
 Charlie Hull
Charlie Hull
Category: Learning-to-rank
We’re pleased to present a guest blog on field boost tuning from Vsevolod (Seva) Goloviznin & Roman Grebennikov of the Metarank team.
Tuning per-field boost weights is a popular technique for improving the relevance of search results: it seems to be intuitive that a keyword match in an item title is more important than a match in the description field. But this approach often creates more questions than answers:
- How to efficiently find a perfect combination of field boosts?
- Does this combination have seasonality changes, and how to re-adjust for it?
- How to introduce some external knowledge about items in the ranking, like per-item click-through rate?
In this article, we discuss common approaches to field boost tuning for Elasticsearch/OpenSearch/Solr and how Metarank gives another perspective on this problem.
Field boost tuning fundamentals
Imagine that we’re building a movie search application over a dataset of thousands of documents having the following field structure:
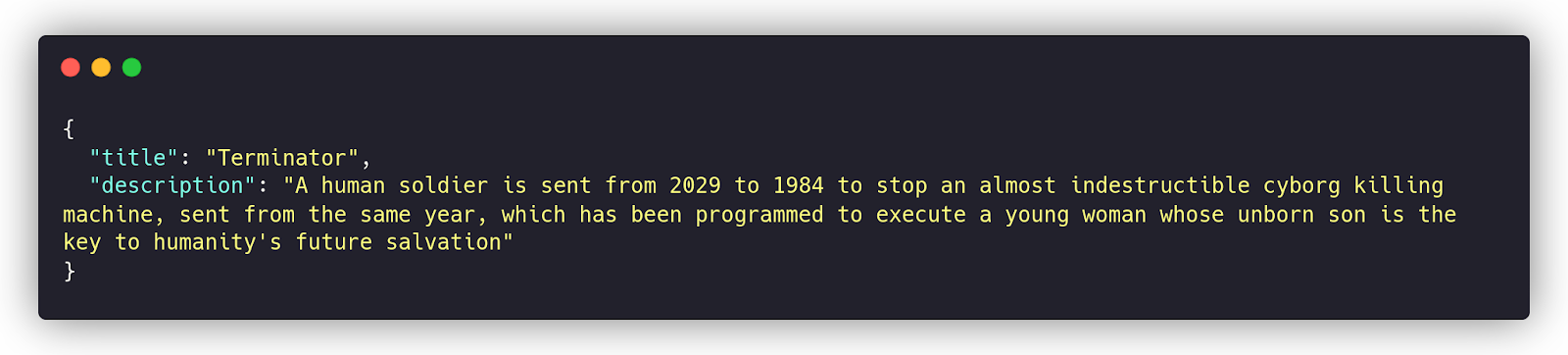
These two fields have different influence on search results:
- A match over the title field has a high precision (so if we search for “terminator”, we will definitely find some good matches), but low recall (the query “terminator” won’t match other relevant movies)
- The description field usually has much more keywords so that it may give you high recall (so many matches), but with low precision (these matching movies may not be highly relevant for the query)
The idea of field boost tuning is to find a balance between search precision and recall, to make precise but infrequent matches over the title field be ranked higher than imprecise but diverse matches over the description field.
For Elasticsearch, we can make the following query:

“title^10” means that the match over the title field has 10x more weight than the match on the description field. But if you have multiple searchable fields, how do you choose the best combination of weights?
How to measure relevance?
By asking for the best combination of field boosts, we need to understand which metric we optimize for. There are a lot of business search metrics in the industry with a great overview article How to measure the quality of your site search by Klevu (another reference is the OSC article Interpreting Google Analytics for Site Search):
- A number of search refinements: how many attempts to write a good search query did the visitor make before clicking on a relevant item?
- Search bounce/exit rate: how frequently has a visitor abandoned the search page?
- Zero results rate: how often a visitor found absolutely nothing?
But all these metrics are aggregated by time and can only be computed over the large set of search sessions, only implicitly measuring the same underlying search relevance. There are low-level and more granular metrics, for more details you can check the blogs Choosing your search relevance metric by Nate Day of OpenSource Connections and Search quality metrics: what they mean and how they work:
- MRR: Mean Reciprocal Rank. What is the average position of the first relevant result? Doesn’t take into account multiple relevant results.
- MAP: Mean Average Precision. What is the rate of relevant items on the search results page? Doesn’t take into account positions of relevant results.
- NDCG: Normalized Discounted Cumulative Gain. How is the current search ranking different from a theoretically perfect ranking?
NDCG is more widely used across the industry as a metric considering both position and the number of relevant results on the search page.
Walking in the dark
The most common approach to relevance optimization is what we call the “walking in the dark” methodology:
- Change boosts according to horoscope, moon phase and weather conditions [Editor’s note – we wouldn’t recommend this approach! :-)].
- Measure metric improvement in an A/B test.
- If metrics improve, then assume that the current boost combination is better than before.
- Go to point #1 and repeat.
