
I have a concrete counter top in our kitchen that is rather different from most concrete counter tops because it is coloured with a thin surface layer of multiple shades of concrete dye all mixed together. It has a wonderful earthy look to it, but Ive discovered that it doesnt stand up very well to my wife swinging around heavy pots and pans!

Scuffs on concrete countertop
I tried a sanded grout with the brand name “Mapei” from Lowes Home Improvement, but it didnt really have the effect I wanted, leaving a very textured patch that doesnt take the concrete sealer that makes the counter look shiny.

Patching the countertop with the sanded grout. Not so good.
So I went onto Lowess website and searched for Mapei Unsanded Grout, and received back 30 results:
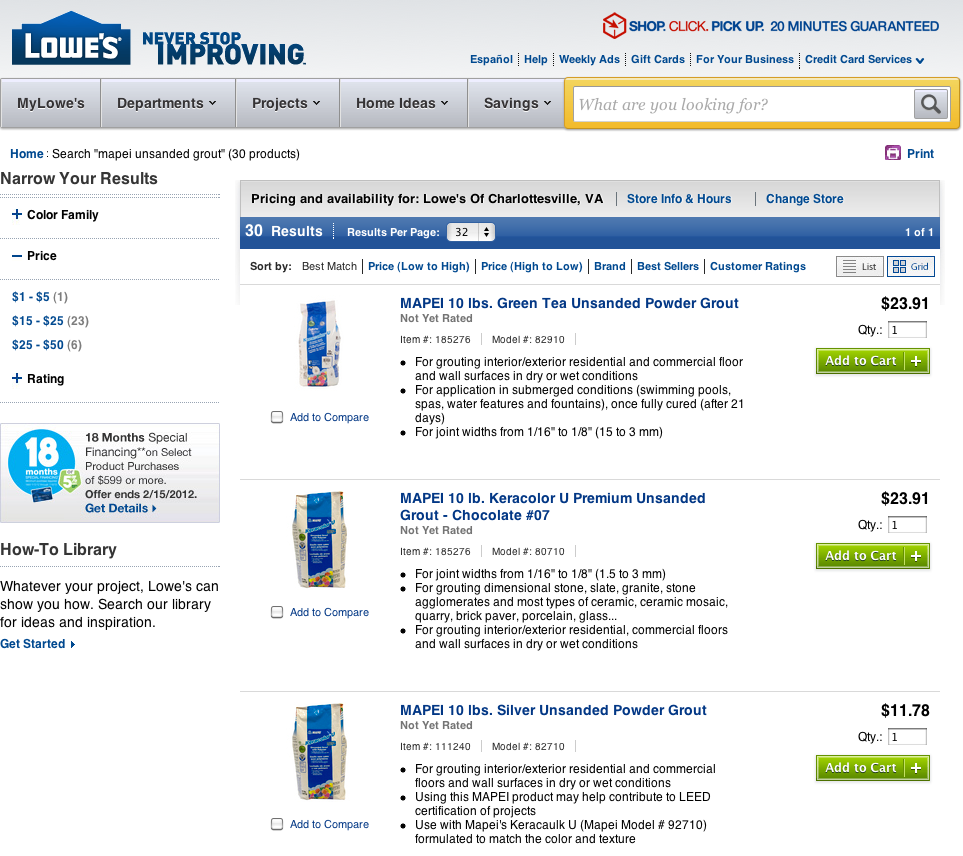
Lowes search results for Mapei Unsanded Grout
While on the face of it, 30 results for my query sounds like a great thing, when I scrolled down the page I was overwhelmed by all the choices! It seemed like I had 30 different choices to pick from. Go ahead, click the link to search Lowes.com and try it yourself!
I scrolled up and down a couple of times and started realizing that I didnt have 30 choices. I actually had TWO choices: a “Unsanded Powder Grout” and a “Premium Unsanded Powder Grout”, and they come in a variety of colors and sizes. So here I am, frantically scrolling up and down trying to build a mental model of all my choices, when I think “ah, facets should help me narrow down my choices”. I knew I was doing just a bit of patching of the countertop, so I wanted the smallest amount of grout possible. And I knew I wanted a rich earthy red/brown color to match the existing concrete counter top. Unfortunately “Size” is not a facet option offered by Lowes.
So I thought, instead of trying to build a mental model of all thirty results in my head, why dont I leverage clustering to see if I can pull out of the unstructured data some shared clusters that could act as facets? This blog post and the accompanying code are going to walk you through the steps I took. All the links assume you have Solr running on your localhost.
1) Extracting the Data
I wrote a very simple Ruby script that queries Lowes.com for “mapei unsanded grout”, and parses out the results and stores them in a Solr index. Fire up Solr by running ./start.sh. Then run the script ruby download_lowes_data.rb. Warning, you may have to install some gems!
2) View the Clusters
I leveraged the Solr built in UI Solritas to expose the data about the clusters. Browse to http://localhost:8983/solr/browse to see the results of clustering the data:

