
Welcome back, dear reader! In this post, we unwrap the mystery behind two popular search relevance metrics through visualization, and discuss their pros and cons. Our subjects for this exercise are Normalized Discounted Cumulative Gain, and Expected Reciprocal Rank, commonly acronymified as nDCG and ERR. We’ll start with some refresher background, visualize what these metrics actually look like, and paint a picture of how each can be either helpful or misleading, depending on the situation. Afterwards, you’ll have a better understanding of their behavior and which ones to use when (and why).
Assumptions
Note that, while some basic things are explained, this is not an introduction to these metrics – so I’ll assume you’ve at least heard of nDCG and what it’s used for! So if you’re new to relevance measurement, you probably want to start with something like the book “Relevant Search”, or at the very least the Wikipedia article on search metrics.
As a formality, we’ll stick with the relevance grading scale of poor=1, fair=2, good=3, and perfect=4. We’re also only going to look at the grades of the top 4 result positions, and assume each of those results has a grade.
We’re going to also assume that your results are listed one at a time on each row, and not on a grid. There are varying opinions on how best to measure grid results, but that’s beyond the scope of this post.
OK! No more assumptions, let’s get to it…
Background
nDCG has been the go-to metric for measuring relevance in a typical search results list since its first introduction in SIGIR 2002. In the original ERR paper, improvements over its predecessor were mightily touted. However, though being around for about a decade, ERR is surprisingly underused.
The similarities shared between the two metrics are, as noted in the title, the discount and cumulative functions of relevance. These respectively mean that a result is ‘worth’ less the lower on the result list appears, and the grades of all the documents in the list contribute to the score for a query’s relevance. When I spoke at Haystack in April, I showed a simple breakdown of DCG while diagraming the components of the formula:

To get a DCG score, just follow these steps!
- For all the results
- Award a result by its relevance
- Punish a result by its rank
- Add all the result scores
Step 3 in the above diagram is the ‘discount’, and step 4 is the ‘cumulative’. Together they provide the motivation to get relevant documents to the top (and the irrelevant documents to the bottom) to acheive a higher overall score. nDCG has an additional trick up its sleeve – it uses the ideal list of documents to normalize the score between 0 and 1:

While this is helpful (or not, depending on your math chops), it’s hard to tease out the full picture. For one thing, it doesn’t use any sort of maximum grade. Grades can be anything, and this can be troublesome when performing apples-to-apples comparissons between results. We’ll see why later, but first let’s dive into Expected Reciprocal Rank, and its purported improvements over nDCG.
The first thing ERR incorporated as a fix, was that you must outright declare what the maximum possible grade is. This helps by not needing to calculate an ‘ideal’ score, but it also can be misleading because it assumes there are always relevant documents available. Another addition is the cascading model of relevance. When a user sees a search result they like, they are satisfied. Starting with the understanding that a user will lose trust in your search engine the longer it takes them to be satisfied is the cascade. It works by keeping a running tab of this ‘trust’ a user has, and punishes a query’s score when it’s not satisfying a user quickly.

Showdown
Whew! With that out of the way, time for the fun part. Let’s look at how these two actually differ in the real practical world. To do that, we’re going to map out every possible combination of grades for the top 4 positions, get their scores, and plot them. The Y axis is the resulting score based on its respective X axis grades of the top 4 results. For example, given the first four results with grades 2, 4, 3, 2, that gives us a standard nDCG of 0.7697. The Y axis is 0.7697, and the X axis is “2,4,3,2”. To make things more interesting, we’ll also look at different discount models. We can change the way lower scores are punished, and it is useful to see how this impacts the metric. The standard for nDCG is 1/log2(r+1), and the standard for ERR is 1/r (where ‘r’ is the position rank).
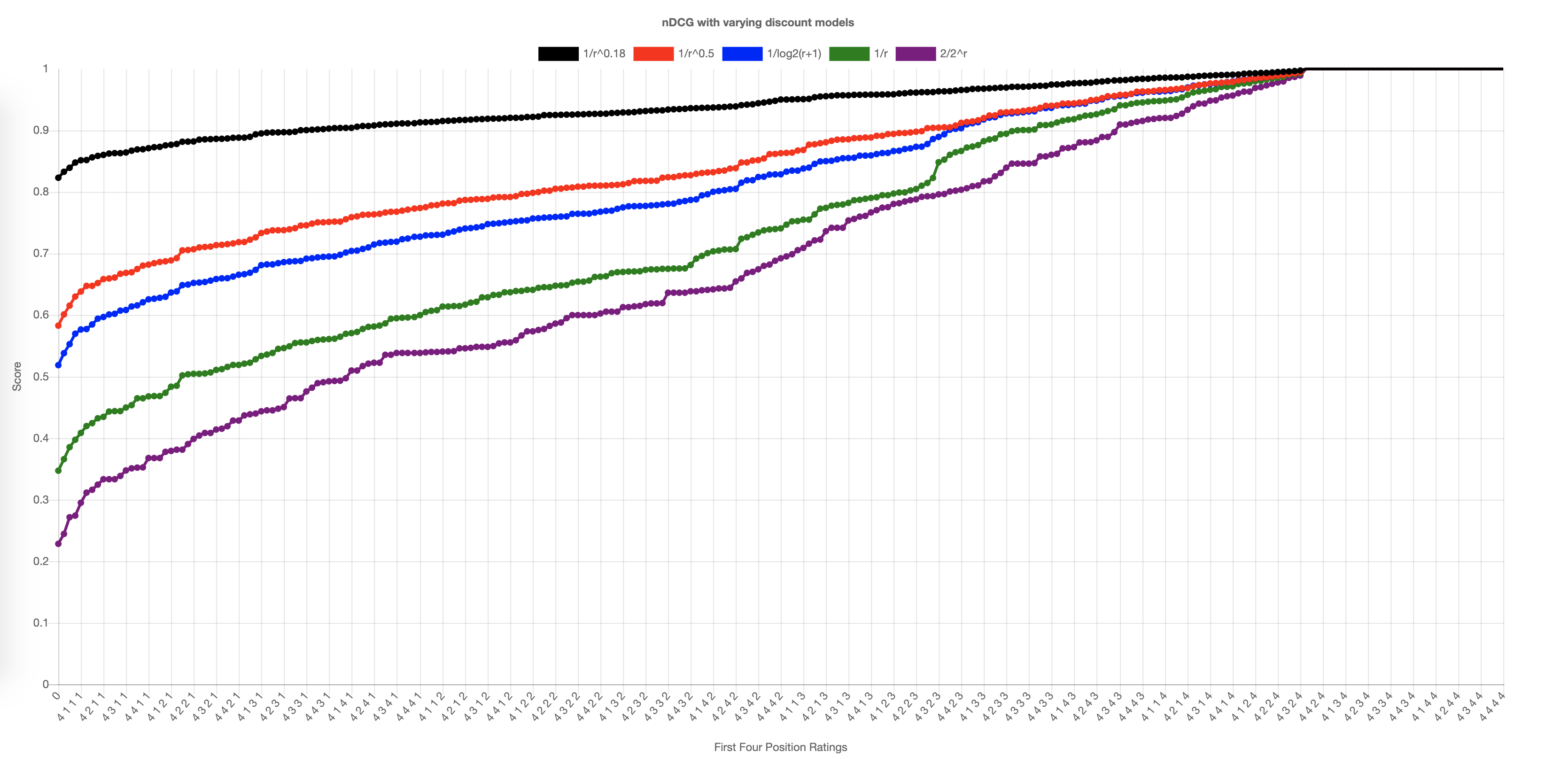
Noting specifics, for the standard discount model of nDCG, right away we start off at about 0.45. This means that for the top four results, you’ll never have a score lower than that. You can also see that lots of the possible combinations for nDCG yields a perfect score of 1.0. Why is this? Well, If your top four results are 1,1,1,1 nDCG will say that’s a perfect score because the ideal sort is the same. We’re going to actually list out the full table below, and you’ll see more of that harsh truth there.
But first, let’s show the visuals for ERR and compare:

Fascinating. You can clearly see the juxtaposition of nDCG favoring higher scores, and ERR with a more balanced growth. You can also clearly see the dropoff cliff in the ERR scores as soon as the top result becomes a 4 (perfectly relevant). For many of the discounts, ERR heavily favors queries that give a perfect first result. This is not surprising – because the user will be satisfied immediately, making the other results inconsequential.