This approach is highly intuitive and has a visible feedback loop: you observe the improvement in target metrics during the experiment and can even feel their impact. But this way of doing things also has several drawbacks: it takes a lot of time to validate a single experiment, and there is no clear way of defining the next candidate for the A/B test.
But Elasticsearch boosts are nothing but coefficients in a linear regression:
score = title_boost * title_bm25 + desc_boost * desc_bm25
Suppose we log BM25 per-field scores for all the queries we perform in production, and use visitor clicks as relevance labels. Then we can in theory reduce the whole boost optimization problem to a simple regression problem.
Originally this idea was presented in a Haystack US 2021 talk by Nina Xu & Jenna Bellassai:
As proposed in the talk, we can use session-level click-through data as a training dataset, and analytically choose the best boost value combination to minimize a pairwise loss (which in theory should improve the NDCG):

The main advantage of this approach is that the best combination of weights can be found analytically in a single step, with no need for a time-consuming sequence of repeated A/B tests.
And the optimal field boost values combination can be easily plugged into the production Elasticsearch cluster without using any extra plugins to alter the ranking.
Implementing learn-to-boost
The learn-to-boost approach with field boost weighs regression optimization sounds like a typical Machine Learning problem. But unfortunately to start doing ML, at first you have to build a data collection pipeline:
- Search result impressions and clicks logging: which items were displayed to the visitor, and how they interacted with the ranking
- Which per-field BM25 scores search results had? It can be computed online as a part of the previous query logging stage, but may require sending a lot of extra queries to the Elasticsearch cluster. To prevent this, per-field BM25 scores for each query can be computed later in an offline mode.
- Generate pairwise labels, and fit the regression model to find optimal boost values.
To log search impressions and clicks, we need to add instrumentation support for the application backend, store the telemetry somewhere and write a lot of ad-hoc Python code to glue things together.
There is nothing wrong with ad-hoc glue Python code apart from that it requires a lot of time to be written and tested properly. And as a problem of better ranking is not unique, it would be great if we can leverage existing open-source tools to automate the most boring parts of the data collection process.
Deep vs shallow reranking
Field boosts is a way of doing relevancy optimization by combining retrieval and ranking together within the same stage. In the case of Elasticsearch, we iterate over all matched documents, score them, and collect top-N results in a single pass.
- Main advantage of such an approach is that it can easily rank millions of documents.
- But as your scoring function is going to be executed for each matching document, it should be extremely light-weight not to cause any latency issues. Linear regression is OK, but neural networks are not a good fit yet.
Using field boosts is a great example of a deep ranking approach, when only a single ranking function is applied to the whole list of matching documents.
But in practice, the typical BM25 score distribution in search results is not as even as you might expect: there are a couple of highly relevant documents on the top, and a very long tail of partially relevant documents at the bottom.
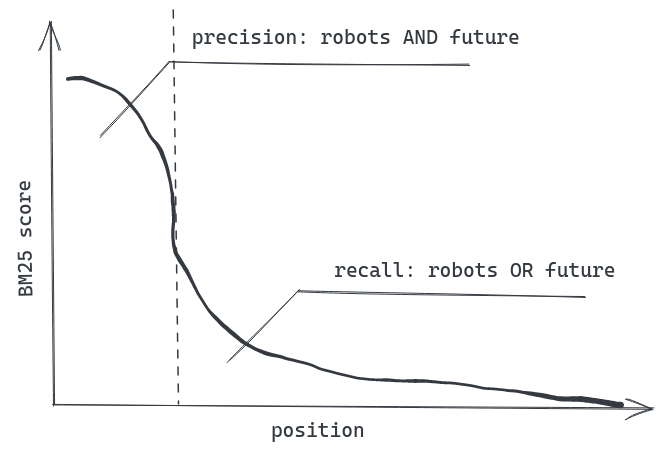
And even if you tune field weights a lot, most probably there will be almost the same search results on the first couple of pages, but with slightly different ordering. A chance that an item from page 100 will be boosted to page 1 is quite low in practice.
To solve the problem of simplicity/complexity of the scoring function, there is a hybrid approach of shallow reranking:
- You use a lightweight simple ranking function to perform an initial ranking. Top-N of partially relevant candidates are chosen, with the focus on recall.
- For the top-N items you do a secondary reranking pass with a more heavy-weight function, focusing more on precision.
It brings the way of using heavyweight ML-based ranking methods on the table, but still with a couple of drawbacks:
- The deeper your reranking is (so N in top-N is bigger), the higher is the end latency.
- The more ranking factors you use, and more complex ranking function you choose, the more time it will take to evaluate it over your top-N candidates.
Shallow reranking with ES-LTR
A shallow reranking approach needs extra tooling and custom data pipelines, as you need to:
- Log which documents were presented to a visitor, and which clicks the visitor made.
- Replay the search-documents history offline to compute per-field BM25 scores.
