets of documents in my testing (< 10K) the difference between using start and the cursor feature were negligible.
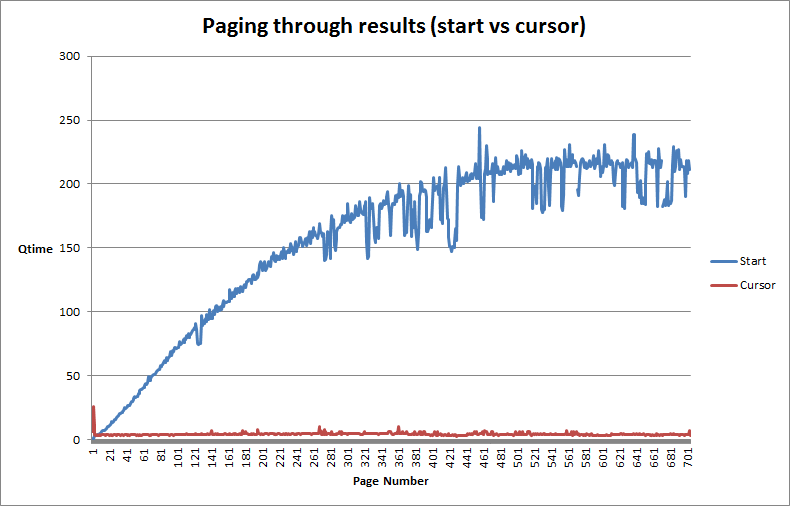
Cursor maintains a steady QTime during paging while start gets progressively worse
Nice! So the new cursor support helps us tremendously with iterating through the documents. Instead of an extremely inefficient process of building up a giant priority queue every time during our reindex, we can only collect what we need to on each step. Its certainly a grep step in the right direction to help us not need an extra bit of storage to save off documents for reindexing.
Other Parts of the Problem
The new cursor support solves a large part of the problem of reindexing from Solr back to Solr. However, its not a panacea for solving reindexing. I still have a lot of reservations to this approach:
- Your search infrastructure needs to be able to support an index size twice the current index size
- Your search infrastructure can handle the load of iterating through every result
I also have some other open questions to this sort of solution:
- How much extra does it cost for Solr to dump out lots of fields and large fields? Here we’re only outputting “id”, so its not entirely reasonable. I have done this with more than id, but would love to get a handle on performance as a function of number and size of fields being reindex?
- How much faster would the javabin codec be then using XML or JSON? I suspect somewhat faster, but how much exactly?
- How does performance of Solr paging compare to other database solutions? Are those databases more stateful in their paging strategies. Solr/Lucene still iterates and attempts to score every document, even if it discards most of them, perhaps there’s a better strategy?
- When cursors miss updates, the new documents may get sorted before the current cursor and we may miss them. Perhaps this isn’t the best solution for rapidly updating indexes. Or perhaps we need to flag documents as they’re updated? Or maybe we could maintain a bloom filter of doc ids that could give us hints as to whether or not docs have been reindexed?
- How would we cope with copyFields? We may retrieve them in the result, but we wouldnt want to write them back. Wed have to be sure to only store non copyField fields.
- How does performance/usability compare to Elasticsearchs scan and scroll features.
And it also causes me to think of some other possibilities that might be further improvements:
- Would it be possible to build a Solr component that could read from one collection and write to another – thus avoiding the network traffic?
- Could we achieve the same thing by forcing an atomic update of a document? Perhaps by simply updating a counter in the document, it would trigger the read-modify-write behavior in an atomic update and force the document to be reindexed?
Final Thoughts
Still, for reasonably sized and fairly static data sets, this solution seems to work fairly well. We’ve had a couple occasions outside of reindexing where enumerating the whole index is necessary. One area that comes to mind is our use of term vectors in our semantic indexing work. For a lot of advanced machine learning work, you want to get all the term vectors of every Solr document. This traditionally involved paging through every document. Maybe cursors can make this more efficient and allow you to use external tools like Mahout in a more real-time capacity? Another blog post perhaps 🙂
Do you have any thoughts on reindexing? Have you used the new cursor support – what do you think? Are you someone struggling on how to connect your data infrastructure to search in your backend? If so, contact us, we may be able to help!