Category: Learning-to-rank
As an engineer, artificial intelligence (AI) is cool. Spaceships and science fiction cool. There has been a lot of attention around machine learning and artificial intelligence lately. Some of the largest companies in IT such as IBM and Intel have built whole advertising campaigns around advances that are making these research fields practical. How much of this is still cool and fiction? Can these advances can reasonably be used to enhance our applications, right now?
Learning to rank ties machine learning into the search engine, and it is neither magic nor fiction. It is at the forefront of a flood of new, smaller use cases that allow an off-the-shelf library implementation to capture user expectations.
What is relevancy engineering?
Search and discovery is well-suited to machine learning techniques. Relevancy engineering is the process of identifying the most important features of document set to the users of those documents, and using those features to tune the search engine to return the best fit documents to each user on each search. To recap how a search engine works: at index time documents are parsed into tokens; these tokens are then inserted to an index as seen in the figure below.
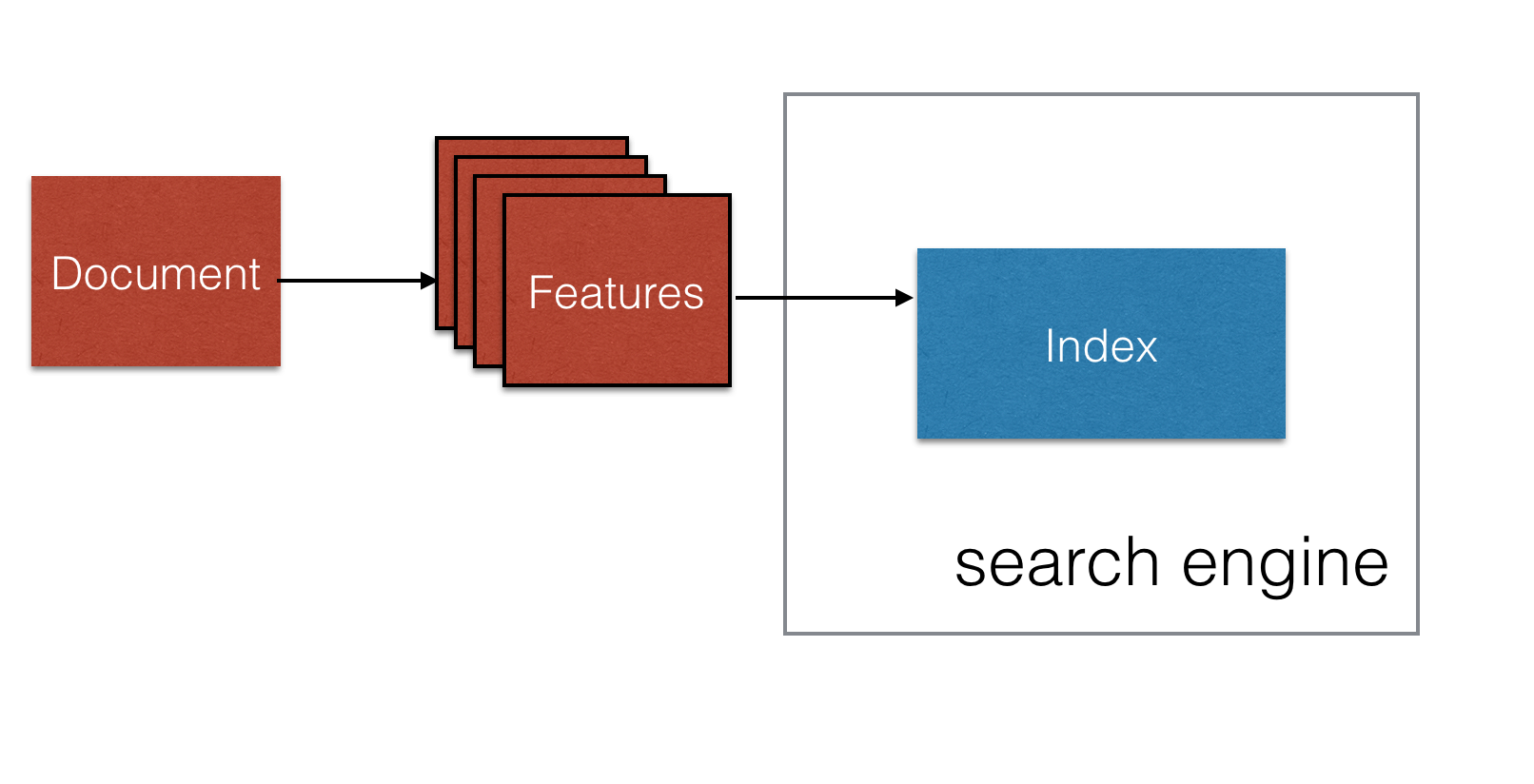
At search time, individual queries are also parsed into tokens. The search engine then looks up the tokens from the query in the inverted index, ranks the matching documents, retrieves the text associated with those documents, and returns the ranked results to the user as shown below.
