 Charlie Hull
Charlie Hull
Category: Relevancy
For the last few years I’ve run free Lucene Hackdays around the same time of year as the largest conference in our open source search sector, Activate (previously known as Lucene Revolution and run by Lucidworks). The idea is that if people are in town for a conference anyway, they might like to get together with other Lucene/Solr enthusiasts and work together on some problems. This year, as Activate was in Washington DC, OSC organised a hackday kindly hosted by the American Geophysical Union at their new (and highly eco-friendly!) new headquarters building. Around 20 people attended including several Lucene/Solr committers and four of us from the OSC team.
I’ve listed below some of what we worked on, with links to related JIRA issues and other supporting material. On the day we used Relevance Slack to communicate (check out the #lucene-hackday channel) – if you want more information this is the best place to ask. Thanks to everyone who came and hacked, it was a lot of fun! Note that we didn’t have time to work on everything but I’ve listed all the ideas anyway in case someone else is inspired to continue. Also, the following is based on my notes taken during the day and the shared GoogleDoc we used, so do please forgive any inaccuracies or mistakes.
Things we worked on
1. Andy Webb suggested two ideas:
a. add support for BooleanSimilarity to Solr, for situations when you don’t want document/term frequency to influence scores (ref LUCENE-5867): “I’ve raised SOLR-13751 which links to https://github.com/apache/lucene-solr/pull/867 – just running ant test now. It’d be great to get further feedback/comments on this – this is my first Solr PR!”
b. Solr admin UI tweaks such as alphabetical ordering of collections in the drop-down lists. Bob Bunch took this on: ”Here are a couple of patches (master branch; I’m not set up to contribute yet). This fixes:
- Collections page, order of collections
- Collections drop-list, order of collections
- Cores drop-list, order of cores“
diff --git a/solr/webapp/web/index.html b/solr/webapp/web/index.htmlindex 7fe1381763c..11157402269 100644--- a/solr/webapp/web/index.html+++ b/solr/webapp/web/index.html@@ -182,7 +182,7 @@ limitations under the License. ng-model="currentCollection" chosen ng-change="showCollection(currentCollection)"- ng-options="collection.name for collection in aliases_and_collections"
diff --git a/solr/webapp/web/partials/collections.html b/solr/webapp/web/partials/collections.htmlindex 198030c744f..8c9cebc81c7 100644--- a/solr/webapp/web/partials/collections.html+++ b/solr/webapp/web/partials/collections.html@@ -88,7 +88,7 @@ limitations under the License. diff --git a/solr/webapp/web/partials/cores.html b/solr/webapp/web/partials/cores.htmlindex 1615769564f..4dccc313449 100644--- a/solr/webapp/web/partials/cores.html+++ b/solr/webapp/web/partials/cores.html@@ -217,7 +217,7 @@ limitations under the License. 2. Bob Bunch also suggested:
a. To work more on monitoring JVM full garbage collects and shard/core status at scale. (we didn’t get around to this)
b. Exposure testing – we resolved a major bug in Gus’ nifty cloud.sh script – SOLR-11492. The -c option (in conjunction with a restart) caused a very bad scenario, even on *nix platforms! (Bob’s Macbook got so warm it started restarting itself and one of the USB ports stopped working for a while!)
3. Anshum Gupta suggested:
a. Drive forward Mark Millers’ Gradle effort (a huge project to change Lucene/Solr’s build system – Mark has put months of work into this and it promises to shorten build times considerably). A group of people worked on testing the Gradle build system to identify any issues and to become familiar with the new system.
b. SOLR-13527 (we didn’t get around to this)
c. Get GitHub to run ‘ant precommit’ as an action for all pull requests – SOLR-13753 – this has been committed to Github here.
4. Bertrand Rigaldies suggested:
Return the offset of snippets in Solr’s highlighter. A large team worked on this. We began with setting up a Highlighter formatter using the original highlighter in Solr. An example showing this approach is here.

