
Introduction
Why do we need relevance evaluation?
If you want to improve your search algorithm you need a way to measure your tuning changes, that means gathering relevance feedback. No more LGTM, get numbers and quantify it.
“In God we trust, all others must bring data.”
W. Edwards Deming
Why explicit relevance evaluation?
Explicit evaluation is the most direct way to get numbers that quantify your search relevance. Compared to implicit evaluation (often based on click data), it requires less investment to get started and is a stronger signal directly from a domain expert. Simply put, you ask people to manually rate the quality of search results (you could use a tool like Quepid).
How do you succeed with explicit relevance evaluation?
One critique of explicit evaluation is that it is expensive to scale, because it requires humans in the loop. It’s this time consuming factor that can make pursuing explicit judgments intimidating. Questions like these can cause you to stumble before you’ve even begun:
- How many queries do you need?
- Are those queries representative of your site traffic?
- Do they reflect the information needs of your users?
- How long is this going to take?
This blog lays out practical applied answers to each of those questions, so you can swiftly and successfully start and run your own relevance experimentation environment.
How many queries do you need?
Fifty, at least to start. The only way to really tell how many queries you need is after all the relevance labels are collected, with a post-hoc power test, but in my experience fifty is plenty. Fifty is also widely used as the sample size in TREC (Text REtrieval Conference) tasks, which is why I started using it.
This doesn’t mean you won’t use multiple batches of queries eventually, but for collecting and managing them as chunks, fifty is a good size and a great place to start.
Are those queries representative of your site traffic?
The best way to ensure good representation is through probability-proportional-to-size sampling (PPTSS) of your real site traffic. By using your real site traffic you ensure you are reflecting real user needs and by using PPTSS you are reflecting the “importance” of more frequent queries.
This isn’t to say you can’t still use cut-off values – maybe your top 50 queries deserve specific ranking rules, or maybe you don’t want to see any queries that appear less than 10 times. That’s fine, go ahead and leave those out of the population of queries to be sampled. However, PPPTS does a better job representing the real world variation among queries compared to naive simple random sampling (SRS).
Consider this example in bar charts:
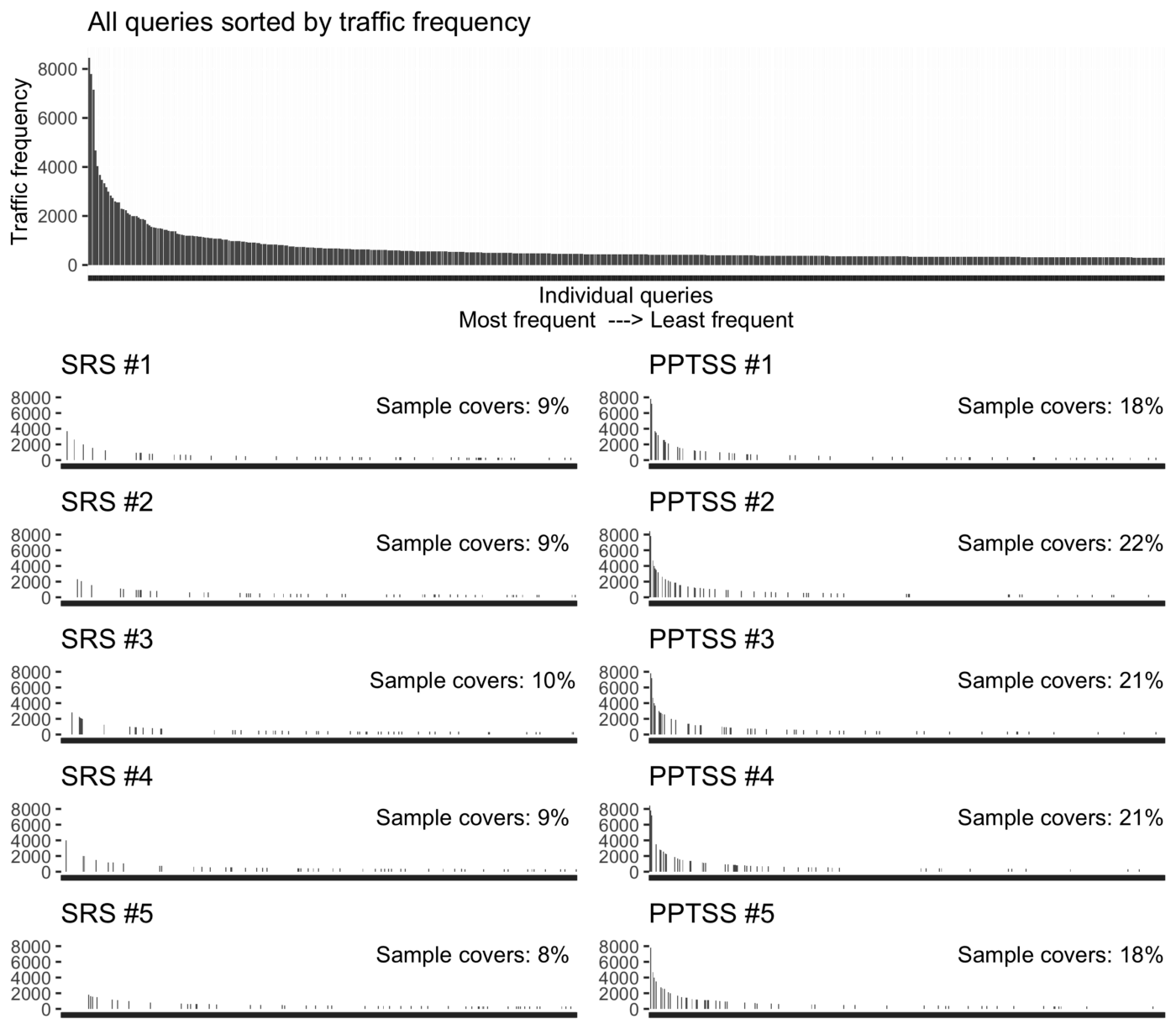
