Category: Relevancy
We’ve focused most of our conversation about machine learning and search on Learning to Rank (LTR), but LTR isn’t the only machine learning tool in the Solr/Elasticsearch toolbox. LTR uses feedback to balance a variety of signals, and better signals are the key to more relevant search. Natural Language Processing (NLP) attempts to bring in smarter language models, to start moving from bare text tokens to tokens-with-meaning.
OpenNLP is a java-based toolkit for common natural language processing tasks – tokenization, tagging, chunking, and parsing, among other things. Since this is precisely the challenge the analysis chains in Solr or Elasticsearch must solve, it seems natural to incorporate the openNLP functionality into Solr. The idea isn’t actually brand-new. Lucene had an open issue since 2011 to integrate OpenNLP. This finally became mainstream with the Solr 7.3 release. Solr 7.3 also introduced a new update request processor to use the OpenNLP-based entity extraction and language detection.
Using the Solr OpenNLP Filters
There are a few key classes:
- OpenNLPTokenizerFactory, which tokenizes and marks sentence boundaries
- OpenNLPPOSFilterFactory, which rolls in part-of-speech tagging
- OpenNLPChunkerFilterFactory, which will replace the POS tags with a ‘phrase chunk’ label
Since Lucene does not yet index token types, in order to make that information available to queries, it is necessary to push the type either to a payload or as a synonym token using either TypeAsPayloadFilterFactory or TypeAsSynonymFilterFactory.
In order to effectively use the tools available, I like to understand what they are doing under the hood. So I’ve set up an instance of Solr 7.4, and indexed the TMDB movie data, using these tools, plus the following field snippet:
<fieldType name="text_opennlp" class="solr.TextField" positionIncrementGap="100" multiValued="true" >
<analyzer>
<tokenizer class="solr.OpenNLPTokenizerFactory"
sentenceModel="en-sent.bin"
tokenizerModel="en-token.bin"/>
<filter class="solr.OpenNLPPOSFilterFactory" posTaggerModel="en-pos-maxent.bin"/>
<filter class="solr.OpenNLPChunkerFilterFactory" chunkerModel="en-chunker.bin"/>
<filter class="solr.TypeAsPayloadFilterFactory"/>
</analyzer>
</fieldType>
<field type="text_opennlp" name="title_opennlp" multiValued="true" />
<field type="text_opennlp" name="overview_opennlp" multiValued="true" />
