
 Nate Day
Nate Day
Category: Conference
This post is part of a series I’ve been writing about participating in TREC 2020’s News Track. This post is a visual report of the retrieval performance we observed on test data from the 2019 competition. See earlier posts for more details about TREC and the strategies we are using.
More Like This and beyond…
All of our strategies for TREC News were all built on top of Elasticsearch’s More-Like-This query (MLT). MLT is a specialized query designed for recommendation, so we chose it as our baseline. Our goal was to experiment with way to improve upon MLT. We hypothesized three additions that would improve retrieval ranking: query parameter tuning, named entity recognition (NER) via spaCy, and sentence embedding via Sentence-BERT.
In the end we submitted 4 strategies:
- MLT Default (base): Out of the box MLT query with default parameters
- MLT Tuned (tune): MLT query using tuned parameters from Quarite
- MLT Tuned + NER (tune_ners) : Enriched index with field for named entities detected by Spacy’s
en_core_web_lgmodel. - MLT Tuned + NER + Embedding (tune_ners_embed): Sentence embedding similarity as a document score modifier.
Each of these strategies layers on top of the query configuration from the prior strategy. And each one of these “layers” produced an improvement in search performance. Ultimately the MLT Tuned + NER + Embedding strategy produced the best performance, but the stock MLT Default was not that far behind.
Measuring relevant suggestions
The goal of this retrieval task is to provide background news articles. Given a source article, the retrieval system should find background articles that provide valuable context to the supplement source article. These background articles are graded for relevance using a 0-4 scale:
- 0 – The linked document provides little or no useful background information.
- 1 – The linked document provides some useful background or contextual information that would help the user understand the broader story context of the query article.
- 2 – The document provides significantly useful background
- 3 – The document provides essential useful background
- 4 – The document MUST appear in the sidebar otherwise critical context is missing.
The grades for the top five articles are then rolled up in a single nDCG@5 summary score for each source article.
