
Today we have flipped the switch to release Quepid as an open source project, licensed under the Apache License v2.0. Come check out the source at http://github.com/o19s/quepid.
What is Quepid? Why should you care?
If you haven’t heard of Quepid, it’s a means for the whole organization to tweak Solr and Elasticsearch relevance. In the early 2010s, search teams would ship a beautiful and fast Solr or Elasticsearch application but lo and behold, users would begin to complain that they couldn’t find what they needed – which after all is the whole purpose of the search engine!
Nobody on the product/technical team wants to think about this mystical ‘relevance’ bit. It was and is a hard problem to approach. It requires a lot of trial and error, fiddling with obscure relevance features like “TF*IDF” or the “edismax query parser”. It means understanding how the search engine dealt with (or didn’t deal with) synonyms, taxonomies, and knowledge graphs.
Most importantly, it means getting into the heads of the users, frankly something our technologists were not equipped to do. We have to tap into domain or business expertise to really understand what the application’s audience considered relevant. In Quepid’s first use, we worked on medical queries and none of the search engineers knew that ‘Myocardial Infarction’ was a fancy term for a heart attack. Or that ‘ct’ was an abreviation for about half a dozen medical terms.
This cartoon captures why we created Quepid in 2013 and remains accurate today if you don’t have tools like Quepid:

Quepid became a tool for bootstrapping the relevance process with a few simple queries, and a few ratings on what a good / bad result was for that query. In classic search parlance, this is what you’d call a ‘judgement list’. Using a judgement list, we could then put a number on the quality of each query – from simple ‘unit test’ style tests we would code up to classic judgment list metrics like NDCG.
Armed with this data, you have the ability to tweak and tune your search engine configuration. Quepid itself is a sandbox for changing the Solr or Elasticsearch query and seeing the result. It acts like a kind of search team IDE – with a history of all the query patterns that have been tried and an ability to go back to a good version after you decide you’re in a rabbit hole.
But the real power of Quepid is you’re doing all this side-by-side with a domain expert. As you play with the search engine configuration, you can sit and explain ‘why’ a result was coming back in a more understandable way than getting into voodoo about BM25 or boosts, as shown in the screenshow below:
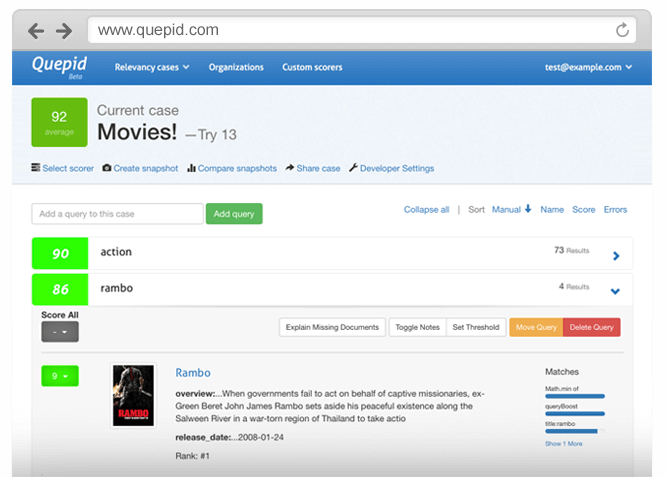
Most organizations get lost in relevance, and Quepid continues to be a big part of making the process transparent, easier to get started before worrying about staffing a massive data science competency and measuring relevance. Quepid is like using an IDE for search alongside a set of unit tests, a kind of ‘editor’ that helps the whole team iterate on relevance. We use it extensively in our consulting services to help organizations go from about “0 to 25” with relevance, with iterative tuning that helps them get up and running quickly. We hope you can help continue with us on the Quepid journey!
Why did we open source Quepid?
We see teams that need to bootstrap the relevance process, and Quepid is a great way to do that. Quepid’s not the tool for a 10000 query judgment list for testing relevance. Quepid’s a tool that is a gateway to starting the process. It’s the babystep to a gradual, iterative improvement. We wanted to make that accesible to everyone to democratize relevance!
Every organization (including us!) creates their own relevance judgement list testing and tuning platform, and we don’t want to keep reinventing plungers. Let’s rally around one platform for collecting judgements and then using that to tweak and tune Solr or Elasticsearch relevance. Our number one request was “Can I download and install Quepid in my datacenter?”. As a closed source commercial tool, we couldn’t figure out a reasonable economic model for providing a downloadable version of Quepid that met our expectations. Open sourcing Quepid means that we can ask the community to contribute to Quepid being deployable in many environments.
Recently a bevy of open source relevance tools are being created. Imagine if ratings created in Quepid fed directly into RRE to measure search metrics and Quaerite to tune query parameters?
The clue is in the (company) name!
What does this mean for me?
We’re going to continue to provide the free hosted version of Quepid at http://www.quepid.com, so if you depend on that service, rest assured it will continue to be available.
Want to run Quepid in your data center? Have at it! Improving how Quepid is deployed will be an area of focus now that the project is open sourced. There’s already a way to build a Docker image of Quepid.
Have a custom search API? Using a different search engine than Solr or Elasticsearch? We originally created Quepid to scratch our specific itches, and that legacy has continued on to today. By moving to a community driven effort, we open the door to Quepid fitting a broader set of use cases. Maybe you could develop a plugin to connect Quepid to a commercial search engine you’re migrating from, and then compare the ratings with those coming from Solr or Elasticsearch?
We chose the Apache licence because it is a very business friendly license to encourage people to reuse the Quepid source for their own purposes, and removes impediments from deploying it in your enterprise. Great relevance is good for everyone!
I want to thank the over 1100 users of Quepid, as well as the 15 contributors who’ve made 2951 commits over the life of Quepid as a internal OSC project. I especially want to thank my colleagues Doug Turnbull for the initial idea for Quepid, and Charlie Hull who saw the value of Quepid to not just OSC’s clients, but the world, and led the effort to make it a public hosted service.
Come and join us in Relevance Slack – there’s a #quepid channel to share your experiences and to get community support – and if you need help with tuning relevance do get in touch.