<copyfield source="title" dest="title_opennlp" />
<copyfield source="overview" dest="overview_opennlp" />The first thing to notice is that each of those classes uses a model, and the tokenizer uses two. Those models aren’t available from Solr; they must either be downloaded from the OpenNLP project or you need to build your own. Even then only the Language Detector (not used in the analysis chain above) is available on the download page linked in by the Solr documentation. I found some older models in (I think) the same format after some digging on the OpenNLP Page. They seem to be compatible for a toy problem, but it is a real concern for taking a system to production.
So what happens when we start indexing some content? Let’s look at “George Washingon meets the cat in the hat.” On first glance at the analysis page, not much changes, other than our sentence punctuation is preserved:
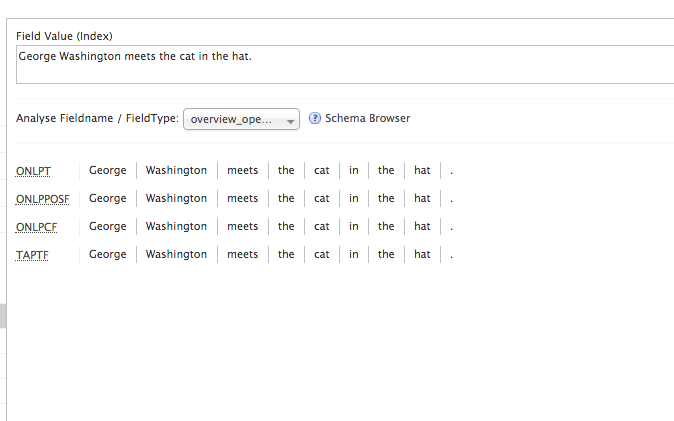
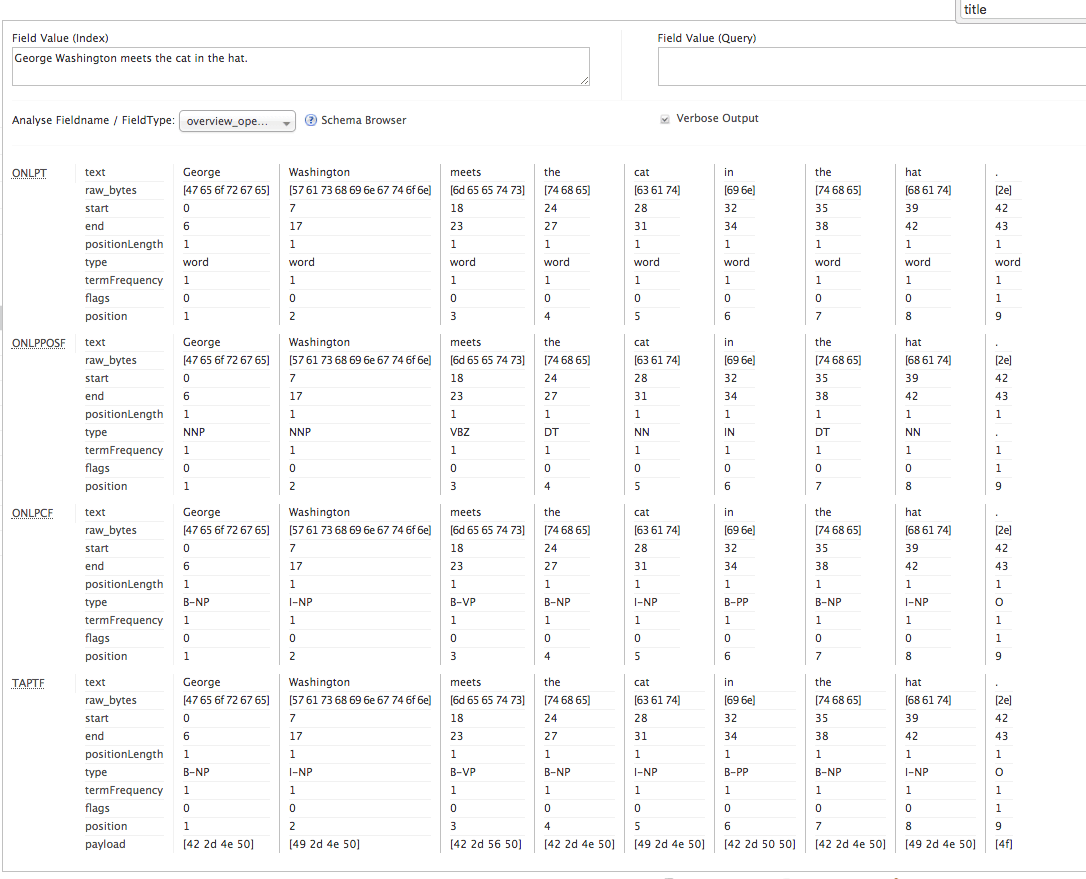
Try that again, with the verbose output:
Compare that to a text_general analysis:
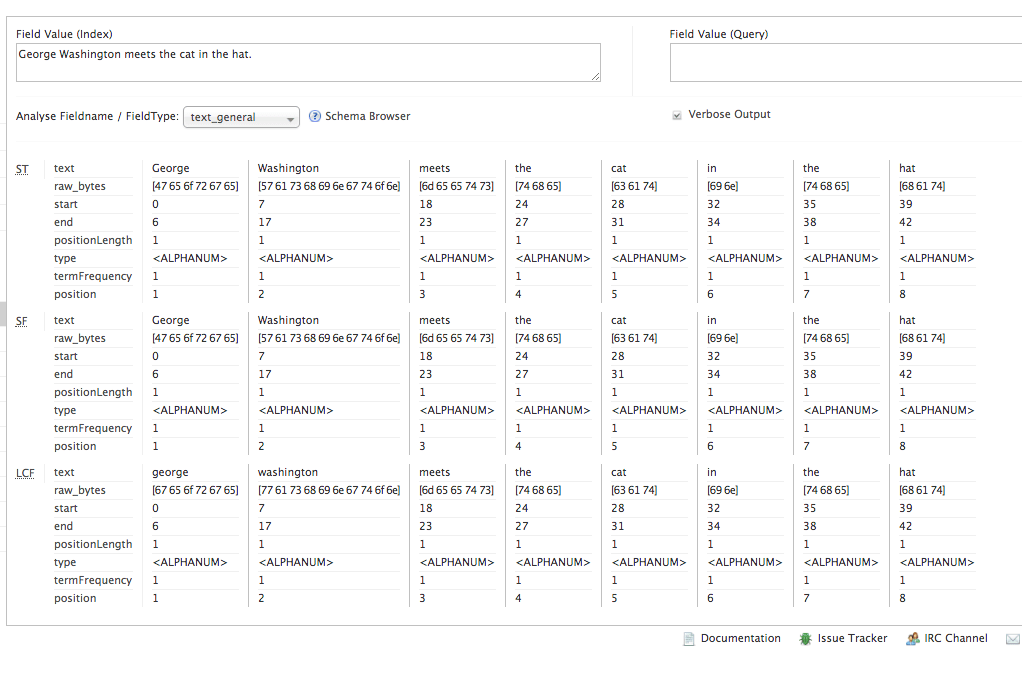
And the more interesting differences start to show up. The OpenNLP tokenizer has identified each token as a “word”, not an “”, and each token has been assigned a flag; these flags are blank for now, except that trailing “.”, which has been identified as a sentence boundary. The OpenNLPPosFilter has changed each of those “word” tags to a label denoting a more specific part of speach. OpenNLP uses the Penn Trebank POS labels. “George” and “Washington” have been identified as singular proper nouns; “meets” is a 3rd person singular present verb; and so on.
Chunking isn’t quite so intuitive. The idea behind chunking isn’t necessarily to identify phrases in the text in the sense that we would use in the context of multi-term synonyms or shingles. Chunking identifies a higher-level order in the sentence, but at a fixed content depth. A chunk tag consists of up to two parts: a prefix, indicating how the token relates to the chunk, and a suffix indicating the role of the chunk itself in the sentence. So in the above sentence, the first chunk, “George Washington” is a proper noun. “George”, the first token in this chunk, is tagged “B-NP”; “B”, indicating it is the first term in the chunk, “NP” indicating the chunk is a noun phrase. The second chunk “meets”, is only a single token long, so it is tagged with “B-VP”, indicating it is a verb, and there is no subsequent “I-VP” term. The trailing punctuation “.” is tagged “O” – outside a chunk. Finally, the TypeAsPayloadFilter moves that type string into the payload, so we can use it for subsequent queries.