TREC, like other machine-learning competitions, requires submissions that are blind. So we had to use the data from 2019 competition to evaluate our strategies. That is the data that is reported here.
There were originally 60 topics (source articles) used in the 2019’s News track evaluation. Due to formatting issues, we dropped 5 of these because the source article didn’t make it into the index. Each strategy is run on all 55 of the remaining topics.
And the winner is…
Strategies for TREC News will be evaluated based on the mean of the nDCG@5 across all of the topics, so that’s what are using here. This plot shows the overall performance of our 4 strategies (x-axis) using nDCG@5 (y-axis) as the evaluation metric. Each of our 55 test topics is shown as a single dot in each strategy. The 95% mean confidence interval is shown as a crossbar and the observed mean values are reported in the labels.
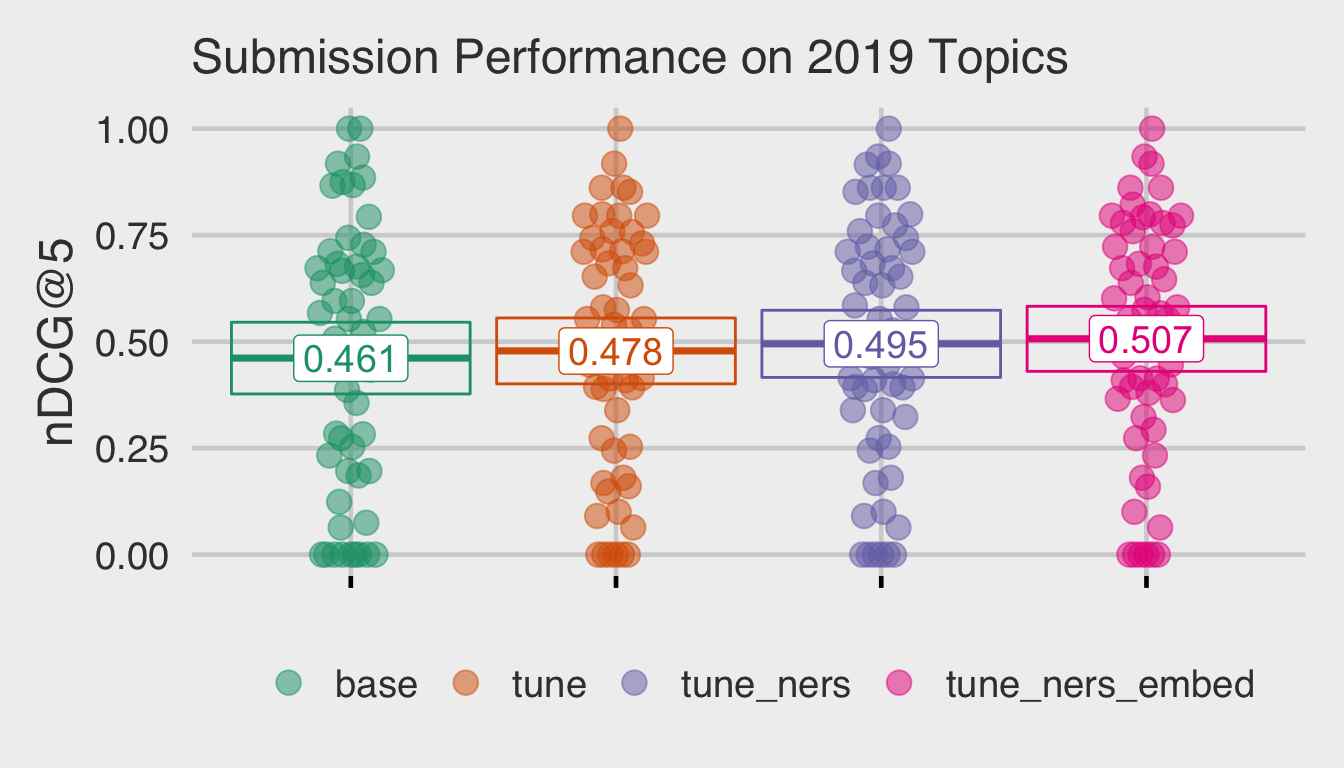
There is a steady trend of increasing retrieval performance as new components are layered onto the strategy. The changes are never massive, but that is a testament to how good Elasticsearch is. Even out of the box MLT (base) performs almost as well as our “Cadillac” strategy (tune_ners_embed). Search system improvements are often small and incremental like this, but we still want to incorporate new components if they are making search better.
To understand how strategies perform relative to one another within a given topic, we wanted to visualize performance across each topic. In this plot we show each strategy as a colored line across the 54 topics (x-axis) and again use nDCG@5 (y-axis) as the evaluation metric. At each topic there is dot that is colored based on the best performing strategy for that topic. In cases when multiple strategies tied for the best nDCG@5value, we consider the simplest strategy as the best performing one. So if mlt_base is tied with mlt_tune for best score, then mlt_base is considered the winner for that topic.
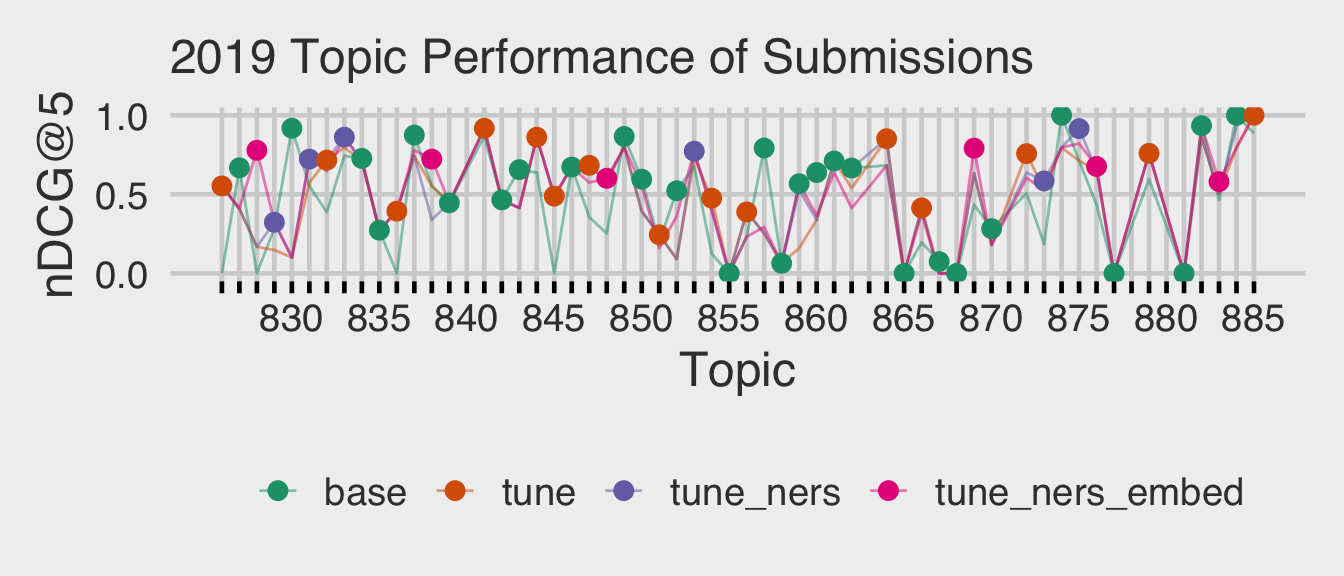
There are lots of topics where multiple strategies have similar performance. Overall there are many more green dots, indicating base was the simplest and best performing strategy for that topic. But there are several noticeable wins for our embeddings strategy (tune_ners_embed), topics 826 and 869. In these topics adding sentence embedding to the retrieval process provided a substantial performance lift.