Its not very exciting at this point. Ive told Solr to cluster primarily on the title, and secondarily on the product detail bullets. And it has accurately identified that there are a number of grouts that come in the 10 lb. bag. And that we have some premium grouts. More useful clustering would be to seperate out those that are 10 lb., and those that are 25 lb. Although, one thing to note is that by clustering, we did successfully extract the root product title for two of the items, and dropped the color name portion. The products titled MAPEI 10 lb. Keracolor U Premium Unsanded Grout – Lt.Almond #49 and MAPEI 10 lb. Keracolor U Premium Unsanded Grout – Chocolate #07 both have the correct root title of Keracolor U Premium Unsanded Grout in the clustering list.
3) Adding in Facets
I had turned on faceting on for the Item Number and Model Number fields, and set the minimum facet count to display to 2 because I only care about item numbers or model numbers that are shared by multiple products. While each product does have a unique Model Number, what was interesting to discover was that there are 14 out of the 30 products share the same Item Number: 185276. It appears that Item Number is assigned by the manufacturer, not Lowes, and identifies a single product, regardless of size or color choice, while Model Number is the unique SKU for that product.

I clicked the Item # 185276 facet and my clusters started looking much more interesting:
!https://img.skitch.com/20120302-nq69pr7uqppe4886cumgiwsagb.png!
I now have 5 clusters identified: Unsanded Powdered Grout, Keracolor U Premimum Unsanded Grout, MAPEI 10 Lbs, MAPEI 25 Lbs, and Help Contribute to LEED Certification of Projects. The first four clusters all look really useful as discriminators, as I can see that I have a set of products that are 10 lb., 25 lb., and either the Unsanded Powder Grout or the Premium Unsanded Grout. Even the fifth facet about LEED certification could be useful in helping me identify products that contribute towards LEED certification. One thing I noticed though was that the total unique number of clustered items didnt match the number of products returned by the faceted query. Turns out the clustering results are returned via an AJAX call to the /clustering handler, and it has a limit of 10 rows. So I bumped it up to 100 so that the results of clustering would be over all the documents returned, not just the top 10. Here is the configuration from solrconfig.xml:
true default true title_t id product_bullets_txt true false edismax text^0.5 product_bullets_txt^1.0 title_t^1.2 model_number_s^1.5 item_number_s^1.5 id^10.0 *:* 100 *,score clustering 4) Playing with Clustering Options
The /clustering request handler makes it easy to play with the various clustering options. The clustering output is below the
http://localhost:8983/solr/clustering?&q=:&fq=item_number_s:%22Item+%23%3A+185276%22
The primary source of data is the title, followed by the product bullets. If we disable the carrot parameter for summarizing the product bullets carrot.produceSummary=false, we get more clusters:
including clusters for Brick Paver and Glass and Clay Tiles. Its great that there are more clusters, but you can see they become less interesting unless you are specifically looking for those things.
Another way of filtering down the volume of suggested clusters is to only cluster on the title field by blanking out the snippets field by setting carrot.snippet= to be blank:
http://localhost:8983/solr/clustering?&q=:&fq=item_number_s:%22Item+%23%3A+185276%22&carrot.snippet= (notice the carrot.snippet= param to blank out snippets) removes the clusters based on the product bullets like Help Contribute to LEED Certification of Projects.
Another way of changing what clusters are returned is to not filter what you cluster on by any specific item number. When you do a basic cluster on the full data set you get some great clusters on color:
http://localhost:8983/solr/clustering?&q=*:*
Lastly, you can play with different clustering engines, Solr comes with three of them, Lingo (the default), STC, and Kmeans options. Try both the full dataset and the faceted on item number dataset to see the different types of results from the clustering algorithms.