You may have also noticed something interesting when examining the discount functions. Did you happen to catch 1/(r^0.18)? I arrived at that function through human learning (trial and error), looking for a good discount that provided a more gradual dropoff when the first result was not perfect. While this makes for a more balanced metric however, it can be seen as going against the cascading model’s purpose. With the far more drastic cliff of 1/r (the green line), there will be a much clearer signal for an irrelevant top result.
Pros and Cons
The visualizations above (and the data tables below), gave us an interesting glimpse into the behavior of these two formidable metrics.
nDCG
nDCG is a great metric when you’ve done your best job at grading, and don’t mind a high score when you have nothing better to offer. Remember, nDCG will return a perfect 1.0 for any result set that has the grades in order of highest to lowest in the resultset. When using nDCG, I always recommend using the global ideal rather than the local ideal. This means that when you know a better document exists is out of your measurement scope (like the 10th document in an nDCG@4 measurement), use that as part of your ideal and avoid just sorting the top 4. Also, for learning-to-rank, consider just using DCG without the normalization! If the goal is a higher number, nobody cares that it’s between 0 and 1. nDCG also has no way to indicate what the maximum score is. To get around this, sometimes it might suit well for the ideal to be all perfect scores for the positions as a best theoretically possible relevant set, as the ideal denominator.
ERR
The default ERR is a great metric for providing a good signal whether the top result is relevant. Some practitioners will argue this is all it’s good for, but If you are serving content that needs more flexibility, you can also tune the discount function for when this is not the case and you want more forgiveness. One interesting thing about ERR is that it never returns a perfect 1.0 score, and it will always assume that the score can be better, which is a main contrast with nDCG and one I happen to like.
Conclusions
In this authors opinion, I prefer using ERR and modifying it to your needs for most cases. It is more advanced than nDCG and may be more complex to explain, but it’s more closely aligned with how people actually behave and react – people do get frustrated with search engines that don’t show relevant documents at the top, so it’s a good idea to use a metric that models that frustration. There are those that argue for information needs with multiple good results (such as exploratory search), that ERR doesn’t accurately reflect this, but there are ways to customize ERR to build the desired measurement – the paper itself has a section on diversity for such occasions, which usually goes overlooked.
Thanks for reading, and see you next time!
Papers
Code
The code used to create the above plots and the data tables below can be found at https://github.com/o19s/metric-plots
Data Tables
Here are the colorized data tables for nDCG and ERR, as visualized above.
nDCG
| Position Grades | Discounted Scores | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 1/r^0.18 | 1/r^0.5 | 1/log2(r+1) | 1/r | 2/2^r |
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 2 | 0.919 | 0.791 | 0.75 | 0.633 | 0.548 |
| 1 | 1 | 1 | 3 | 0.86 | 0.658 | 0.601 | 0.443 | 0.333 |
| 1 | 1 | 1 | 4 | 0.823 | 0.583 | 0.519 | 0.347 | 0.228 |
| 1 | 1 | 2 | 1 | 0.935 | 0.823 | 0.781 | 0.673 | 0.613 |
| 1 | 1 | 2 | 2 | 0.922 | 0.797 | 0.76 | 0.639 | 0.538 |
| 1 | 1 | 2 | 3 | 0.871 | 0.68 | 0.626 | 0.468 | 0.352 |
| 1 | 1 | 2 | 4 | 0.833 | 0.601 | 0.538 | 0.366 | 0.244 |
| 1 | 1 | 3 | 1 | 0.886 | 0.711 | 0.65 | 0.505 | 0.429 |
| 1 | 1 | 3 | 2 | 0.886 | 0.711 | 0.654 | 0.505 | 0.408 |
| 1 | 1 | 3 | 3 | 0.885 | 0.71 | 0.66 | 0.504 | 0.379 |
| 1 | 1 | 3 | 4 | 0.848 | 0.63 | 0.57 | 0.397 | 0.272 |
| 1 | 1 | 4 | 1 | 0.856 | 0.647 | 0.577 | 0.42 | 0.339 |
| 1 | 1 | 4 | 2 | 0.859 | 0.652 | 0.585 | 0.424 | 0.333 |
| 1 | 1 | 4 | 3 | 0.862 | 0.659 | 0.597 | 0.432 | 0.325 |
| 1 | 1 | 4 | 4 | 0.867 | 0.67 | 0.614 | 0.444 | 0.311 |
| 1 | 2 | 1 | 1 | 0.957 | 0.878 | 0.838 | 0.755 | 0.742 |
| 1 | 2 | 1 | 2 | 0.939 | 0.839 | 0.804 | 0.705 | 0.641 |
| 1 | 2 | 1 | 3 | 0.882 | 0.706 | 0.652 | 0.505 | 0.408 |
| 1 | 2 | 1 | 4 | 0.839 | 0.615 | 0.553 | 0.385 | 0.274 |
| 1 | 2 | 2 | 1 | 0.95 | 0.864 | 0.828 | 0.738 | 0.692 |
| 1 | 2 | 2 | 2 | 0.95 | 0.864 | 0.833 | 0.739 | 0.674 |
| 1 | 2 | 2 | 3 | 0.897 | 0.736 | 0.684 | 0.538 | 0.44 |
| 1 | 2 | 2 | 4 | 0.852 | 0.638 | 0.577 | 0.408 | 0.295 |