The Elasticsearch Learning to Rank (ES-LTR) plugin created and maintained by OpenSource Connections is a widely-used solution to do ML-style ranking on Elasticsearch and OpenSearch. You can define a set of separate per-field “match” ranking features:
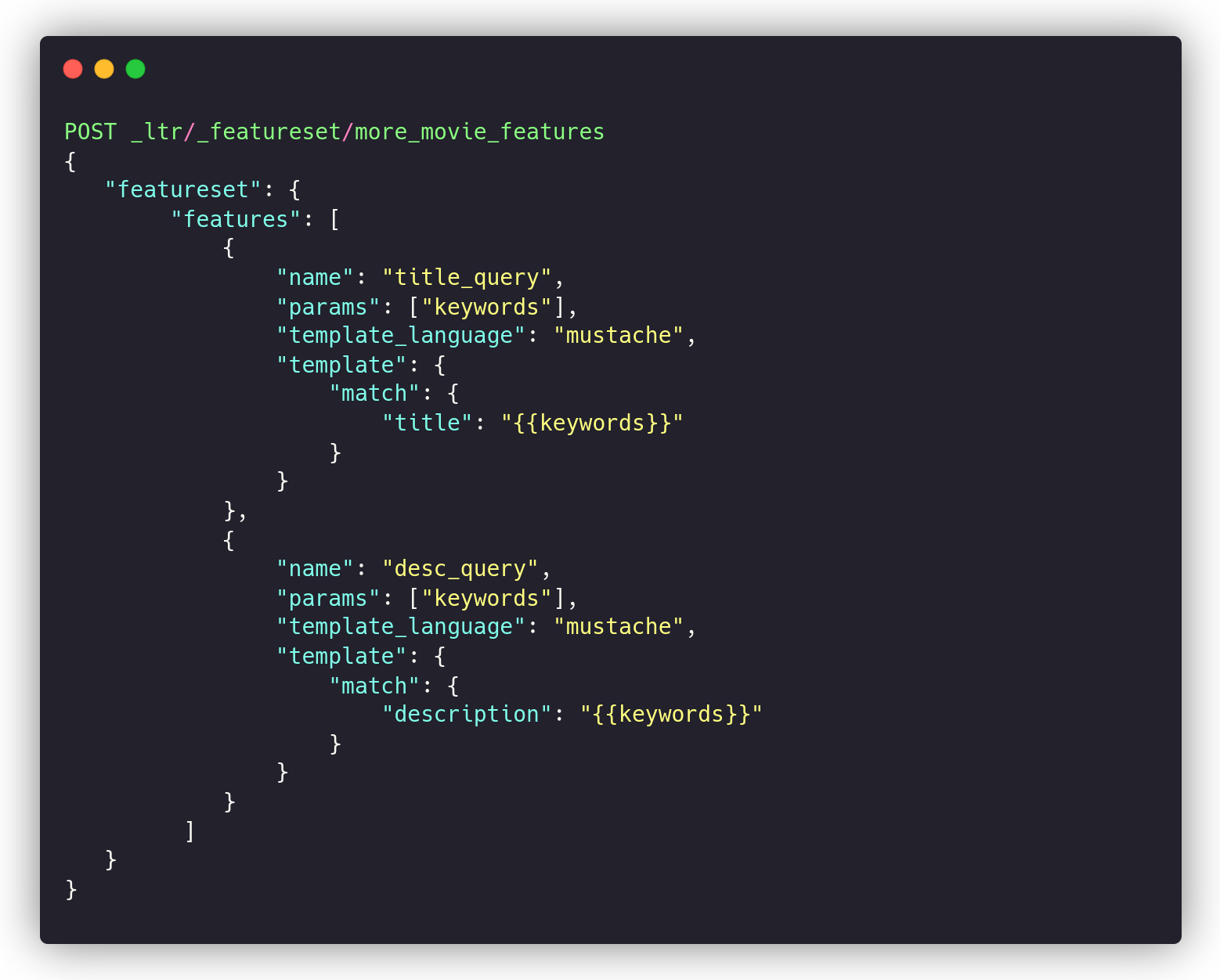
And each time you perform a search query, ES-LTR will log it with the corresponding ranking feature values into a separate index.

Later you can join it with the judgment list, and optionally train a XGBoost model for a LambdaMART-based ranking with ES-LTR.
Almost the same solution can be built not only using classical search engines like Elasticsearch/Opensearch, but also with vector/hybrid engines like Vespa as described in the article Improving Product Search with Learning to Rank.
There are some subjective opinions in search community that the approach of ES-LTR to store feature logs directly inside of an Elasticsearch index works great on a smaller scale but may cause performance issues on 1k+ requests per second:
- Instead of serving a single read-only search request, the Elasticsearch cluster needs to also index a new feature log document. And indexing is a much more costly operation than search.
- Invoking a XGBoost model directly inside of the Elasticsearch cluster is also expensive, especially when doing deep reranking. Although there is a way to use ES-LTR in a shallow reranking mode.