STC seems to be very similar to the Lingo option, but does provide some clusters that have multiple labels. For example MAPEI 10 Lb and Premium Unsanded Grout, as well as a separate cluster of just MAPEI 10 lbs products. http://localhost:8983/solr/clustering?&q=:&fq=item_number_s:%22Item+%23%3A+185276%22&clustering.engine=stc http://localhost:8983/solr/clustering?&q=*:*&clustering.engine=stc
KMeans returns clusters that are all over the place. Lots of labels, but I dont quite see the connection between the items that makes them all clustered. We have some clusters that are Tan, Chocolate, Cocoa, and three items associated with it, each one of the colors! http://localhost:8983/solr/clustering?&q=:&fq=item_number_s:%22Item+%23%3A+185276%22&clustering.engine=kmeans http://localhost:8983/solr/clustering?&q=*:*&clustering.engine=kmeans
KMeans on this dataset seems to be the least useful.
What does it mean?
Well, first and foremost, it means that clustering can be a discovery tool for figuring out potential tags and facets for your documents. By facets, I mean potential ways of slicing through all the data. By tags, I mean a set of richer attributes about the products that is pulled out of the product descriptions.
In this specific case, it really drove home that instead of 30 products with different sizes, colors, and types, that there are two products from a users perspective: MAPEI Unsanded Powdered Grout and MAPEI Keracolor U Unsanded Grout. These two products should have a set of drop downs for size and color. The simple bit of clustering we did suggested that size was something that could be extracted as potential tags.
There are two ways to model these relationships. You could model the products in Solr either as two documents, one per product, and use dynamic fields to create multivalued fields for size and color. Or, if you need to index everything de-normalized the way Lowes has done it, then if you have identified some tags as distinct fields, then you can use field collapsing so that even though you may have 14 products all with the same name, but different sizes and colors you collapse on the item number, and then provide those data as distinguishing drop downs.
Here is a sense of what field collapsing on item number will do, we have 17 documents. 16 are unique item numbers, plus the 17th is the collapsed version of the 14 products that all share item number 185276.
Oh, and just so you dont think this is an easy problem to solve, Amazon, who normally is a wonderful example of search done right, has the same exact problem for Aqua Mix Grout Colorant
Next Steps
So after all that, my colleage Dan suggested that I needed an example of showing the payout of going through the effort of clustering. So I added a script that pulls back the clusters and stores them in a multi valued field tags_txt. tags_txt can now be treated as traditional facetsin the user interface. The two choices that seemed most interesting are clustering on all the products and just the products that share the Item Number 185276.
Go ahead and run ruby insert_clustered_data.rb tags_smv is a multivalued string field that is perfect for faceting on, and should now have all the cluster labels stored. Reload the browse interface and you will now have a list of very reasonable facets to use derived by clustering:
!https://img.skitch.com/20120316-kqp2d6q7ejh5xgmkj1fiy3prfg.png!
Because we configured facet.mincount=2 in solrconfig.xml for the browse handler, any completely unique clusters are hidden from the list of facetable options, which reduces the amount of noise in the tags_smv listing.
The Upshot of all this
Compare the facet options from Lowes versus what I pulled out via clustering. The top 4 facets are very useful to someone trying to filter down the set of grout choices, and were pulled out of the content:

Clustering can be a very useful tool, the trick is to figure out which clusters make sense, and which ones dont. And unfortunately, that is still something that appears to require human judgement!