Using POS tags in queries
Getting that data into the index is only the first step; using it to improve relevance signals is still a non-trivial amount of work. While Solr offers two payload query parsers, only the Payload Check query parser can handle string-based query parsers. This accepts a list of payload strings, and restricts matches to tokens having the appropriate payload. This would give some measure of disambiguation – Lucidworks example for how the query parser might be used gives the example of ‘train’ the noun vs. ‘train’ the verb. But in practice, generating that string of payloads to encompass all variations a noun phrase or verb phrase might will also require some engineering – there is no analysis on payload tokens.
OpenNLPExtractNamedEntitiesUpdateProcessor
Those payloads may not buy so much at query time, but it does lay the foundation field for Named Entity Extraction. Named Entity Recognition (NER) seeks to locate and classify particular kinds of things – usually the names of people or organizations, but what constitutes an interesting entity is pretty domain-specific. With Named Entity Extraction, when the model recognizes a particular kind of entity (like person names), then that entity can be copied out of the bulk text bag-of-words to a new field. Which is exactly what the OpenNLPExtractNamedEntitiesUpdateProcessorFactory does. This, in turn, opens up the door to a new level of dynamic classification and tagging. How much the models available from OpenNLP works out of the box for your entities depends on the problem domain. Mileage may vary, but looking for proper names mentioned in a large-ish chunk of text is pretty powerful. Extending that to recognize semi-proper names such as products or institutions becomes a much smaller problem.
What’s next?
If you would like to discuss how your search application can benefit from machine learning, please get in touch. We’re also always on the hunt for collaborators or for war stories from real production systems. So give it a go and send us feedback!