| 1 | 2 | 3 | 1 | 0.904 | 0.751 | 0.695 | 0.56 | 0.493 |
| 1 | 2 | 3 | 2 | 0.91 | 0.763 | 0.71 | 0.573 | 0.493 |
| 1 | 2 | 3 | 3 | 0.904 | 0.752 | 0.705 | 0.56 | 0.451 |
| 1 | 2 | 3 | 4 | 0.863 | 0.661 | 0.602 | 0.435 | 0.316 |
| 1 | 2 | 4 | 1 | 0.869 | 0.675 | 0.607 | 0.454 | 0.378 |
| 1 | 2 | 4 | 2 | 0.876 | 0.686 | 0.621 | 0.465 | 0.381 |
| 1 | 2 | 4 | 3 | 0.877 | 0.689 | 0.628 | 0.468 | 0.368 |
| 1 | 2 | 4 | 4 | 0.878 | 0.693 | 0.638 | 0.474 | 0.348 |
| 1 | 3 | 1 | 1 | 0.926 | 0.8 | 0.741 | 0.629 | 0.619 |
| 1 | 3 | 1 | 2 | 0.919 | 0.787 | 0.734 | 0.615 | 0.577 |
| 1 | 3 | 1 | 3 | 0.91 | 0.77 | 0.723 | 0.594 | 0.517 |
| 1 | 3 | 1 | 4 | 0.864 | 0.667 | 0.608 | 0.45 | 0.351 |
| 1 | 3 | 2 | 1 | 0.926 | 0.802 | 0.748 | 0.633 | 0.606 |
| 1 | 3 | 2 | 2 | 0.929 | 0.809 | 0.758 | 0.641 | 0.6 |
| 1 | 3 | 2 | 3 | 0.919 | 0.788 | 0.744 | 0.617 | 0.538 |
| 1 | 3 | 2 | 4 | 0.873 | 0.684 | 0.627 | 0.468 | 0.368 |
| 1 | 3 | 3 | 1 | 0.927 | 0.805 | 0.757 | 0.639 | 0.586 |
| 1 | 3 | 3 | 2 | 0.929 | 0.81 | 0.765 | 0.645 | 0.582 |
| 1 | 3 | 3 | 3 | 0.933 | 0.818 | 0.777 | 0.656 | 0.576 |
| 1 | 3 | 3 | 4 | 0.888 | 0.714 | 0.659 | 0.502 | 0.399 |
| 1 | 3 | 4 | 1 | 0.89 | 0.719 | 0.656 | 0.511 | 0.444 |
| 1 | 3 | 4 | 2 | 0.894 | 0.726 | 0.666 | 0.519 | 0.445 |
| 1 | 3 | 4 | 3 | 0.9 | 0.739 | 0.682 | 0.534 | 0.448 |
| 1 | 3 | 4 | 4 | 0.897 | 0.733 | 0.682 | 0.528 | 0.415 |
| 1 | 4 | 1 | 1 | 0.906 | 0.756 | 0.688 | 0.565 | 0.559 |
| 1 | 4 | 1 | 2 | 0.904 | 0.752 | 0.688 | 0.561 | 0.541 |
| 1 | 4 | 1 | 3 | 0.901 | 0.746 | 0.687 | 0.555 | 0.51 |
| 1 | 4 | 1 | 4 | 0.896 | 0.738 | 0.686 | 0.545 | 0.464 |
| 1 | 4 | 2 | 1 | 0.908 | 0.76 | 0.695 | 0.571 | 0.556 |
| 1 | 4 | 2 | 2 | 0.911 | 0.767 | 0.704 | 0.577 | 0.554 |
| 1 | 4 | 2 | 3 | 0.907 | 0.759 | 0.702 | 0.57 | 0.523 |
| 1 | 4 | 2 | 4 | 0.902 | 0.749 | 0.698 | 0.558 | 0.476 |
| 1 | 4 | 3 | 1 | 0.912 | 0.768 | 0.707 | 0.581 | 0.55 |
| 1 | 4 | 3 | 2 | 0.914 | 0.773 | 0.715 | 0.586 | 0.548 |
| 1 | 4 | 3 | 3 | 0.918 | 0.782 | 0.727 | 0.597 | 0.546 |
| 1 | 4 | 3 | 4 | 0.911 | 0.768 | 0.719 | 0.581 | 0.497 |
| 1 | 4 | 4 | 1 | 0.916 | 0.778 | 0.724 | 0.596 | 0.541 |
| 1 | 4 | 4 | 2 | 0.918 | 0.782 | 0.73 | 0.6 | 0.54 |
| 1 | 4 | 4 | 3 | 0.921 | 0.788 | 0.739 | 0.608 | 0.538 |
| 1 | 4 | 4 | 4 | 0.925 | 0.799 | 0.754 | 0.622 | 0.536 |
| 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 1 | 1 | 2 | 0.971 | 0.933 | 0.931 | 0.902 | 0.846 |
| 2 | 1 | 1 | 3 | 0.903 | 0.763 | 0.727 | 0.615 | 0.521 |
| 2 | 1 | 1 | 4 | 0.852 | 0.648 | 0.594 | 0.444 | 0.333 |
| 2 | 1 | 2 | 1 | 0.983 | 0.958 | 0.955 | 0.934 | 0.897 |
| 2 | 1 | 2 | 2 | 0.977 | 0.944 | 0.941 | 0.913 | 0.86 |
| 2 | 1 | 2 | 3 | 0.915 | 0.787 | 0.753 | 0.641 | 0.547 |
| 2 | 1 | 2 | 4 | 0.863 | 0.669 | 0.616 | 0.465 | 0.353 |
| 2 | 1 | 3 | 1 | 0.925 | 0.809 | 0.77 | 0.67 | 0.606 |
| 2 | 1 | 3 | 2 | 0.928 | 0.815 | 0.778 | 0.675 | 0.6 |
| 2 | 1 | 3 | 3 | 0.918 | 0.793 | 0.76 | 0.645 | 0.538 |
| 2 | 1 | 3 | 4 | 0.873 | 0.687 | 0.637 | 0.485 | 0.368 |
| 2 | 1 | 4 | 1 | 0.882 | 0.707 | 0.649 | 0.512 | 0.437 |
| 2 | 1 | 4 | 2 | 0.887 | 0.717 | 0.66 | 0.521 | 0.439 |
| 2 | 1 | 4 | 3 | 0.886 | 0.715 | 0.663 | 0.519 | 0.419 |
| 2 | 1 | 4 | 4 | 0.886 | 0.714 | 0.666 | 0.516 | 0.39 |
| 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 2 | 1 | 2 | 0.991 | 0.979 | 0.98 | 0.971 | 0.953 |
| 2 | 2 | 1 | 3 | 0.925 | 0.81 | 0.777 | 0.675 | 0.6 |
| 2 | 2 | 1 | 4 | 0.869 | 0.682 | 0.63 | 0.484 | 0.381 |
| 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
| 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 |
| 2 | 2 | 2 | 3 | 0.939 | 0.838 | 0.805 | 0.707 | 0.636 |
| 2 | 2 | 2 | 4 | 0.882 | 0.705 | 0.653 | 0.507 | 0.404 |
| 2 | 2 | 3 | 1 | 0.944 | 0.851 | 0.815 | 0.726 | 0.68 |
| 2 | 2 | 3 | 2 | 0.95 | 0.863 | 0.829 | 0.74 | 0.688 |
| 2 | 2 | 3 | 3 | 0.937 | 0.834 | 0.803 | 0.701 | 0.613 |
| 2 | 2 | 3 | 4 | 0.888 | 0.719 | 0.669 | 0.523 | 0.414 |
| 2 | 2 | 4 | 1 | 0.897 | 0.738 | 0.681 | 0.549 | 0.482 |
| 2 | 2 | 4 | 2 | 0.904 | 0.751 | 0.695 | 0.562 | 0.489 |
| 2 | 2 | 4 | 3 | 0.901 | 0.745 | 0.694 | 0.556 | 0.465 |
| 2 | 2 | 4 | 4 | 0.897 | 0.738 | 0.692 | 0.546 | 0.429 |
| 2 | 3 | 1 | 1 | 0.958 | 0.885 | 0.85 | 0.78 | 0.775 |
| 2 | 3 | 1 | 2 | 0.957 | 0.883 | 0.851 | 0.778 | 0.76 |
| 2 | 3 | 1 | 3 | 0.941 | 0.848 | 0.819 | 0.73 | 0.67 |
| 2 | 3 | 1 | 4 | 0.888 | 0.723 | 0.673 | 0.536 | 0.445 |
| 2 | 3 | 2 | 1 | 0.964 | 0.897 | 0.864 | 0.795 | 0.787 |
| 2 | 3 | 2 | 2 | 0.968 | 0.905 | 0.874 | 0.805 | 0.792 |
| 2 | 3 | 2 | 3 | 0.951 | 0.868 | 0.84 | 0.755 | 0.699 |
| 2 | 3 | 2 | 4 | 0.898 | 0.741 | 0.692 | 0.556 | 0.465 |
| 2 | 3 | 3 | 1 | 0.956 | 0.881 | 0.85 | 0.773 | 0.736 |
| 2 | 3 | 3 | 2 | 0.96 | 0.889 | 0.859 | 0.782 | 0.742 |
