
The search engine GPSN has fairly static dataset of Chinese patents that is delivered via roughly 5 TB worth of very large ZIP files. The data for each patent is split among various zip files for English text, Chinese text, and image files. And each has its own vagaries of how they are stored. We wanted to be able to query for files and find out what Zip archives they were stored in when debugging issues that have arisen in matching all the data files up. We ended up using Solr to save us configuring some sort of more traditional database since this was the only use case, though at times I wish I had something a bit more expressive to work with!
Well today I finally got to grips with putting a script together that would go over all the stored data and check it for various error conditions that we have identified over the course of the project. Initially the data_audit index was both what I was querying for my information about where a patent might have gone, and updating the associated metadata. The commits are set up to every 15 seconds, and queries were easily taking 15 to 20 seconds to occur under some decent, but not silly, amounts of load due to the the constant commit activity, and the caches never having a chance to fill up.
So I refactored my audit code to have two properties, a solrDataWriter, which would be my primarily Solr index, and then a solrDataReader, which would be a clone of my data_audit index.
I didnt want to go through the leg work of stamping out lots of Solrs, but fortunantly my colleague @omnifroodle had been working on over the past two months some Amazon CloudFormation scripts for SolrCloud. While still raw, they are available at http://github.com/o19s/cfn-solr.
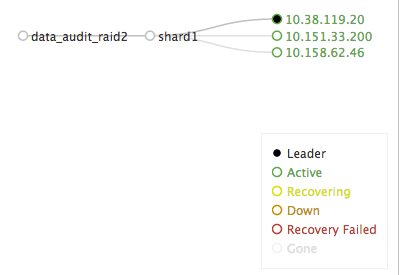
I ran the CloudFormation template and stood up 3 SolrCloud servers. I then put my data_audit conf directory into ZooKeeper and created a single shard with two replicas. I was thinking of it being like RAID levels, in my case I only wanted performance of reads, minimal work to setup, and am not worried about writes being propagated.
Next was how to get the data over? Well, replication has always been one of my favorite tools. So I used curl and copied the data over:
curl "http://ec2-68-202-9-80.compute-1.amazonaws.com:8983/solr/data_audit_raid2_shard1_replica1/replication?command=fetchindex&masterUrl=http://ec2-23-21-214-112.compute-1.amazonaws.com/solr/data_audit"Now, Replication is actually meant in SolrCloud -land to manage moving bulk amounts of data from the leader shard to the replicas when things get out of sync, or to update a new replica, but invoking it manually seemed to work as well. The GUI doesnt show all the details, so browse the replication handler directly to monitor the progress:
http://ec2-68-202-9-80.compute-1.amazonaws.com:8983/solr/data_audit_raid2_shard1_replica1/replication?command=detailsI did hope that if I replicate to the leader shard, it would in turn replicate to all the follow shards, but no joy.