This bar chart tallies the winning strategy for each topics where the best nDCG@5 value was greater than zero.
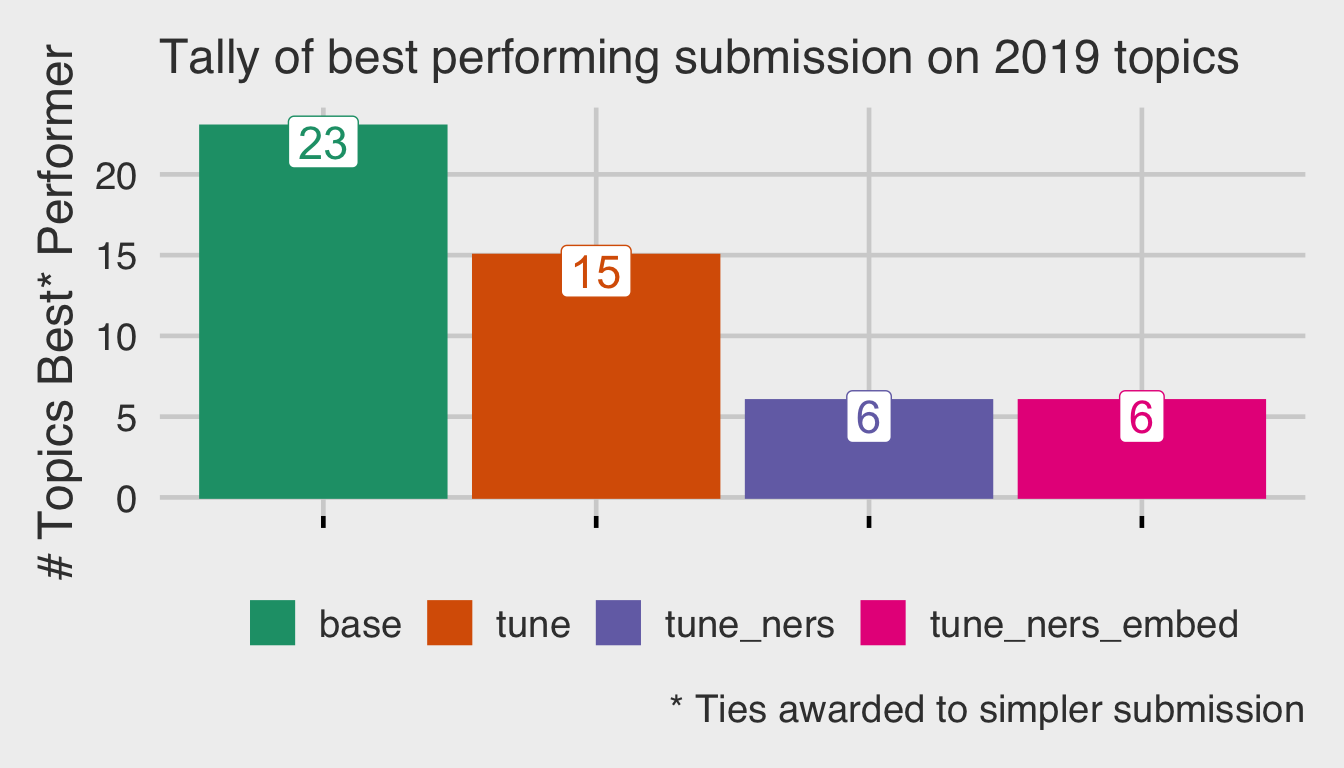
This confirms what we saw in the line chart above, out of the box MLT (base) does a good job. Building out strategies on top of MLT does help, so that was a good decision. We were able to improve performance with tuning and enrichment (ners & embedding) but not massively. Keep in mind this is an accuracy contest, we are not giving any consideration to query times. If we were, then base would probably be the best blend of accuracy and speed.
Elasticsearch is slick and embeddings are on the way
Elasticsearch is a highly optimized piece of software. It has sensible and robust default settings, that performed relatively well out of the box on this retrieval task. While were able to squeeze out better performance by tuning the settings and enriching our index, it’s important to consider the value/effort trade-off in doing so, especially with language embeddings.
Language embedding offers something novel and complementary to the dominant BM-25 based retrieval methods like MLT queries. Because of this there is a lot of hype-buzz around incorporating them into search systems. But the big search systems of today (Elasticsearch and Solr) were not built with embeddings in mind. The rush to retrofit these search engines with a first class embedding toolkit has begun. It’s an exciting time to be involved in search.
What’s next for TREC
Now we hope that this performance carries forward to the topics for 2020. We will get our submission’s performance before that and there will be another post in this series.
The actual conference will be virtual this year November 16th-20th. While we will get some preliminary results at the conference about how other non-OSC submissions faired, we have to wait until early 2021 to get the full dump of everything. One more good reason to look forward to 2021.