Going with ES-LTR automates some of the major parts of the LTR journey like feature logging and model serving, but you still need to write extra ad-hoc code to perform click logging, join these logs with stored feature values, and train the actual ML model.
Shallow reranking with Metarank
Metarank is yet another take on implementing shallow reranking and Learning-to-Rank for search, heavily inspired by the ES-LTR ideas, but designed to be independent of the retrieval system. It’s not a Elasticsearch/OpenSearch/Solr plugin, but a separate search-agnostic service.
In this section we will go further into automating a better ranking setup:
- We’ll use Metarank’s event schema for telemetry logging and collection.
- Apply field_match feature extractor to detect a per-field impact on the best ranking. It’s not going to completely match the BM25 score, but can be implemented offline and without the actual Lucene index.
- Train the ML model and play with Metarank’s inference API for secondary reranking.
The overall integration overview is shown on a diagram below:
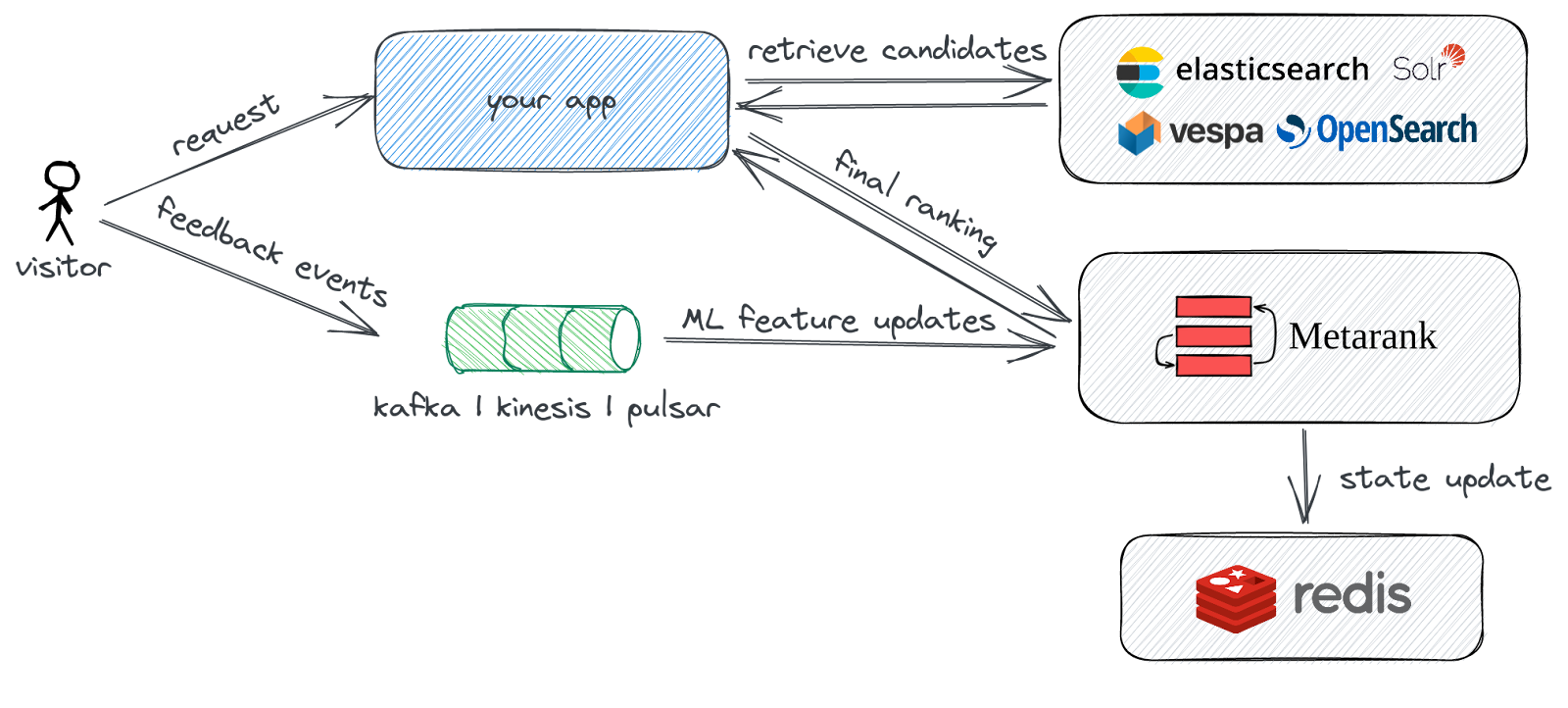
Impressions and clicks telemetry
Metarank defines a very generic schema of telemetry events. For example, when a search impression happens, your application should emit a “ranking” event downstream:
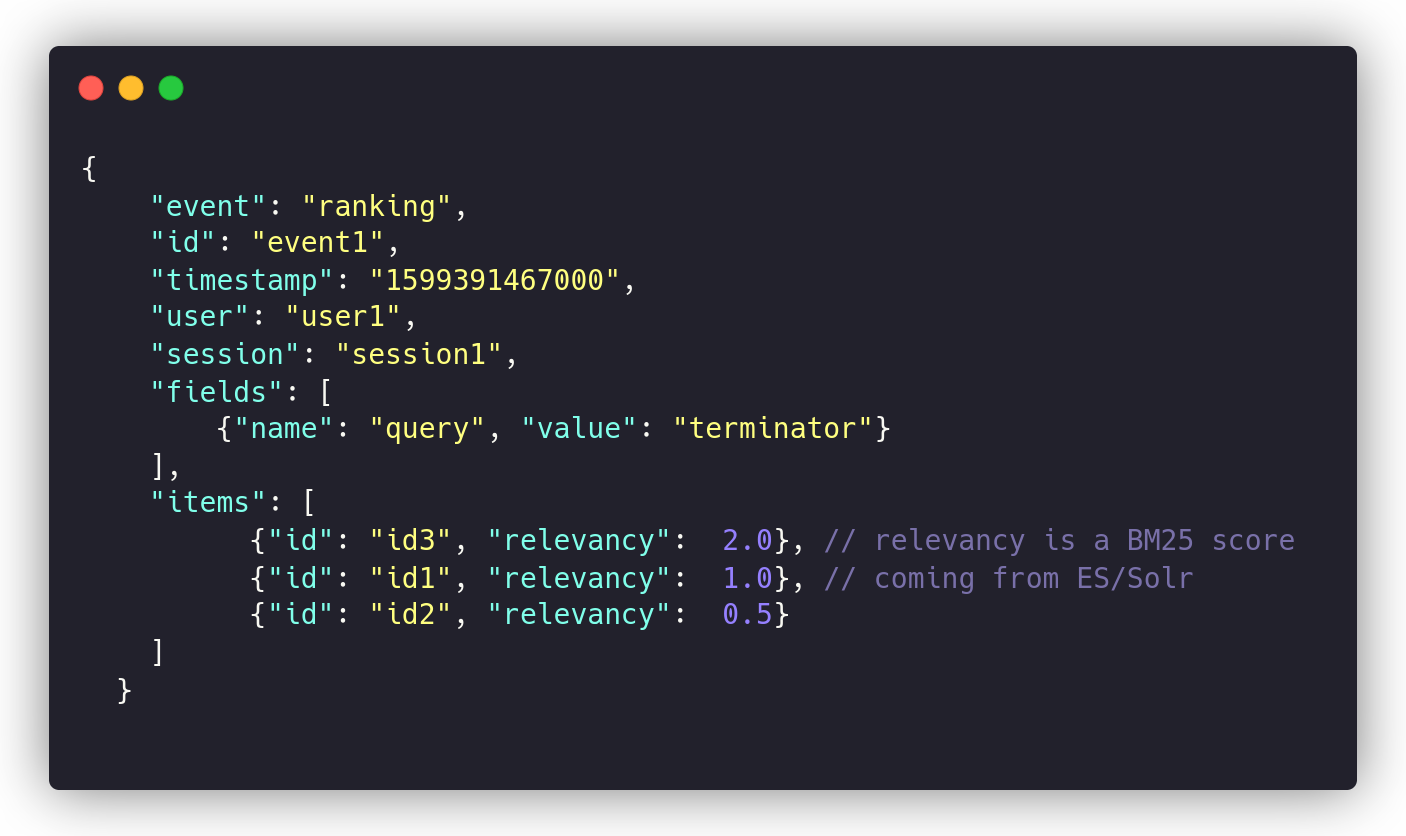
When a visitor clicks on the search results they examined, then the “interaction” event should be emitted:
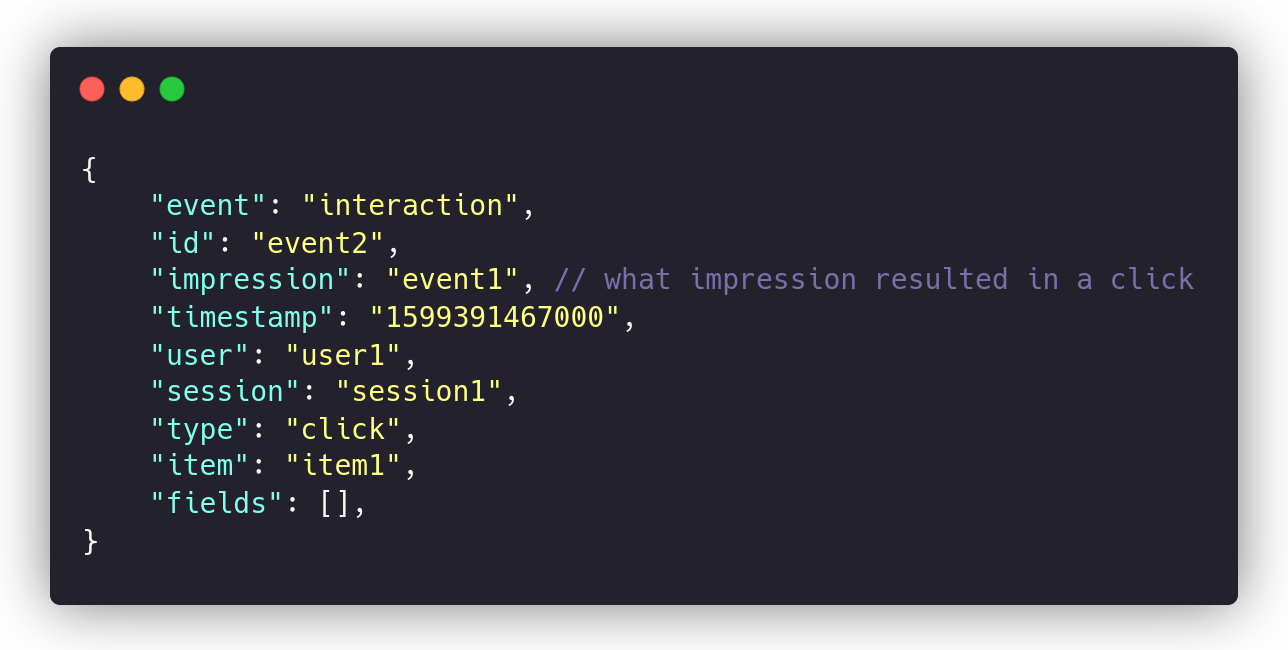
Metarank is not part of your search engine but a separate service. You should also notify it of item metadata changes. The same way you do with an indexing pipeline, when an item changes, you emit a message downstream:

Logging a telemetry stream of such events will allow us to reconstruct the complete click-through at any time in the past.
Transforming fields to ranking features
Metarank is designed to solve the most tedious and typical relevancy optimization tasks. For the case of field boosts optimization, it has a field_match feature extractor (https://docs.metarank.ai/reference/overview/feature-extractors/text#field_match).