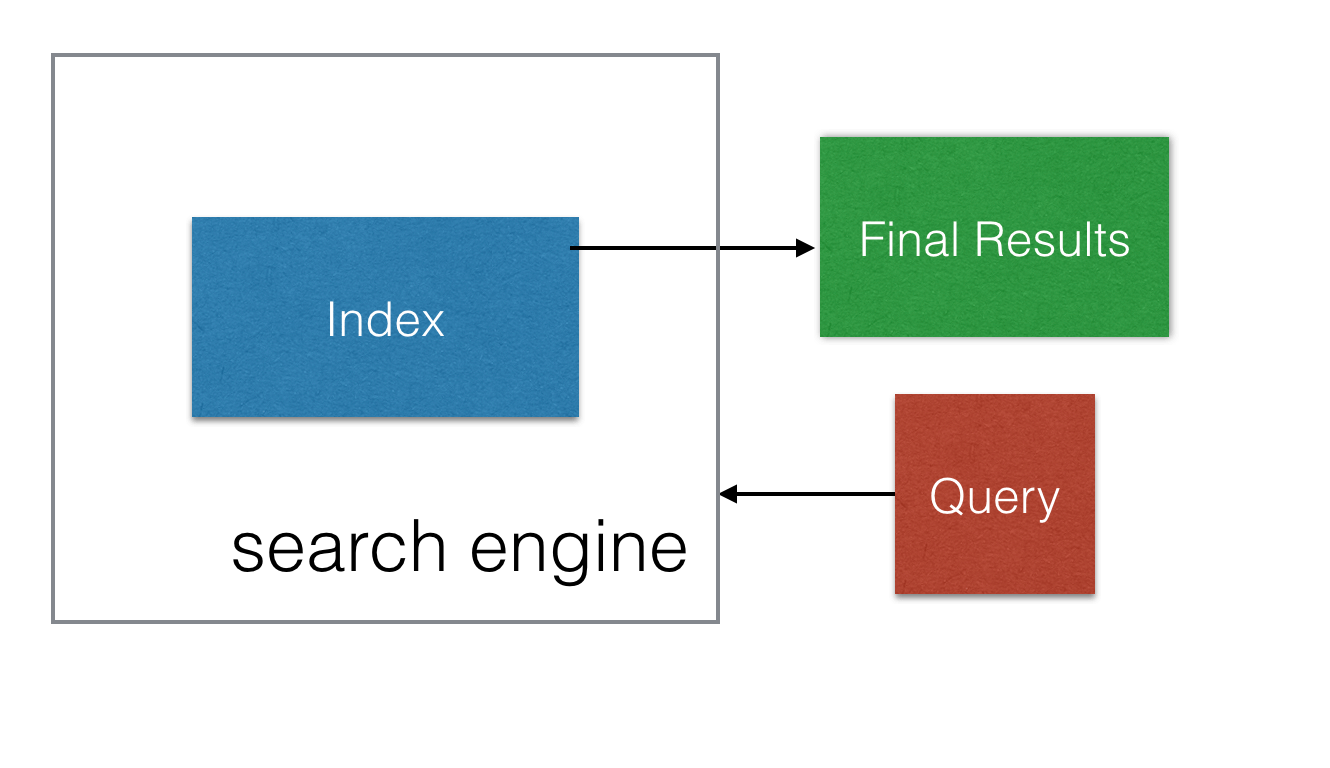
Identifying the best features based on text tokens is a fundamentally hard problem. Whole books and PhDs have been written on solving it. (Shameless plug for our book Relevant Search!) Consider a sales catalog:
| ID | Title | Price |
|---|---|---|
| 1 | Blue shoes | $10 |
| 2 | Dress shoes | $15 |
| 3 | Blue dress | $20 |
| 4 | Red dress | $40 |
As a human, we intuitively know that in document 2, ‘dress’ is an adjective describing the shoes, while in documents 3 and 4, ‘dress’ is the noun, the item in the catalog. As a relevancy engineer, we can construct a signal to guess whether users mean the adjective or noun when searching for ‘dress’. Even with careful crafting, text tokens are an imperfect representation of the nuances in content.
Where does learning to rank come in?
From the Wikipedia definition,
learning to rank or machine-learned ranking (MLR) applies machine learning to construct of ranking models for information retrieval systems. The most common implementation is as a re-ranking function.
