
 Charlie Hull
Charlie Hull
Category: AI
AI-powered search is everywhere – new projects, products and companies are appearing to solve age-old challenges. But how ‘good’ is an AI-powered search engine – and how can we measure this?
It’s no secret that the world of search has been thrown into turmoil by the recent AI buzz. Businesses & users are now faced with many more choices when selecting a solution: established providers (including traditional and NoSQL databases), open source platforms and venture-funded new players are all vying for attention. So how do we as technologists develop and evolve the best technology?
Firstly, we need to decide on some metrics to measure just how “good” the results are from an AI-powered search engine. We can learn much from established best practices and the history of Information Retrieval, the decades-old academic research area behind search technology. We also have to be pragmatic and focused, to try and cut through the marketing clutter and really understand how these new approaches can solve real-world problems.
At OpenSource Connections (OSC) we have a long history of working on search measurement – we created and continue to host Quepid, a freely available and open source platform for gathering manual evaluations of search relevance for tuning search engines that’s used by hundreds of search teams, and we’ve written and presented extensively on how judgements of search quality can be used to derive metrics. We think the best way to improve search quality is to be data-driven, understanding the information needs of your users and constantly tuning and improving your engine based on these insights.
We were thus very happy to be asked by Vectara, an AI-based search and retrieval augmented generation (“RAG”) platform, to evaluate some aspects of their new AI-powered engine, and grateful for their honesty and openness in letting us publish some of the results of this process. Like any evaluation limited by time and available effort, it can never be exhaustive, but both OSC and Vectara hope it advances the debate on search quality measurement.