| 2 | 3 | 3 | 3 | 0.958 | 0.886 | 0.86 | 0.779 | 0.723 |
| 2 | 3 | 3 | 4 | 0.909 | 0.765 | 0.718 | 0.583 | 0.491 |
| 2 | 3 | 4 | 1 | 0.912 | 0.771 | 0.719 | 0.595 | 0.535 |
| 2 | 3 | 4 | 2 | 0.917 | 0.781 | 0.73 | 0.605 | 0.541 |
| 2 | 3 | 4 | 3 | 0.921 | 0.789 | 0.741 | 0.614 | 0.539 |
| 2 | 3 | 4 | 4 | 0.913 | 0.774 | 0.731 | 0.596 | 0.492 |
| 2 | 4 | 1 | 1 | 0.927 | 0.807 | 0.752 | 0.649 | 0.644 |
| 2 | 4 | 1 | 2 | 0.929 | 0.81 | 0.757 | 0.653 | 0.64 |
| 2 | 4 | 1 | 3 | 0.922 | 0.797 | 0.749 | 0.637 | 0.6 |
| 2 | 4 | 1 | 4 | 0.913 | 0.779 | 0.736 | 0.614 | 0.54 |
| 2 | 4 | 2 | 1 | 0.933 | 0.818 | 0.765 | 0.662 | 0.655 |
| 2 | 4 | 2 | 2 | 0.937 | 0.827 | 0.775 | 0.671 | 0.66 |
| 2 | 4 | 2 | 3 | 0.93 | 0.813 | 0.765 | 0.654 | 0.618 |
| 2 | 4 | 2 | 4 | 0.92 | 0.792 | 0.749 | 0.629 | 0.556 |
| 2 | 4 | 3 | 1 | 0.932 | 0.818 | 0.768 | 0.662 | 0.639 |
| 2 | 4 | 3 | 2 | 0.936 | 0.826 | 0.777 | 0.671 | 0.643 |
| 2 | 4 | 3 | 3 | 0.938 | 0.83 | 0.784 | 0.676 | 0.636 |
| 2 | 4 | 3 | 4 | 0.927 | 0.807 | 0.766 | 0.648 | 0.574 |
| 2 | 4 | 4 | 1 | 0.932 | 0.818 | 0.773 | 0.663 | 0.615 |
| 2 | 4 | 4 | 2 | 0.935 | 0.824 | 0.78 | 0.67 | 0.619 |
| 2 | 4 | 4 | 3 | 0.936 | 0.827 | 0.785 | 0.674 | 0.614 |
| 2 | 4 | 4 | 4 | 0.938 | 0.832 | 0.795 | 0.681 | 0.606 |
| 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 1 | 1 | 2 | 0.982 | 0.959 | 0.959 | 0.945 | 0.915 |
| 3 | 1 | 1 | 3 | 0.958 | 0.905 | 0.903 | 0.865 | 0.793 |
| 3 | 1 | 1 | 4 | 0.895 | 0.751 | 0.717 | 0.607 | 0.51 |
| 3 | 1 | 2 | 1 | 0.989 | 0.975 | 0.973 | 0.963 | 0.944 |
| 3 | 1 | 2 | 2 | 0.984 | 0.964 | 0.963 | 0.949 | 0.92 |
| 3 | 1 | 2 | 3 | 0.962 | 0.912 | 0.91 | 0.872 | 0.802 |
| 3 | 1 | 2 | 4 | 0.902 | 0.764 | 0.73 | 0.62 | 0.523 |
| 3 | 1 | 3 | 1 | 0.975 | 0.94 | 0.936 | 0.91 | 0.862 |
| 3 | 1 | 3 | 2 | 0.972 | 0.934 | 0.931 | 0.901 | 0.846 |
| 3 | 1 | 3 | 3 | 0.968 | 0.925 | 0.922 | 0.885 | 0.818 |
| 3 | 1 | 3 | 4 | 0.914 | 0.786 | 0.753 | 0.644 | 0.546 |
| 3 | 1 | 4 | 1 | 0.921 | 0.802 | 0.765 | 0.668 | 0.603 |
| 3 | 1 | 4 | 2 | 0.923 | 0.805 | 0.769 | 0.671 | 0.6 |
| 3 | 1 | 4 | 3 | 0.926 | 0.811 | 0.777 | 0.676 | 0.595 |
| 3 | 1 | 4 | 4 | 0.917 | 0.792 | 0.76 | 0.648 | 0.538 |
| 3 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 2 | 1 | 2 | 0.994 | 0.986 | 0.987 | 0.983 | 0.973 |
| 3 | 2 | 1 | 3 | 0.97 | 0.931 | 0.93 | 0.901 | 0.846 |
| 3 | 2 | 1 | 4 | 0.907 | 0.775 | 0.743 | 0.637 | 0.548 |
| 3 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 |
| 3 | 2 | 2 | 3 | 0.977 | 0.945 | 0.944 | 0.918 | 0.871 |
| 3 | 2 | 2 | 4 | 0.916 | 0.792 | 0.759 | 0.654 | 0.567 |
| 3 | 2 | 3 | 1 | 0.985 | 0.963 | 0.961 | 0.943 | 0.912 |
| 3 | 2 | 3 | 2 | 0.986 | 0.966 | 0.963 | 0.946 | 0.914 |
| 3 | 2 | 3 | 3 | 0.981 | 0.953 | 0.951 | 0.926 | 0.881 |
| 3 | 2 | 3 | 4 | 0.925 | 0.811 | 0.779 | 0.676 | 0.588 |
| 3 | 2 | 4 | 1 | 0.931 | 0.824 | 0.788 | 0.696 | 0.639 |
| 3 | 2 | 4 | 2 | 0.935 | 0.832 | 0.796 | 0.704 | 0.643 |
| 3 | 2 | 4 | 3 | 0.937 | 0.835 | 0.802 | 0.707 | 0.636 |
| 3 | 2 | 4 | 4 | 0.926 | 0.812 | 0.781 | 0.674 | 0.574 |
| 3 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 3 | 1 | 2 | 0.995 | 0.989 | 0.99 | 0.986 | 0.978 |
| 3 | 3 | 1 | 3 | 0.987 | 0.972 | 0.973 | 0.962 | 0.939 |
| 3 | 3 | 1 | 4 | 0.927 | 0.818 | 0.787 | 0.692 | 0.62 |
| 3 | 3 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 3 | 2 | 2 | 1 | 1 | 1 | 1 | 1 |
| 3 | 3 | 2 | 3 | 0.992 | 0.982 | 0.983 | 0.975 | 0.96 |
| 3 | 3 | 2 | 4 | 0.934 | 0.831 | 0.8 | 0.707 | 0.636 |
| 3 | 3 | 3 | 1 | 1 | 1 | 1 | 1 | 1 |
| 3 | 3 | 3 | 2 | 1 | 1 | 1 | 1 | 1 |
| 3 | 3 | 3 | 3 | 1 | 1 | 1 | 1 | 1 |
| 3 | 3 | 3 | 4 | 0.945 | 0.854 | 0.824 | 0.734 | 0.669 |
| 3 | 3 | 4 | 1 | 0.948 | 0.862 | 0.829 | 0.747 | 0.706 |
| 3 | 3 | 4 | 2 | 0.951 | 0.867 | 0.835 | 0.753 | 0.709 |
| 3 | 3 | 4 | 3 | 0.956 | 0.877 | 0.846 | 0.764 | 0.716 |
| 3 | 3 | 4 | 4 | 0.943 | 0.848 | 0.819 | 0.724 | 0.642 |
| 3 | 4 | 1 | 1 | 0.959 | 0.889 | 0.855 | 0.79 | 0.788 |
| 3 | 4 | 1 | 2 | 0.958 | 0.887 | 0.855 | 0.789 | 0.781 |
| 3 | 4 | 1 | 3 | 0.957 | 0.885 | 0.856 | 0.787 | 0.767 |
| 3 | 4 | 1 | 4 | 0.942 | 0.852 | 0.825 | 0.741 | 0.682 |
| 3 | 4 | 2 | 1 | 0.962 | 0.894 | 0.862 | 0.797 | 0.794 |
| 3 | 4 | 2 | 2 | 0.964 | 0.899 | 0.867 | 0.802 | 0.796 |
| 3 | 4 | 2 | 3 | 0.962 | 0.896 | 0.867 | 0.799 | 0.782 |
| 3 | 4 | 2 | 4 | 0.947 | 0.862 | 0.835 | 0.752 | 0.695 |
| 3 | 4 | 3 | 1 | 0.966 | 0.904 | 0.874 | 0.81 | 0.804 |
| 3 | 4 | 3 | 2 | 0.968 | 0.908 | 0.878 | 0.815 | 0.806 |
| 3 | 4 | 3 | 3 | 0.971 | 0.915 | 0.886 | 0.823 | 0.811 |
| 3 | 4 | 3 | 4 | 0.955 | 0.879 | 0.853 | 0.774 | 0.721 |
| 3 | 4 | 4 | 1 | 0.959 | 0.888 | 0.859 | 0.787 | 0.754 |