We can define our field-matching ranking feature for the title field in the following way:

With this definition, Metarank will compute a tri-gram intersection-over-union score (called a Jaccard similarity index) for the search query and the title field.
We can also define a similar setup for the description field:
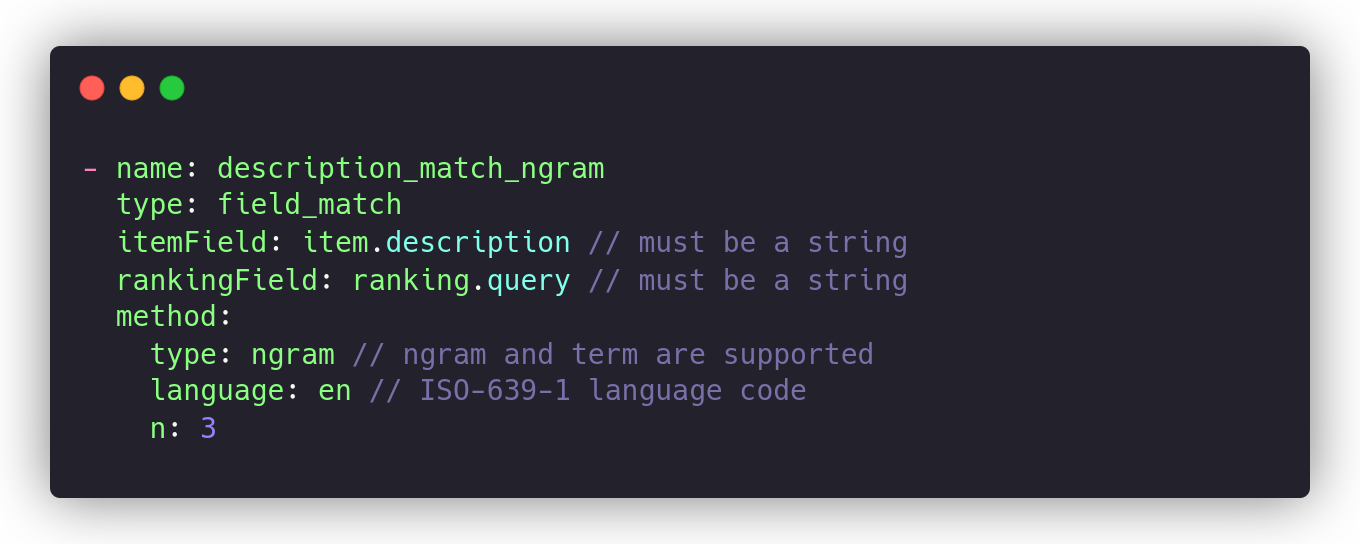
The n-gram Jaccard index is an excellent approach to computing the difference between similar words, but it may produce too many false positives. With Metarank, we can go even further and compute JI over language-specific Lucene-stemmed terms in the following way:
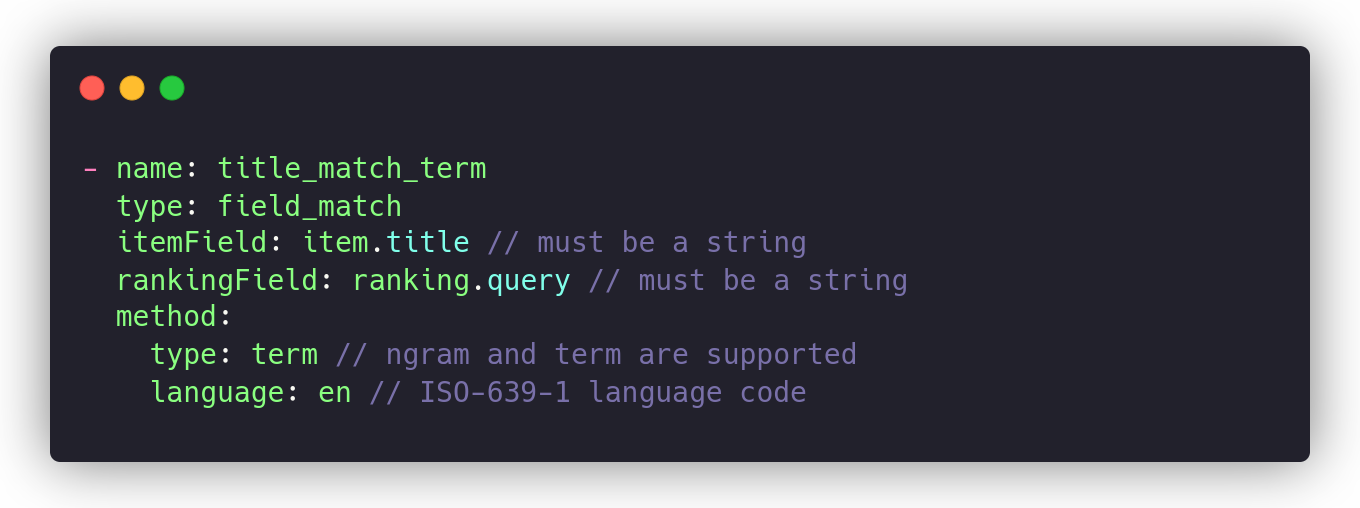
As a last re-ranking feature, we can take the BM25 score from the upstream search engine in the ranking.items[].relevancy field:

Such a combination of ranking feature extractors approximately reproduces a typical field boosting setup, but with an extra advantage of mixing together ngram and term matching without full reindexing.
Training the ranking ML model