This means rather than replacing the search engine with an machine learning model, we are extending the process with an additional step. After the query is issued to the index, the best results from that query are passed into the model, and re-ordered before being returned to the user, as seen in the figure below:
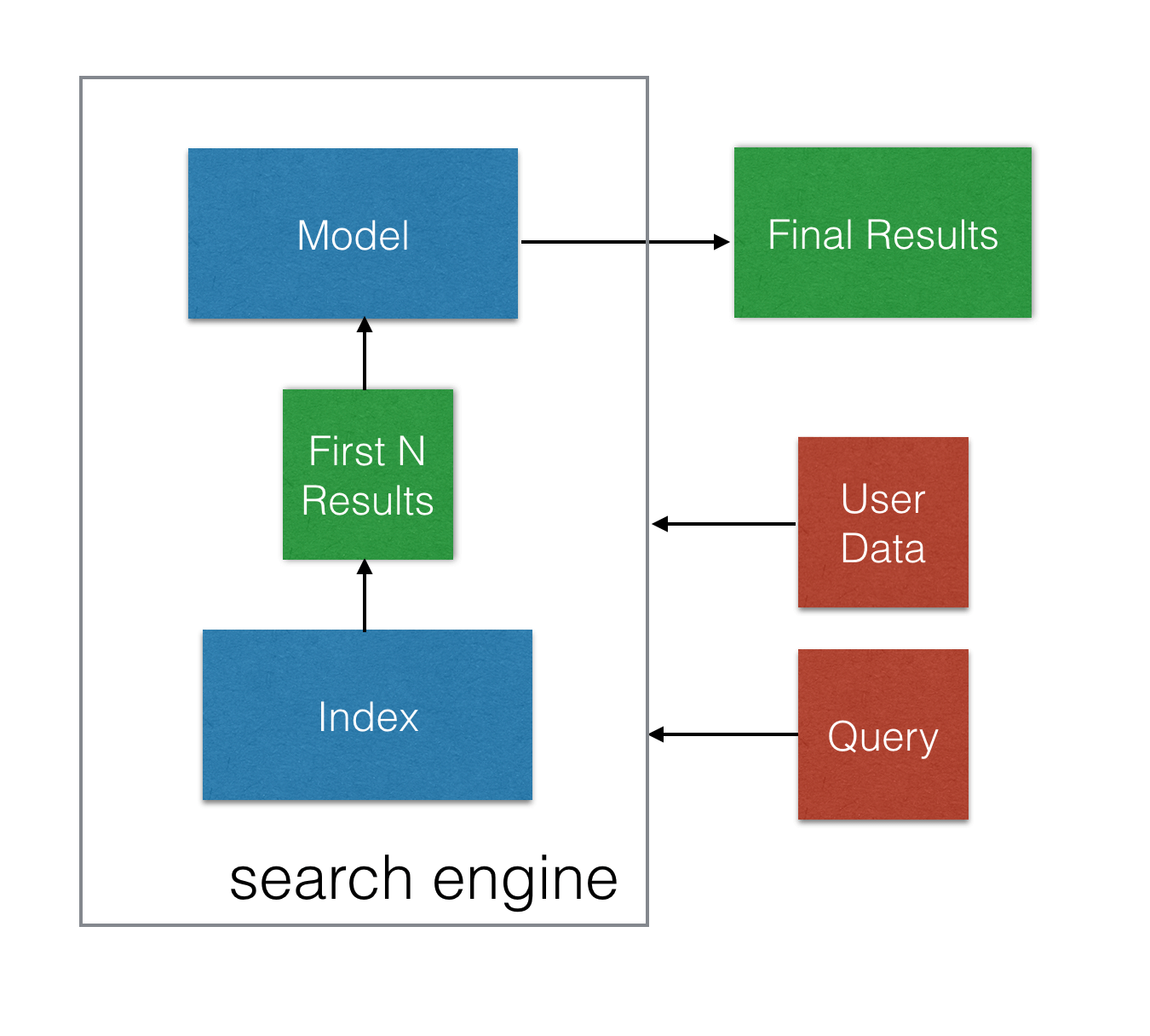
Why do this in two parts? Why not replace the whole search engine with the model?
Search engines are generally graded on two metrics: recall, or the percentage of relevant documents returned in the result set, and precision, the percentage of documents that are relevant. As a relevance engineer, constructing signals from documents to enable the search engine to return all the important results is usually less difficult than returning the best documents first. Intuitively, it is generally possible to improve recall by simply returning more documents. However, as a human user, if those better documents aren’t first in the list, they aren’t very helpful.
How does machine learning tie into this? Back to our Wikipedia definitions:
Machine learning is the subfield of computer science that gives computers the ability to learn without being explicitly programmed. Evolved from the study of pattern recognition and computational learning theory in artificial intelligence machine learning explores the study and construction of algorithms that can learn from and make predictions on data.
Machine learning isn’t magic, and it isn’t intelligence in the human understanding of the word. As a practical, engineering problem, we need to provide a set of training data: numerical scores of the numerical patterns we want our machine to learn. It turns out, constructing an accurate set of training data is not easy either, and for many real-world applications, constructing the training data is prohibitively expensive, even with improved algorithms. So if our search engine is pretty good at recall, then we don’t need to collect data and train our model on it. We just need to train the model on the order, or ranking of the documents within that result set.