| 3 | 4 | 4 | 2 | 0.96 | 0.891 | 0.863 | 0.792 | 0.756 |
| 3 | 4 | 4 | 3 | 0.964 | 0.898 | 0.871 | 0.799 | 0.761 |
| 3 | 4 | 4 | 4 | 0.962 | 0.894 | 0.87 | 0.795 | 0.742 |
| 4 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 1 | 1 | 2 | 0.989 | 0.977 | 0.978 | 0.971 | 0.956 |
| 4 | 1 | 1 | 3 | 0.973 | 0.941 | 0.941 | 0.921 | 0.881 |
| 4 | 1 | 1 | 4 | 0.951 | 0.891 | 0.89 | 0.848 | 0.77 |
| 4 | 1 | 2 | 1 | 0.994 | 0.986 | 0.985 | 0.98 | 0.97 |
| 4 | 1 | 2 | 2 | 0.99 | 0.979 | 0.979 | 0.972 | 0.957 |
| 4 | 1 | 2 | 3 | 0.975 | 0.944 | 0.944 | 0.924 | 0.884 |
| 4 | 1 | 2 | 4 | 0.954 | 0.896 | 0.894 | 0.853 | 0.775 |
| 4 | 1 | 3 | 1 | 0.984 | 0.963 | 0.961 | 0.948 | 0.921 |
| 4 | 1 | 3 | 2 | 0.981 | 0.958 | 0.957 | 0.941 | 0.91 |
| 4 | 1 | 3 | 3 | 0.978 | 0.949 | 0.949 | 0.929 | 0.89 |
| 4 | 1 | 3 | 4 | 0.958 | 0.904 | 0.901 | 0.86 | 0.785 |
| 4 | 1 | 4 | 1 | 0.971 | 0.932 | 0.928 | 0.899 | 0.847 |
| 4 | 1 | 4 | 2 | 0.97 | 0.929 | 0.925 | 0.895 | 0.84 |
| 4 | 1 | 4 | 3 | 0.968 | 0.924 | 0.921 | 0.887 | 0.826 |
| 4 | 1 | 4 | 4 | 0.965 | 0.917 | 0.913 | 0.874 | 0.801 |
| 4 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 2 | 1 | 2 | 0.996 | 0.992 | 0.993 | 0.991 | 0.986 |
| 4 | 2 | 1 | 3 | 0.98 | 0.956 | 0.956 | 0.941 | 0.91 |
| 4 | 2 | 1 | 4 | 0.958 | 0.905 | 0.904 | 0.867 | 0.797 |
| 4 | 2 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 |
| 4 | 2 | 2 | 3 | 0.984 | 0.964 | 0.964 | 0.951 | 0.924 |
| 4 | 2 | 2 | 4 | 0.962 | 0.914 | 0.912 | 0.876 | 0.81 |
| 4 | 2 | 3 | 1 | 0.99 | 0.977 | 0.975 | 0.966 | 0.948 |
| 4 | 2 | 3 | 2 | 0.99 | 0.978 | 0.976 | 0.967 | 0.949 |
| 4 | 2 | 3 | 3 | 0.986 | 0.968 | 0.967 | 0.954 | 0.927 |
| 4 | 2 | 3 | 4 | 0.966 | 0.92 | 0.918 | 0.883 | 0.817 |
| 4 | 2 | 4 | 1 | 0.976 | 0.944 | 0.94 | 0.916 | 0.872 |
| 4 | 2 | 4 | 2 | 0.977 | 0.946 | 0.942 | 0.918 | 0.873 |
| 4 | 2 | 4 | 3 | 0.975 | 0.94 | 0.937 | 0.909 | 0.858 |
| 4 | 2 | 4 | 4 | 0.971 | 0.931 | 0.928 | 0.894 | 0.831 |
| 4 | 3 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 3 | 1 | 2 | 0.997 | 0.993 | 0.994 | 0.992 | 0.987 |
| 4 | 3 | 1 | 3 | 0.991 | 0.981 | 0.982 | 0.976 | 0.963 |
| 4 | 3 | 1 | 4 | 0.969 | 0.93 | 0.929 | 0.9 | 0.846 |
| 4 | 3 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 3 | 2 | 2 | 1 | 1 | 1 | 1 | 1 |
| 4 | 3 | 2 | 3 | 0.994 | 0.988 | 0.989 | 0.985 | 0.976 |
| 4 | 3 | 2 | 4 | 0.973 | 0.937 | 0.936 | 0.909 | 0.858 |
| 4 | 3 | 3 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 3 | 3 | 2 | 1 | 1 | 1 | 1 | 1 |
| 4 | 3 | 3 | 3 | 1 | 1 | 1 | 1 | 1 |
| 4 | 3 | 3 | 4 | 0.979 | 0.95 | 0.948 | 0.925 | 0.881 |
| 4 | 3 | 4 | 1 | 0.986 | 0.966 | 0.963 | 0.947 | 0.918 |
| 4 | 3 | 4 | 2 | 0.986 | 0.967 | 0.964 | 0.948 | 0.919 |
| 4 | 3 | 4 | 3 | 0.987 | 0.969 | 0.966 | 0.95 | 0.92 |
| 4 | 3 | 4 | 4 | 0.982 | 0.956 | 0.954 | 0.932 | 0.889 |
| 4 | 4 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 4 | 1 | 2 | 0.997 | 0.994 | 0.995 | 0.993 | 0.989 |
| 4 | 4 | 1 | 3 | 0.993 | 0.985 | 0.985 | 0.98 | 0.969 |
| 4 | 4 | 1 | 4 | 0.986 | 0.969 | 0.97 | 0.958 | 0.934 |
| 4 | 4 | 2 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 4 | 2 | 2 | 1 | 1 | 1 | 1 | 1 |
| 4 | 4 | 2 | 3 | 0.995 | 0.99 | 0.991 | 0.987 | 0.98 |
| 4 | 4 | 2 | 4 | 0.988 | 0.974 | 0.975 | 0.965 | 0.944 |
| 4 | 4 | 3 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 4 | 3 | 2 | 1 | 1 | 1 | 1 | 1 |
| 4 | 4 | 3 | 3 | 1 | 1 | 1 | 1 | 1 |
| 4 | 4 | 3 | 4 | 0.993 | 0.984 | 0.984 | 0.977 | 0.963 |
| 4 | 4 | 4 | 1 | 1 | 1 | 1 | 1 | 1 |
| 4 | 4 | 4 | 2 | 1 | 1 | 1 | 1 | 1 |
| 4 | 4 | 4 | 3 | 1 | 1 | 1 | 1 | 1 |
| 4 | 4 | 4 | 4 | 1 | 1 | 1 | 1 | 1 |
ERR
| Position Grades | Discounted Scores | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 1/r^0.18 | 1/r^0.5 | 1/log2(r+1) | 1/r | 2/2^r |
| 1 | 1 | 1 | 1 | 0.159 | 0.136 | 0.127 | 0.11 | 0.106 |
| 1 | 1 | 1 | 2 | 0.159 | 0.136 | 0.127 | 0.11 | 0.106 |
| 1 | 1 | 1 | 3 | 0.159 | 0.136 | 0.127 | 0.11 | 0.106 |
| 1 | 1 | 1 | 4 | 0.159 | 0.136 | 0.127 | 0.11 | 0.106 |
| 1 | 1 | 2 | 1 | 0.249 | 0.199 | 0.182 | 0.147 | 0.133 |
| 1 | 1 | 2 | 2 | 0.249 | 0.199 | 0.182 | 0.147 | 0.133 |
| 1 | 1 | 2 | 3 | 0.249 | 0.199 | 0.182 | 0.147 | 0.133 |
| 1 | 1 | 2 | 4 | 0.249 | 0.199 | 0.182 | 0.147 | 0.133 |
| 1 | 1 | 3 | 1 | 0.43 | 0.326 | 0.292 | 0.22 | 0.188 |
| 1 | 1 | 3 | 2 | 0.43 | 0.326 | 0.292 | 0.22 | 0.188 |
| 1 | 1 | 3 | 3 | 0.43 | 0.326 | 0.292 | 0.22 | 0.188 |
| 1 | 1 | 3 | 4 | 0.43 | 0.326 | 0.292 | 0.22 | 0.188 |
| 1 | 1 | 4 | 1 | 0.79 | 0.58 | 0.511 | 0.366 | 0.298 |
| 1 | 1 | 4 | 2 | 0.79 | 0.58 | 0.511 | 0.366 | 0.298 |
| 1 | 1 | 4 | 3 | 0.79 | 0.58 | 0.511 | 0.366 | 0.298 |
| 1 | 1 | 4 | 4 | 0.79 | 0.58 | 0.511 | 0.366 | 0.298 |
| 1 | 2 | 1 | 1 | 0.257 | 0.214 | 0.197 | 0.166 | 0.162 |