When you import historical click-through events into Metarank, it will do the replay of all the ranking activity and generate implicit judgment lists.
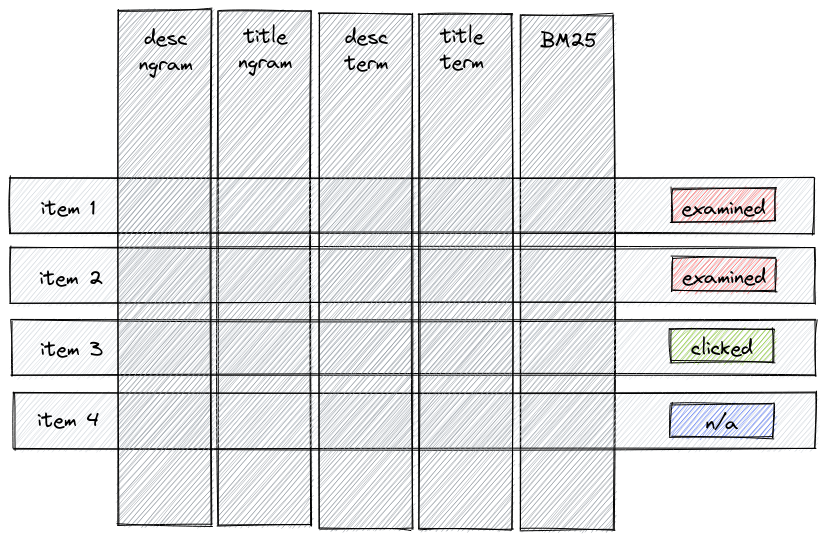
Metarank will later feed these judgment lists into the underlying LambdaMART model, which will learn how dependent variables (like per-field term/N-gram scores and BM25) affect the ranking. Compared to a traditional logistic regression approach, LambdaMART:
- Can handle correlated features. In our case, term and n-gram similarity features will probably be highly dependent on each other, which may make the regression formula less stable.
- Takes into account the positions of items. LambdaMART optimizes for the best NDCG, so it is also sensitive to positions and the number of relevant items in the list.
Metarank supports both XGBoost and LightGBM LambdaMART implementations. However, due to significant differences in how the actual gradient boosting is handled in both backends, you may observe different ranking for each implementation even trained on the same dataset.