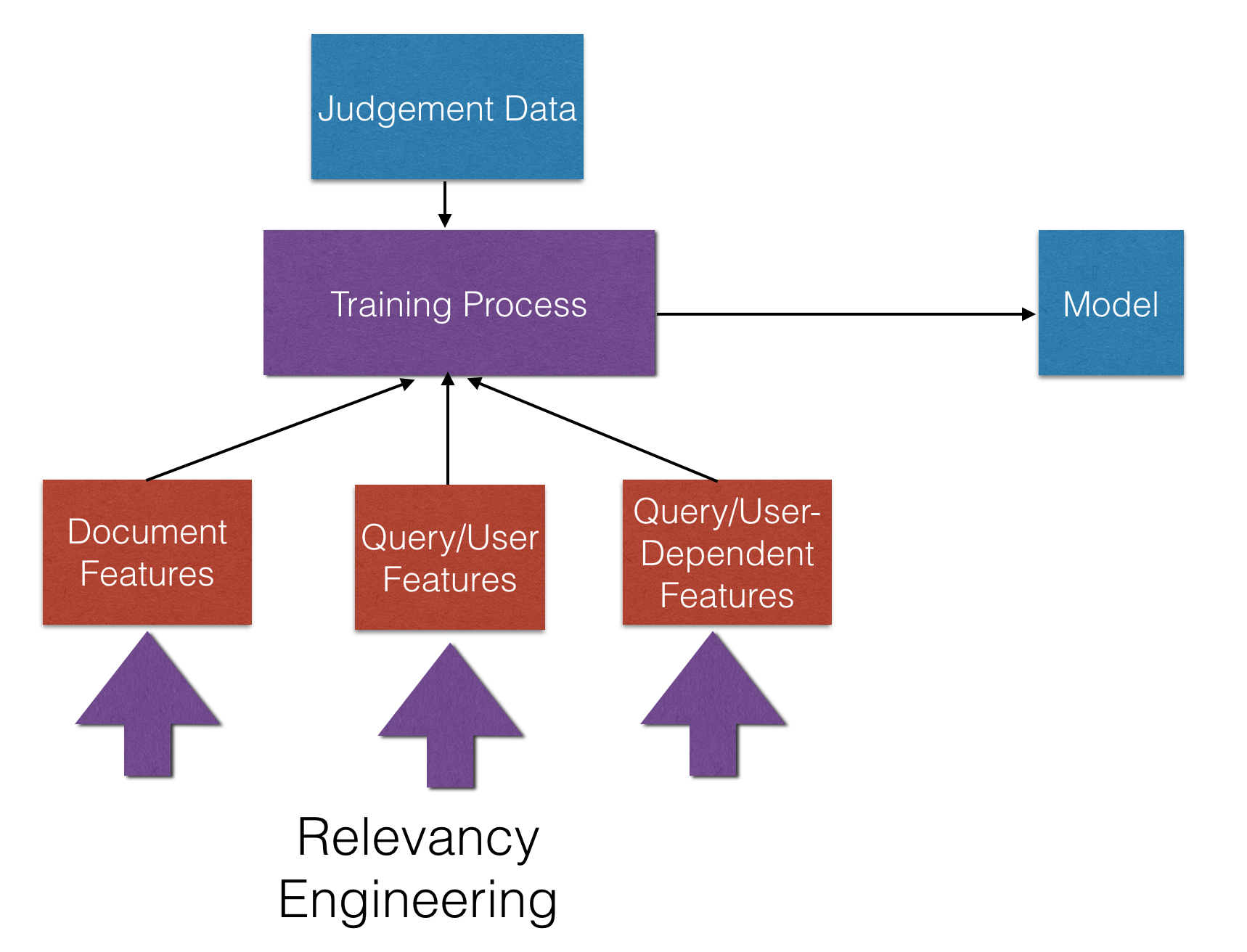
The other reason for narrowing the scope back to re-ranking is performance. Both building and evaluating models can be computationally expensive. Because the training model requires each feature be a numerical aspect of either the document or the relationship of the document to the user, it must be re-computed each time. Since users expect search results to return in seconds or milliseconds, re-ranking 1000 to 2000 documents at a time is less expensive than re-ranking tens of thousands or even millions of documents for each search.
What’s next in Learning to Rank?
This article is part of a sequence on Learning to Rank. If you are ready to try it out for yourself, try out our ElasticSearch LTR plugin! Watch for more articles in coming weeks on:
- Models: What are the prevalent models? What considerations play in selecting a model?
- Applications: Using learning to rank for search, recommendation systems, personalization and beyond
- Considerations: What technical and non-technical considerations come into play with Learning to Rank?
If you think you’d like to discuss how your search application can benefit from learning to rank, please get in touch. We’re also always on the hunt for collaborators or for more folks to beat up our work in real production systems. So give it a go and send us feedback! We also cover Learning to Rank in our training courses, introducing it Think Like a Relevance Engineer and covering it in detail in the more advanced Hello LTR.