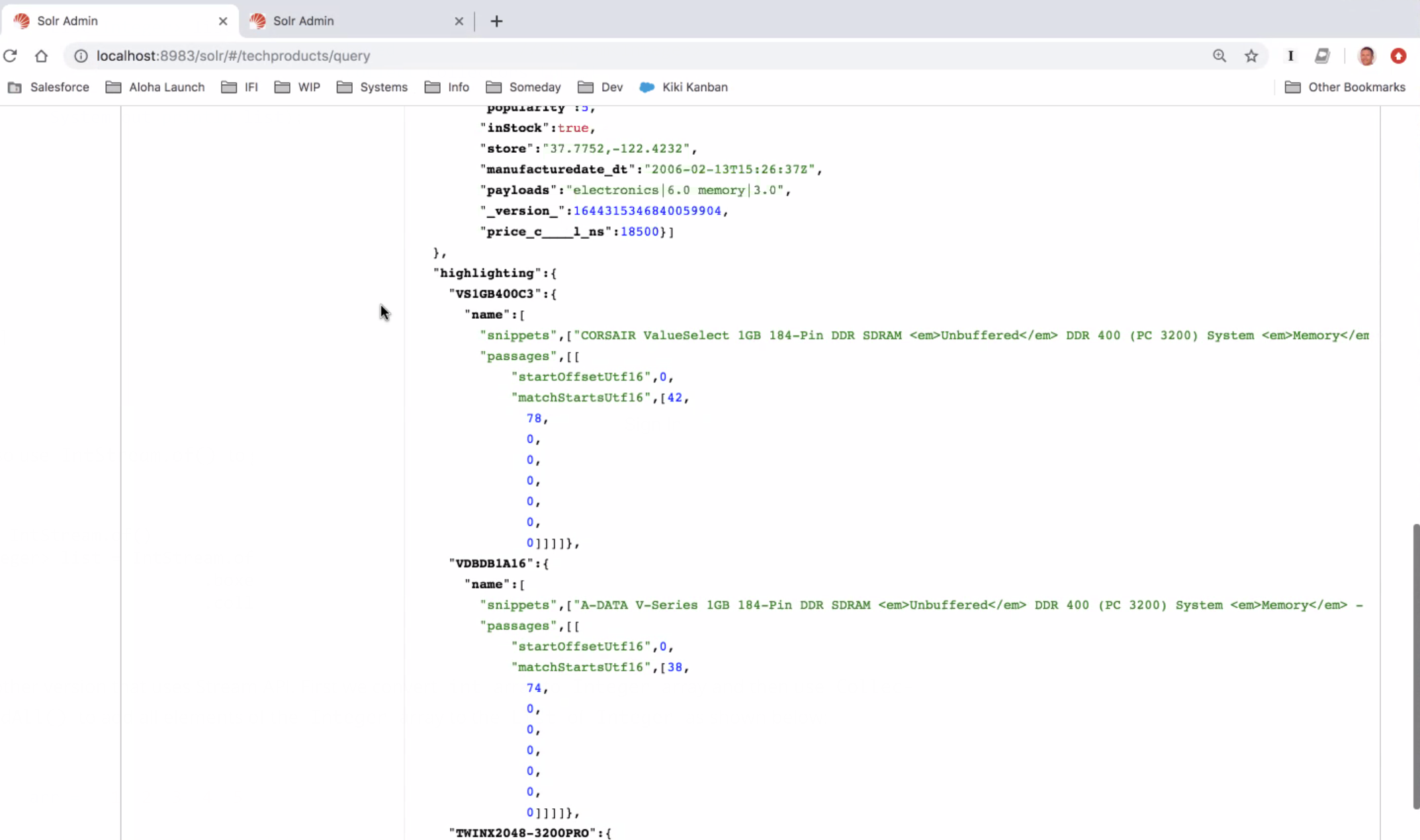
David Smiley began implementing an “extended” mode to the unified highlighter that offers similar functionality – SOLR-1954
The innovation in the “extended” unified highlighter that David prototyped was in returning the passages’ metadata out-of-band of, or in addition to, the formatted snippets (See screenshot below).
5. Eric Pugh and Peter Fries worked on upgrading the Clade taxonomy tool from Python2 to Python 3. (Clade was a project created by Flax to use Solr to classify data into a taxonomy).
6. Joe Ye worked on the Marple index inspector tool to allow it to read older versions of Lucene indexes. Joe had worked on this at a previous Hackday but had lost all his work when his laptop was subsequently stolen!
Things we didn’t get a chance to work on
The following suggestions were made but we didn’t have time to look at them. If you have a particular interest in an issue, or can help, you could either contribute to the JIRA ticket or perhaps contact the author directly via Relevance Slack.
7. Andy Hind suggested:
a. A fix for MLT using corpus size – SOLR-13752
b. Identify known vulnerabilities in dependencies while building Solr using Gradle.
8. Gus Heck suggested: Hardcoded timeouts – SOLR-13457
9. Michael Gibney suggested: Facet caching/singlePass multi-domain facet collection (relatedness) – SOLR-13132
10. Shyamsunder Mutcha suggested: JSON Facet API Java objects – “I don’t see a feature to write JSON facet queries as Query objects.”
Summary
As usual, we had considerably more ideas than time but everyone worked hard on what we selected – thankyou all for your efforts. Perhaps more importantly everyone got a chance to meet or catch up with others in the Lucene/Solr community, discuss problems and potential solutions and give some insights into how they use Lucene/Solr.
We’ll be running more Hackdays – watch this space! If you’re interested in supporting or running a Hackday and empowering your search team, get in touch.