Metarank vs ES-LTR
Metarank is doing a similar job to ES-LTR, but goes a bit further on automation and operations UX:
- All the feature logging happens outside of the search cluster, so reranking does not affect its retrieval performance.
- There is a wider library of typical behavioral feature extractors widely used in practical LTR setups: CTR/Conv rates, position de-bias, UA/Referer parsing, rolling-window counters, etc.
- Metarank also handles implicit judgment list management and ML model training, so you don’t need to perform any manual steps to serve a ML-based ranking model.
- And a crash inside of Metarank won’t crash your Elasticsearch cluster, as you can always fall-back to a non-LTR ranking coming from Elasticsearch.
Secondary reranking in production
Metarank is a secondary reranking service which only reorders a list of candidates retrieved by a first-level search system.
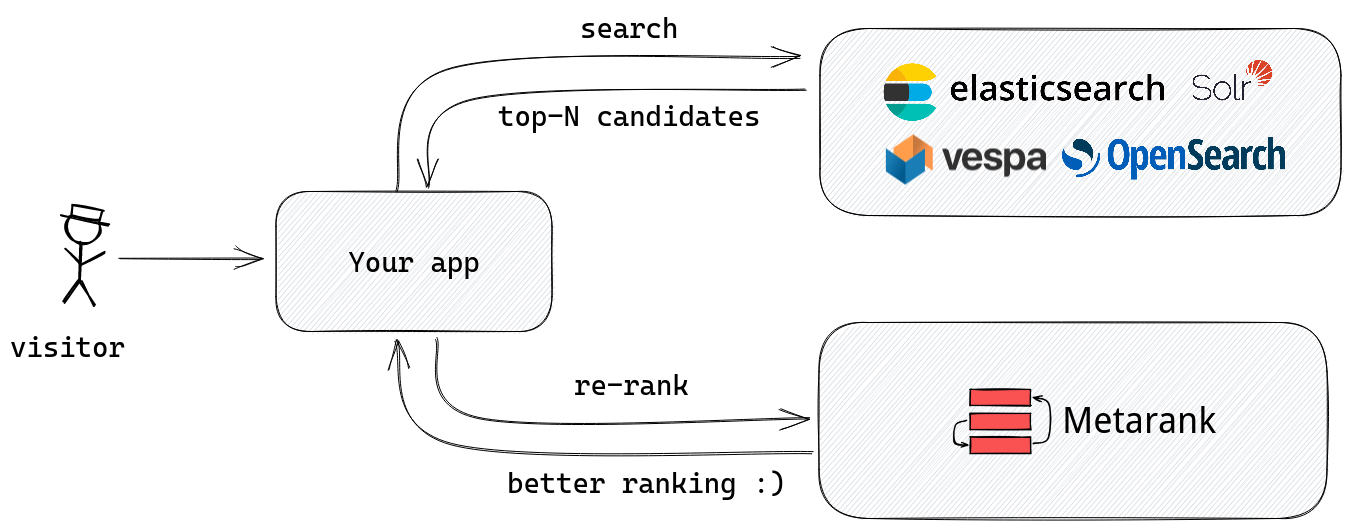
The API integration and deployment of Metarank is a straightforward process, as it’s a simple stateless JVM application using Redis for persistence. To do the actual reranking, you send a request to the /rank endpoint:

And Metarank will reply with a set of per-item scores:
As a secondary re-ranker, Metarank needs a set of top-N document candidates. The N value can be pretty significant in practice, like 1000 and more, but if you expect to have more than 1K search results, the Metarank approach will give no chance to low-ranked items to be promoted to the top.
This makes it extremely important to have a solid relevance baseline in place as this ensures that relevant results will be retrieved within the first N hits which in turn can then be reranked by Metarank for better precision.
In conclusion: Deep, fast, precise – choose any two
There are three functional characteristics of different ranking approaches:
- Depth: can you handle 1M matching documents at once?
- Speed: can you serve all search queries within a defined latency budget?
- Precision: how relevant are your search results?
In reality you can only choose two options out of three, unfortunately:
- The Learn-to-Boost approach from the first chapter of this article is deep and fast, but not precise as it cannot handle non-linear combinations of ranking features. In practice, models like LambdaMART are more stable and resistant to noise, scaling issues and internal correlations in the dataset.
- The ES-LTR and Metarank are fast and precise, but not deep: there is no cheap way to apply it to listings with 1M documents. Invoking a LambdaMART ranking function from XGBoost requires loading all per-item ranking features at once from the ES index, which can be computationally expensive. In practice, there are not many cases where you need to re-rank tens of thousands of items and implementing multi-stage ranking can be an optimal choice.
- ES-LTR doing a full reranking can be deep and precise, but slow on large document lists.
There is no silver bullet, but it’s great to have a couple of options to choose from.
Thanks to the Metarank team! If you need help evaluating ranking methods for your search application, get in touch.
Image from Boost Vectors by Vecteezy