 Jeff Zemerick
Jeff Zemerick
Category: Natural Language
The topic of this blog post was the subject of the Searching for the Right Words: Bringing NLP to Apache Solr through ONNX and Apache OpenNLP talk at the Linux Foundation’s Open Source Summit North America 2022 in Austin, TX.
Introduction
Apache OpenNLP is a machine learning-based library for performing natural language processing (NLP) in Java. Apache OpenNLP provides common NLP functions such as tokenization, chunking, sentence detection, language detection, document classification, parts-of-speech tagging, lemmatization, parsing, and named-entity recognition. Natural language processing models can be trained by Apache OpenNLP and then used by the library in your Java applications.
Apache Solr features integration with Apache OpenNLP via Apache Lucene’s lucene/analysis/opennlp module. With this integration, Apache OpenNLP’s capabilities can be used from within Apache Solr to analyze documents during indexing.
Recent Advancements in NLP
With the recent explosion in capability and popularity provided by newer architectures such as transformers, there has not been a way to use these newer models with Apache OpenNLP. This has created a lack of NLP tooling in the Java ecosystem since nearly all modern NLP work is done in Python. Using state-of-the-art NLP models from a Java application often requires configuring a remote service to provide inference over an API. While this method works, being able to utilize the newer models directly from our Java applications would be more performant and easier to maintain.
ONNX, or the Open Neural Exchange, is a standard now supported by many tools and frameworks. It provides an open standard for machine learning models, along with runtimes for many languages, such as Java. With the ONNX Runtime, we can utilize state-of-the-art transformer models trained in the Python ecosystem from Apache OpenNLP.
Apache OpenNLP and the ONNX Runtime
To illustrate how this can be accomplished, let’s introduce a use-case. In this use-case we are performing document classification (sentiment analysis) on text. We selected a document classification model from the Huggingface models ecosystem that predicts the sentiment of text.
Converting a Transformers Model to ONNX and Getting the Model’s Vocabulary File
To use this model from Apache OpenNLP with Solr we must first convert it to the ONNX format. We can do this using the Huggingface transformers library.
python -m transformers.onnx -m nlptown/bert-base-multilingual-uncased-sentiment --feature sequence-classification exportedThis command converts the model to the ONNX standard as a sequence classification model. The output model file will be named exported.onnx. Now, we just need to grab the vocabulary file the model’s repository. You can either clone the entire repository (git clone https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment.git) or you can simply download the vocab.txt file from the model’s page.
With the ONNX model file and the vocabulary file we are now ready to use the model from Apache Solr via Apache OpenNLP. We will use the model to perform sentiment analysis on movie descriptions.
Using the Model in OpenNLP with Solr
We can use the model from Apache Solr by configuring an updateRequestProcessorChain using our new OpenNLPDoccatUpdateProcessorFactory. This factory exposes the model via Apache OpenNLP and allows us to perform inference using the model for each document we index. In the example below, we provide the path to the model file, the model’s vocabulary file, the source field, and the destination field. The model will perform inference on the content of the source field. The destination field will then be populated with the result of the inference. In this case, the value of the destination field will be a sentiment classification.
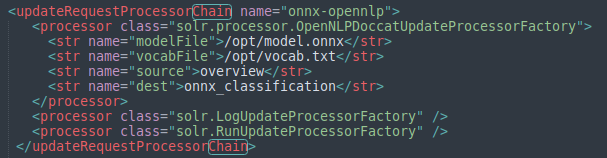
We also define our destination field:

Now, when we index a document, the document’s onnx_classification field will contain the sentiment as determined by the model:

ONNX & OpenNLP with Solr – The Code
The code for this is available in a GitHub repository. The ONNX Runtime support was added in Apache OpenNLP. At the time of writing, there are open issues to integrate Apache OpenNLP 2.0 into Apache Lucene and Apache Solr. Please see the code repository for more information on those efforts. If you would like to contribute to the effort please reach out to me! All help is welcome and appreciated.
If you need help using OpenNLP with Solr to drive more relevant search do contact us.
Image by Smiley Icons Vectors by Vecteezy