| 1 | 2 | 1 | 2 | 0.257 | 0.214 | 0.197 | 0.166 | 0.162 |
| 1 | 2 | 1 | 3 | 0.257 | 0.214 | 0.197 | 0.166 | 0.162 |
| 1 | 2 | 1 | 4 | 0.257 | 0.214 | 0.197 | 0.166 | 0.162 |
| 1 | 2 | 2 | 1 | 0.335 | 0.269 | 0.245 | 0.198 | 0.186 |
| 1 | 2 | 2 | 2 | 0.335 | 0.269 | 0.245 | 0.198 | 0.186 |
| 1 | 2 | 2 | 3 | 0.335 | 0.269 | 0.245 | 0.198 | 0.186 |
| 1 | 2 | 2 | 4 | 0.335 | 0.269 | 0.245 | 0.198 | 0.186 |
| 1 | 2 | 3 | 1 | 0.491 | 0.379 | 0.34 | 0.261 | 0.234 |
| 1 | 2 | 3 | 2 | 0.491 | 0.379 | 0.34 | 0.261 | 0.234 |
| 1 | 2 | 3 | 3 | 0.491 | 0.379 | 0.34 | 0.261 | 0.234 |
| 1 | 2 | 3 | 4 | 0.491 | 0.379 | 0.34 | 0.261 | 0.234 |
| 1 | 2 | 4 | 1 | 0.804 | 0.599 | 0.53 | 0.388 | 0.329 |
| 1 | 2 | 4 | 2 | 0.804 | 0.599 | 0.53 | 0.388 | 0.329 |
| 1 | 2 | 4 | 3 | 0.804 | 0.599 | 0.53 | 0.388 | 0.329 |
| 1 | 2 | 4 | 4 | 0.804 | 0.599 | 0.53 | 0.388 | 0.329 |
| 1 | 3 | 1 | 1 | 0.452 | 0.372 | 0.338 | 0.279 | 0.276 |
| 1 | 3 | 1 | 2 | 0.452 | 0.372 | 0.338 | 0.279 | 0.276 |
| 1 | 3 | 1 | 3 | 0.452 | 0.372 | 0.338 | 0.279 | 0.276 |
| 1 | 3 | 1 | 4 | 0.452 | 0.372 | 0.338 | 0.279 | 0.276 |
| 1 | 3 | 2 | 1 | 0.506 | 0.41 | 0.371 | 0.301 | 0.292 |
| 1 | 3 | 2 | 2 | 0.506 | 0.41 | 0.371 | 0.301 | 0.292 |
| 1 | 3 | 2 | 3 | 0.506 | 0.41 | 0.371 | 0.301 | 0.292 |
| 1 | 3 | 2 | 4 | 0.506 | 0.41 | 0.371 | 0.301 | 0.292 |
| 1 | 3 | 3 | 1 | 0.614 | 0.486 | 0.437 | 0.344 | 0.325 |
| 1 | 3 | 3 | 2 | 0.614 | 0.486 | 0.437 | 0.344 | 0.325 |
| 1 | 3 | 3 | 3 | 0.614 | 0.486 | 0.437 | 0.344 | 0.325 |
| 1 | 3 | 3 | 4 | 0.614 | 0.486 | 0.437 | 0.344 | 0.325 |
| 1 | 3 | 4 | 1 | 0.83 | 0.638 | 0.568 | 0.432 | 0.391 |
| 1 | 3 | 4 | 2 | 0.83 | 0.638 | 0.568 | 0.432 | 0.391 |
| 1 | 3 | 4 | 3 | 0.83 | 0.638 | 0.568 | 0.432 | 0.391 |
| 1 | 3 | 4 | 4 | 0.83 | 0.638 | 0.568 | 0.432 | 0.391 |
| 1 | 4 | 1 | 1 | 0.841 | 0.686 | 0.619 | 0.503 | 0.503 |
| 1 | 4 | 1 | 2 | 0.841 | 0.686 | 0.619 | 0.503 | 0.503 |
| 1 | 4 | 1 | 3 | 0.841 | 0.686 | 0.619 | 0.503 | 0.503 |
| 1 | 4 | 1 | 4 | 0.841 | 0.686 | 0.619 | 0.503 | 0.503 |
| 1 | 4 | 2 | 1 | 0.847 | 0.69 | 0.623 | 0.506 | 0.505 |
| 1 | 4 | 2 | 2 | 0.847 | 0.69 | 0.623 | 0.506 | 0.505 |
| 1 | 4 | 2 | 3 | 0.847 | 0.69 | 0.623 | 0.506 | 0.505 |
| 1 | 4 | 2 | 4 | 0.847 | 0.69 | 0.623 | 0.506 | 0.505 |
| 1 | 4 | 3 | 1 | 0.859 | 0.699 | 0.63 | 0.51 | 0.508 |
| 1 | 4 | 3 | 2 | 0.859 | 0.699 | 0.63 | 0.51 | 0.508 |
| 1 | 4 | 3 | 3 | 0.859 | 0.699 | 0.63 | 0.51 | 0.508 |
| 1 | 4 | 3 | 4 | 0.859 | 0.699 | 0.63 | 0.51 | 0.508 |
| 1 | 4 | 4 | 1 | 0.883 | 0.716 | 0.644 | 0.52 | 0.516 |
| 1 | 4 | 4 | 2 | 0.883 | 0.716 | 0.644 | 0.52 | 0.516 |
| 1 | 4 | 4 | 3 | 0.883 | 0.716 | 0.644 | 0.52 | 0.516 |
| 1 | 4 | 4 | 4 | 0.883 | 0.716 | 0.644 | 0.52 | 0.516 |
| 2 | 1 | 1 | 1 | 0.271 | 0.251 | 0.243 | 0.229 | 0.225 |
| 2 | 1 | 1 | 2 | 0.271 | 0.251 | 0.243 | 0.229 | 0.225 |
| 2 | 1 | 1 | 3 | 0.271 | 0.251 | 0.243 | 0.229 | 0.225 |
| 2 | 1 | 1 | 4 | 0.271 | 0.251 | 0.243 | 0.229 | 0.225 |
| 2 | 1 | 2 | 1 | 0.35 | 0.306 | 0.291 | 0.26 | 0.249 |
| 2 | 1 | 2 | 2 | 0.35 | 0.306 | 0.291 | 0.26 | 0.249 |
| 2 | 1 | 2 | 3 | 0.35 | 0.306 | 0.291 | 0.26 | 0.249 |
| 2 | 1 | 2 | 4 | 0.35 | 0.306 | 0.291 | 0.26 | 0.249 |
| 2 | 1 | 3 | 1 | 0.506 | 0.416 | 0.386 | 0.324 | 0.296 |
| 2 | 1 | 3 | 2 | 0.506 | 0.416 | 0.386 | 0.324 | 0.296 |
| 2 | 1 | 3 | 3 | 0.506 | 0.416 | 0.386 | 0.324 | 0.296 |
| 2 | 1 | 3 | 4 | 0.506 | 0.416 | 0.386 | 0.324 | 0.296 |
| 2 | 1 | 4 | 1 | 0.818 | 0.636 | 0.577 | 0.451 | 0.391 |
| 2 | 1 | 4 | 2 | 0.818 | 0.636 | 0.577 | 0.451 | 0.391 |
| 2 | 1 | 4 | 3 | 0.818 | 0.636 | 0.577 | 0.451 | 0.391 |
| 2 | 1 | 4 | 4 | 0.818 | 0.636 | 0.577 | 0.451 | 0.391 |
| 2 | 2 | 1 | 1 | 0.356 | 0.319 | 0.304 | 0.277 | 0.274 |
| 2 | 2 | 1 | 2 | 0.356 | 0.319 | 0.304 | 0.277 | 0.274 |
| 2 | 2 | 1 | 3 | 0.356 | 0.319 | 0.304 | 0.277 | 0.274 |
| 2 | 2 | 1 | 4 | 0.356 | 0.319 | 0.304 | 0.277 | 0.274 |
| 2 | 2 | 2 | 1 | 0.424 | 0.367 | 0.346 | 0.305 | 0.295 |
| 2 | 2 | 2 | 2 | 0.424 | 0.367 | 0.346 | 0.305 | 0.295 |
| 2 | 2 | 2 | 3 | 0.424 | 0.367 | 0.346 | 0.305 | 0.295 |
| 2 | 2 | 2 | 4 | 0.424 | 0.367 | 0.346 | 0.305 | 0.295 |
| 2 | 2 | 3 | 1 | 0.559 | 0.462 | 0.428 | 0.36 | 0.336 |
| 2 | 2 | 3 | 2 | 0.559 | 0.462 | 0.428 | 0.36 | 0.336 |
| 2 | 2 | 3 | 3 | 0.559 | 0.462 | 0.428 | 0.36 | 0.336 |
| 2 | 2 | 3 | 4 | 0.559 | 0.462 | 0.428 | 0.36 | 0.336 |
| 2 | 2 | 4 | 1 | 0.83 | 0.653 | 0.593 | 0.47 | 0.418 |
| 2 | 2 | 4 | 2 | 0.83 | 0.653 | 0.593 | 0.47 | 0.418 |
| 2 | 2 | 4 | 3 | 0.83 | 0.653 | 0.593 | 0.47 | 0.418 |
| 2 | 2 | 4 | 4 | 0.83 | 0.653 | 0.593 | 0.47 | 0.418 |
| 2 | 3 | 1 | 1 | 0.525 | 0.455 | 0.426 | 0.375 | 0.372 |
| 2 | 3 | 1 | 2 | 0.525 | 0.455 | 0.426 | 0.375 | 0.372 |