You can clearly see PPTSS favoring high frequency queries, while SRS does not. This means the samples are mirroring real site traffic.
Because you are still sampling, you still select some of the less frequent queries (note the little bars/ticks all the way on the right of the x-axis in the PPTSS samples). This is why sampling is always better than selecting windows like top-N. Sampling gives you a chance to see all of the queries and PPTSS gives you the best representation of that “chance” of an individual query in your search traffic. This linkage is critical, to make sure what we measure with explicit judgments is representative.
Do they reflect the information needs of your users?
Now that your query sample is reflecting relative query importance, we need to confirm these are good queries for collecting explicit feedback. This is a manual QA review of the sampled queries, where you throw out specific queries. Queries can be tossed out for any reason, but as a guideline I think you should reject queries if they are either:
- Too generic, ambiguous, e.g. [
“2”, “buy”] - Rule applied e.g. using Querqy or another rules engine to override ranking
- Not applicable to inventory/sector e.g. bot traffic looking for graphics cards on an electronics store website
As the domain expert for your site search you have some creative leeway here. Anything that doesn’t represent a user information need that you can easily define should probably be thrown out. Our end goal is to have a sample of queries that we can confidently rate the results for. Depending on how many queries you toss out, you should go back and re-sample to get roughly 50 good queries, 48 is okay – but only 28 is pushing it.
How long is this going to take?
We’re almost ready to rate now. The last thing we need to do is define the information need (what makes a result relevant) for each of the queries. Assuming you ended up with 50 queries this takes about 1 hour for a user expert and catalog expert working together.
After information needs are recorded we are ready to rate. If you are comparing two rankers at a depth of 5, this means you will collect 500 explicit judgments, (50 queries) x (2 rankers) x (5 documents). Collecting judgments is pretty fast with information needs predefined. I estimate an evaluator can do 5 ratings per minute, or 1 hour and 40 minutes to do the whole set. If you split up the work with a colleague, that’s only 50 minutes.
Not too bad for your very own test collection! Now you can fairly quantify the performance difference between two rankers and be confident you are fairly representing your actual site users, isn’t that lovely?
If you need help building your search quality evaluation process we can help – get in touch today.