OSC were specifically asked to compare Vectara’s new internally developed embeddings model, code-named Boomerang, against Universal Sentence Encoder QA (USE-QA) – a very popular question/answering model used by a large number of semantic search platforms.
The search for datasets
To test a search engine, you first need a test dataset comprising some documents, some queries and some relevance scores linking the two, usually derived from human judges. Simply put, you can ingest these documents into your system, try the queries and see if your engine returns results that are scored highly (and perhaps calculate overall metrics like nDCG and compare these against a provided baseline).
There are many datasets in existence, but sadly never enough – in particular there is a lack of real-world (not synthetically generated) datasets for enterprise search (perhaps unsurprisingly as this might require confidential internal company data). To really stretch the Vectara engine, we wanted to test several potential search applications – e-commerce search, scientific search, multilingual search and question answering.
Here’s the five datasets we selected for the Vectara evaluation:
- Amazon ESCI – a dataset of “difficult” product search queries along with 40 result items rated as “exact”, “substitute”, “complement” or “irrelevant”. It is available for three different locales: Spain (‘es’), Japan (‘jp’), and USA (‘us’) with a few hundred thousand items for each locale.
- Wayfair ANnotation Dataset (WANDS) – a human-labeled dataset of product search relevance judgements.
- The BeIR packaging of the TREC-COVID dataset is a good example of a typical dataset in the scientific/medical information retrieval domain.
- The CLIRMatrix dataset is a large collection of bilingual and multilingual datasets for Cross-Lingual Information Retrieval. It contains 49 million queries in 139 languages and 34 billion judgements (query, document, label triples). BI-139 is a bilingual subset containing queries in one language matched with relevant documents in another. We chose English language queries against the Korean language corpus for our evaluation.
- The TREC-ToT dataset is a recent TREC benchmark for “tip of the tongue” retrieval where a searcher only vaguely describes a concept (in this case, a movie they have seen but hardly remember). We included the dataset here as it contains considerably longer more conversational queries.
So, what were the results? Remember, Vectara were mainly interested in whether Boomerang performed better than USE-QA, not in comparing it with all other models. Here are some of our conclusions:
- We were able to confirm Vectara’s internal evaluation that Boomerang provided a superior performance in 4 of the 5 datasets.
- We found that while cross-language information retrieval is good and improved over USE-QA, there are still some areas that could be investigated.
- Not surprisingly, the vague descriptions of concepts in the ToT task provided a bigger challenge to both models, with USE-QA even performing slightly better on the TREC-ToT dataset.
We can also share some of the resulting metrics, in this case measurements of NCDG@10 for four of the datasets with no re-ranking applied:
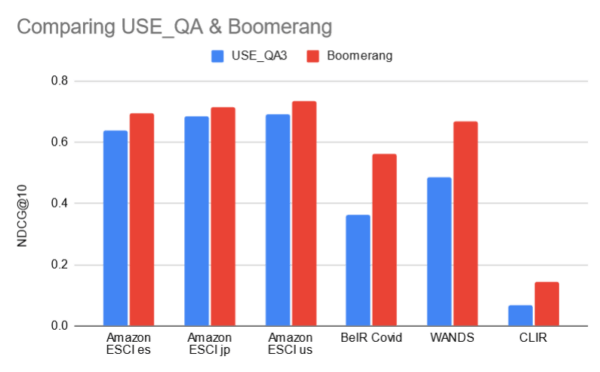
The Vectara team is now using our results to further tune and improve Boomerang.
Testing in Parallel
Vectara are committed to testing and evaluation – OSC weren’t the only organization working on this, as Vectara’s own blog proves! They have run some comparisons with other models themselves and also worked with a customer to evaluate performance on some real-world data and tasks. As you can see, Boomerang stacks up well against some other competing models:
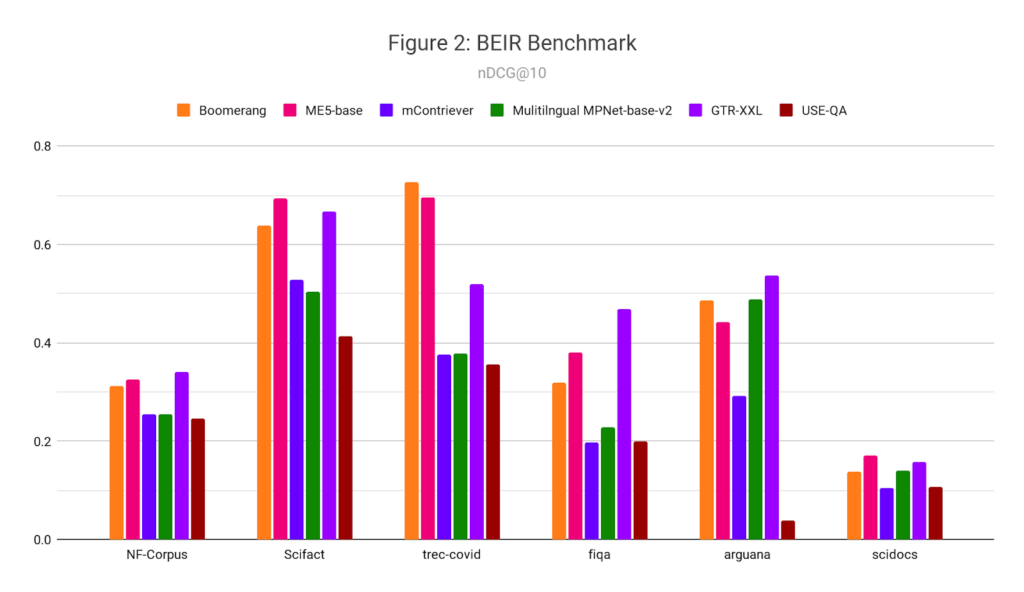
Developing further tests with Quepid
We suggested that another way to test the engine would be by developing a Quepid integration. This would allow the Vectara team to create lists of queries representing particular use cases (for example multi-word searches using medical terminology, or mis-spelled queries over legal data), run them through Quepid, gather manual judgements of the results using subject matter experts, create overall metrics like NDCG and then use these tests to gradually tune and improve the Vectara engine. Vectara customers can also benefit from Quepid of course, using it to test and tune the performance of their own queries.
Quepid was originally built to work with Apache Solr, which has a HTTP search API and returns search results, scores and (optionally) some explanations showing why a search result matched. So in theory, all you need to do to adapt Quepid to a new engine is a) figure out the format for sending queries to its search API (hey, everyone has a search API these days, right?) and b) translate whatever it returns into a tidy list of results and scores for Quepid to display. It’s not quite that simple, as every engine returns results in a different way and newer search engines have advanced features such as answer generation and result summarization which need to be measured, so there are various UI modifications to implement.
We did manage to create a very basic Vectara integration during the time we had – this is now live on www.quepid.com although it’s a little fiddly to get set up, and we’re working with the Vectara team on improving it. However, for the first time this adds a native AI search engine to the Quepid stable of Solr, Elasticsearch and OpenSearch – let’s hope this is the first of many!

Feature comparison
We also considered the available features of Vectara’s platform based on our deep experience of the search engine sector. There are some features that users expect, some that may not always be necessary and some that may now simply be obsolete in the world of AI. We worked with Vectara to develop a list of suggested feature upgrades – and even found the odd bug! For example, we identified that Vectara users would find their solution easier to use if they added an “upsert” capability (instead of 2 API calls to delete and then add documents) and that Vectara’s metadata filters could become more useful for many search use cases if they accepted a longer list of filters. Vectara took our advice and is currently implementing these:

Example of metadata filters in Vectara: filtering by ID over a search of Vectara’s own documentation
Conclusion
It’s been fascinating to get ‘under the hood’ of one of the new breed of search engines and we’re very grateful to Vectara for the opportunity. It’s difficult to be open and honest about the performance of your product, especially in such a febrile atmosphere, where every benchmark or comparison is harshly judged for bias. We hope that others commit to publishing their test results and we look forward to assisting wherever we can.
- If you’re interested in working with OpenSource Connections on evaluating your own search and relevance, get in touch today.
- If you’re interested in running evaluations using Quepid on any search system, including your existing Elasticsearch/Solr/OpenSearch-based system or Vectara, check out www.quepid.com.
- If you’re interested in diving into Boomerang and trying it for yourself, check out Vectara