| 2 | 3 | 1 | 3 | 0.525 | 0.455 | 0.426 | 0.375 | 0.372 |
| 2 | 3 | 1 | 4 | 0.525 | 0.455 | 0.426 | 0.375 | 0.372 |
| 2 | 3 | 2 | 1 | 0.572 | 0.488 | 0.455 | 0.394 | 0.387 |
| 2 | 3 | 2 | 2 | 0.572 | 0.488 | 0.455 | 0.394 | 0.387 |
| 2 | 3 | 2 | 3 | 0.572 | 0.488 | 0.455 | 0.394 | 0.387 |
| 2 | 3 | 2 | 4 | 0.572 | 0.488 | 0.455 | 0.394 | 0.387 |
| 2 | 3 | 3 | 1 | 0.665 | 0.554 | 0.512 | 0.432 | 0.415 |
| 2 | 3 | 3 | 2 | 0.665 | 0.554 | 0.512 | 0.432 | 0.415 |
| 2 | 3 | 3 | 3 | 0.665 | 0.554 | 0.512 | 0.432 | 0.415 |
| 2 | 3 | 3 | 4 | 0.665 | 0.554 | 0.512 | 0.432 | 0.415 |
| 2 | 3 | 4 | 1 | 0.853 | 0.686 | 0.626 | 0.508 | 0.472 |
| 2 | 3 | 4 | 2 | 0.853 | 0.686 | 0.626 | 0.508 | 0.472 |
| 2 | 3 | 4 | 3 | 0.853 | 0.686 | 0.626 | 0.508 | 0.472 |
| 2 | 3 | 4 | 4 | 0.853 | 0.686 | 0.626 | 0.508 | 0.472 |
| 2 | 4 | 1 | 1 | 0.862 | 0.728 | 0.67 | 0.569 | 0.569 |
| 2 | 4 | 1 | 2 | 0.862 | 0.728 | 0.67 | 0.569 | 0.569 |
| 2 | 4 | 1 | 3 | 0.862 | 0.728 | 0.67 | 0.569 | 0.569 |
| 2 | 4 | 1 | 4 | 0.862 | 0.728 | 0.67 | 0.569 | 0.569 |
| 2 | 4 | 2 | 1 | 0.868 | 0.732 | 0.673 | 0.572 | 0.571 |
| 2 | 4 | 2 | 2 | 0.868 | 0.732 | 0.673 | 0.572 | 0.571 |
| 2 | 4 | 2 | 3 | 0.868 | 0.732 | 0.673 | 0.572 | 0.571 |
| 2 | 4 | 2 | 4 | 0.868 | 0.732 | 0.673 | 0.572 | 0.571 |
| 2 | 4 | 3 | 1 | 0.878 | 0.739 | 0.679 | 0.576 | 0.574 |
| 2 | 4 | 3 | 2 | 0.878 | 0.739 | 0.679 | 0.576 | 0.574 |
| 2 | 4 | 3 | 3 | 0.878 | 0.739 | 0.679 | 0.576 | 0.574 |
| 2 | 4 | 3 | 4 | 0.878 | 0.739 | 0.679 | 0.576 | 0.574 |
| 2 | 4 | 4 | 1 | 0.899 | 0.754 | 0.692 | 0.584 | 0.58 |
| 2 | 4 | 4 | 2 | 0.899 | 0.754 | 0.692 | 0.584 | 0.58 |
| 2 | 4 | 4 | 3 | 0.899 | 0.754 | 0.692 | 0.584 | 0.58 |
| 2 | 4 | 4 | 4 | 0.899 | 0.754 | 0.692 | 0.584 | 0.58 |
| 3 | 1 | 1 | 1 | 0.496 | 0.481 | 0.476 | 0.466 | 0.463 |
| 3 | 1 | 1 | 2 | 0.496 | 0.481 | 0.476 | 0.466 | 0.463 |
| 3 | 1 | 1 | 3 | 0.496 | 0.481 | 0.476 | 0.466 | 0.463 |
| 3 | 1 | 1 | 4 | 0.496 | 0.481 | 0.476 | 0.466 | 0.463 |
| 3 | 1 | 2 | 1 | 0.55 | 0.519 | 0.509 | 0.488 | 0.48 |
| 3 | 1 | 2 | 2 | 0.55 | 0.519 | 0.509 | 0.488 | 0.48 |
| 3 | 1 | 2 | 3 | 0.55 | 0.519 | 0.509 | 0.488 | 0.48 |
| 3 | 1 | 2 | 4 | 0.55 | 0.519 | 0.509 | 0.488 | 0.48 |
| 3 | 1 | 3 | 1 | 0.658 | 0.596 | 0.575 | 0.532 | 0.513 |
| 3 | 1 | 3 | 2 | 0.658 | 0.596 | 0.575 | 0.532 | 0.513 |
| 3 | 1 | 3 | 3 | 0.658 | 0.596 | 0.575 | 0.532 | 0.513 |
| 3 | 1 | 3 | 4 | 0.658 | 0.596 | 0.575 | 0.532 | 0.513 |
| 3 | 1 | 4 | 1 | 0.874 | 0.748 | 0.707 | 0.62 | 0.579 |
| 3 | 1 | 4 | 2 | 0.874 | 0.748 | 0.707 | 0.62 | 0.579 |
| 3 | 1 | 4 | 3 | 0.874 | 0.748 | 0.707 | 0.62 | 0.579 |
| 3 | 1 | 4 | 4 | 0.874 | 0.748 | 0.707 | 0.62 | 0.579 |
| 3 | 2 | 1 | 1 | 0.554 | 0.529 | 0.518 | 0.5 | 0.497 |
| 3 | 2 | 1 | 2 | 0.554 | 0.529 | 0.518 | 0.5 | 0.497 |
| 3 | 2 | 1 | 3 | 0.554 | 0.529 | 0.518 | 0.5 | 0.497 |
| 3 | 2 | 1 | 4 | 0.554 | 0.529 | 0.518 | 0.5 | 0.497 |
| 3 | 2 | 2 | 1 | 0.601 | 0.562 | 0.547 | 0.519 | 0.512 |
| 3 | 2 | 2 | 2 | 0.601 | 0.562 | 0.547 | 0.519 | 0.512 |
| 3 | 2 | 2 | 3 | 0.601 | 0.562 | 0.547 | 0.519 | 0.512 |
| 3 | 2 | 2 | 4 | 0.601 | 0.562 | 0.547 | 0.519 | 0.512 |
| 3 | 2 | 3 | 1 | 0.695 | 0.628 | 0.604 | 0.557 | 0.54 |
| 3 | 2 | 3 | 2 | 0.695 | 0.628 | 0.604 | 0.557 | 0.54 |
| 3 | 2 | 3 | 3 | 0.695 | 0.628 | 0.604 | 0.557 | 0.54 |
| 3 | 2 | 3 | 4 | 0.695 | 0.628 | 0.604 | 0.557 | 0.54 |
| 3 | 2 | 4 | 1 | 0.882 | 0.759 | 0.718 | 0.633 | 0.597 |
| 3 | 2 | 4 | 2 | 0.882 | 0.759 | 0.718 | 0.633 | 0.597 |
| 3 | 2 | 4 | 3 | 0.882 | 0.759 | 0.718 | 0.633 | 0.597 |
| 3 | 2 | 4 | 4 | 0.882 | 0.759 | 0.718 | 0.633 | 0.597 |
| 3 | 3 | 1 | 1 | 0.671 | 0.623 | 0.603 | 0.567 | 0.565 |
| 3 | 3 | 1 | 2 | 0.671 | 0.623 | 0.603 | 0.567 | 0.565 |
| 3 | 3 | 1 | 3 | 0.671 | 0.623 | 0.603 | 0.567 | 0.565 |
| 3 | 3 | 1 | 4 | 0.671 | 0.623 | 0.603 | 0.567 | 0.565 |
| 3 | 3 | 2 | 1 | 0.703 | 0.646 | 0.622 | 0.58 | 0.575 |
| 3 | 3 | 2 | 2 | 0.703 | 0.646 | 0.622 | 0.58 | 0.575 |
| 3 | 3 | 2 | 3 | 0.703 | 0.646 | 0.622 | 0.58 | 0.575 |
| 3 | 3 | 2 | 4 | 0.703 | 0.646 | 0.622 | 0.58 | 0.575 |
| 3 | 3 | 3 | 1 | 0.768 | 0.691 | 0.662 | 0.607 | 0.595 |
| 3 | 3 | 3 | 2 | 0.768 | 0.691 | 0.662 | 0.607 | 0.595 |
| 3 | 3 | 3 | 3 | 0.768 | 0.691 | 0.662 | 0.607 | 0.595 |
| 3 | 3 | 3 | 4 | 0.768 | 0.691 | 0.662 | 0.607 | 0.595 |
| 3 | 3 | 4 | 1 | 0.898 | 0.783 | 0.741 | 0.659 | 0.635 |
| 3 | 3 | 4 | 2 | 0.898 | 0.783 | 0.741 | 0.659 | 0.635 |
| 3 | 3 | 4 | 3 | 0.898 | 0.783 | 0.741 | 0.659 | 0.635 |
| 3 | 3 | 4 | 4 | 0.898 | 0.783 | 0.741 | 0.659 | 0.635 |
| 3 | 4 | 1 | 1 | 0.905 | 0.812 | 0.771 | 0.702 | 0.702 |
| 3 | 4 | 1 | 2 | 0.905 | 0.812 | 0.771 | 0.702 | 0.702 |
| 3 | 4 | 1 | 3 | 0.905 | 0.812 | 0.771 | 0.702 | 0.702 |
| 3 | 4 | 1 | 4 | 0.905 | 0.812 | 0.771 | 0.702 | 0.702 |
| 3 | 4 | 2 | 1 | 0.908 | 0.814 | 0.774 | 0.703 | 0.703 |
| 3 | 4 | 2 | 2 | 0.908 | 0.814 | 0.774 | 0.703 | 0.703 |
| 3 | 4 | 2 | 3 | 0.908 | 0.814 | 0.774 | 0.703 | 0.703 |
| 3 | 4 | 2 | 4 | 0.908 | 0.814 | 0.774 | 0.703 | 0.703 |
| 3 | 4 | 3 | 1 | 0.916 | 0.819 | 0.778 | 0.706 | 0.705 |
| 3 | 4 | 3 | 2 | 0.916 | 0.819 | 0.778 | 0.706 | 0.705 |
| 3 | 4 | 3 | 3 | 0.916 | 0.819 | 0.778 | 0.706 | 0.705 |
| 3 | 4 | 3 | 4 | 0.916 | 0.819 | 0.778 | 0.706 | 0.705 |
| 3 | 4 | 4 | 1 | 0.93 | 0.829 | 0.787 | 0.712 | 0.709 |
| 3 | 4 | 4 | 2 | 0.93 | 0.829 | 0.787 | 0.712 | 0.709 |
| 3 | 4 | 4 | 3 | 0.93 | 0.829 | 0.787 | 0.712 | 0.709 |
| 3 | 4 | 4 | 4 | 0.93 | 0.829 | 0.787 | 0.712 | 0.709 |
| 4 | 1 | 1 | 1 | 0.944 | 0.942 | 0.942 | 0.941 | 0.94 |
| 4 | 1 | 1 | 2 | 0.944 | 0.942 | 0.942 | 0.941 | 0.94 |
| 4 | 1 | 1 | 3 | 0.944 | 0.942 | 0.942 | 0.941 | 0.94 |
| 4 | 1 | 1 | 4 | 0.944 | 0.942 | 0.942 | 0.941 | 0.94 |
| 4 | 1 | 2 | 1 | 0.95 | 0.947 | 0.945 | 0.943 | 0.942 |
| 4 | 1 | 2 | 2 | 0.95 | 0.947 | 0.945 | 0.943 | 0.942 |
| 4 | 1 | 2 | 3 | 0.95 | 0.947 | 0.945 | 0.943 | 0.942 |
| 4 | 1 | 2 | 4 | 0.95 | 0.947 | 0.945 | 0.943 | 0.942 |
| 4 | 1 | 3 | 1 | 0.962 | 0.955 | 0.953 | 0.948 | 0.946 |
| 4 | 1 | 3 | 2 | 0.962 | 0.955 | 0.953 | 0.948 | 0.946 |
| 4 | 1 | 3 | 3 | 0.962 | 0.955 | 0.953 | 0.948 | 0.946 |
| 4 | 1 | 3 | 4 | 0.962 | 0.955 | 0.953 | 0.948 | 0.946 |
| 4 | 1 | 4 | 1 | 0.986 | 0.972 | 0.967 | 0.958 | 0.953 |
| 4 | 1 | 4 | 2 | 0.986 | 0.972 | 0.967 | 0.958 | 0.953 |
| 4 | 1 | 4 | 3 | 0.986 | 0.972 | 0.967 | 0.958 | 0.953 |
| 4 | 1 | 4 | 4 | 0.986 | 0.972 | 0.967 | 0.958 | 0.953 |
| 4 | 2 | 1 | 1 | 0.95 | 0.948 | 0.946 | 0.944 | 0.944 |
| 4 | 2 | 1 | 2 | 0.95 | 0.948 | 0.946 | 0.944 | 0.944 |
| 4 | 2 | 1 | 3 | 0.95 | 0.948 | 0.946 | 0.944 | 0.944 |
| 4 | 2 | 1 | 4 | 0.95 | 0.948 | 0.946 | 0.944 | 0.944 |
| 4 | 2 | 2 | 1 | 0.956 | 0.951 | 0.95 | 0.947 | 0.946 |
| 4 | 2 | 2 | 2 | 0.956 | 0.951 | 0.95 | 0.947 | 0.946 |
| 4 | 2 | 2 | 3 | 0.956 | 0.951 | 0.95 | 0.947 | 0.946 |
| 4 | 2 | 2 | 4 | 0.956 | 0.951 | 0.95 | 0.947 | 0.946 |
| 4 | 2 | 3 | 1 | 0.966 | 0.959 | 0.956 | 0.951 | 0.949 |
| 4 | 2 | 3 | 2 | 0.966 | 0.959 | 0.956 | 0.951 | 0.949 |
| 4 | 2 | 3 | 3 | 0.966 | 0.959 | 0.956 | 0.951 | 0.949 |
| 4 | 2 | 3 | 4 | 0.966 | 0.959 | 0.956 | 0.951 | 0.949 |
| 4 | 2 | 4 | 1 | 0.987 | 0.973 | 0.969 | 0.959 | 0.955 |
| 4 | 2 | 4 | 2 | 0.987 | 0.973 | 0.969 | 0.959 | 0.955 |
| 4 | 2 | 4 | 3 | 0.987 | 0.973 | 0.969 | 0.959 | 0.955 |
| 4 | 2 | 4 | 4 | 0.987 | 0.973 | 0.969 | 0.959 | 0.955 |
| 4 | 3 | 1 | 1 | 0.963 | 0.958 | 0.956 | 0.952 | 0.952 |
| 4 | 3 | 1 | 2 | 0.963 | 0.958 | 0.956 | 0.952 | 0.952 |
| 4 | 3 | 1 | 3 | 0.963 | 0.958 | 0.956 | 0.952 | 0.952 |
| 4 | 3 | 1 | 4 | 0.963 | 0.958 | 0.956 | 0.952 | 0.952 |
| 4 | 3 | 2 | 1 | 0.967 | 0.961 | 0.958 | 0.953 | 0.953 |
| 4 | 3 | 2 | 2 | 0.967 | 0.961 | 0.958 | 0.953 | 0.953 |
| 4 | 3 | 2 | 3 | 0.967 | 0.961 | 0.958 | 0.953 | 0.953 |
| 4 | 3 | 2 | 4 | 0.967 | 0.961 | 0.958 | 0.953 | 0.953 |
| 4 | 3 | 3 | 1 | 0.974 | 0.966 | 0.962 | 0.956 | 0.955 |
| 4 | 3 | 3 | 2 | 0.974 | 0.966 | 0.962 | 0.956 | 0.955 |
| 4 | 3 | 3 | 3 | 0.974 | 0.966 | 0.962 | 0.956 | 0.955 |
| 4 | 3 | 3 | 4 | 0.974 | 0.966 | 0.962 | 0.956 | 0.955 |
| 4 | 3 | 4 | 1 | 0.989 | 0.976 | 0.971 | 0.962 | 0.959 |
| 4 | 3 | 4 | 2 | 0.989 | 0.976 | 0.971 | 0.962 | 0.959 |
| 4 | 3 | 4 | 3 | 0.989 | 0.976 | 0.971 | 0.962 | 0.959 |
| 4 | 3 | 4 | 4 | 0.989 | 0.976 | 0.971 | 0.962 | 0.959 |
| 4 | 4 | 1 | 1 | 0.989 | 0.979 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 1 | 2 | 0.989 | 0.979 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 1 | 3 | 0.989 | 0.979 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 1 | 4 | 0.989 | 0.979 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 2 | 1 | 0.99 | 0.979 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 2 | 2 | 0.99 | 0.979 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 2 | 3 | 0.99 | 0.979 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 2 | 4 | 0.99 | 0.979 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 3 | 1 | 0.991 | 0.98 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 3 | 2 | 0.991 | 0.98 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 3 | 3 | 0.991 | 0.98 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 3 | 4 | 0.991 | 0.98 | 0.975 | 0.967 | 0.967 |
| 4 | 4 | 4 | 1 | 0.992 | 0.981 | 0.976 | 0.968 | 0.968 |
| 4 | 4 | 4 | 2 | 0.992 | 0.981 | 0.976 | 0.968 | 0.968 |
| 4 | 4 | 4 | 3 | 0.992 | 0.981 | 0.976 | 0.968 | 0.968 |
| 4 | 4 | 4 | 4 | 0.992 | 0.981 | 0.976 | 0.968 | 0.968 |