
 Daniel Wrigley
Daniel Wrigley
Category: AI
Introduction
The advances in Natural Language Processing over the last years brought us a plethora of large language models that can be used for different tasks in search applications but also in other contexts: text summarization, text classification, question-answering and many more. In this blog I will focus on how language models can be used to understand your users better with query understanding, enhancing the overall user experience and the search result quality of your search platform.
Query Pipeline Concept
In the search domain users express themselves through queries. Queries are typically short, comprising only a few words, leaving us with a very limited amount of data to work with. This makes it difficult yet at the same time very important to make the most out of what we have. We use queries as proxies for user intent, so by understanding queries we are ultimately trying to understand users.
There are different processes that can be used to do so and these are typically chained together and executed in sequence. Some of these steps depend on each other or can profit from the output of another step. In the following I will call all steps executed as part of a query the query pipeline, and query understanding steps thus are part of this query pipeline. Depending on your domain such a query pipeline may look different, but they all share similar features.
Query Pipeline Examples
Let’s look at two examples of query pipelines in recent literature and highlight the steps that may be classified as query understanding steps.
AI-Powered Search Query Pipeline
An example query pipeline from Manning’s book AI-Powered Search used in the chapter focusing on query intent detection.
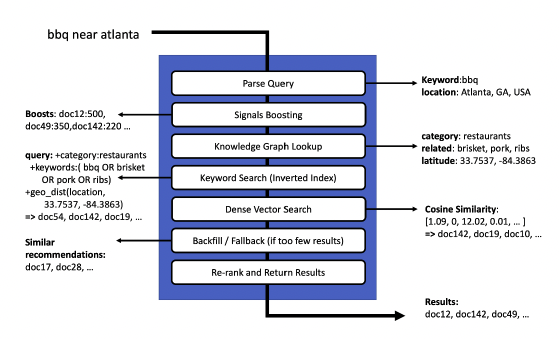
Here there are two query understanding steps:
- Parse Query: For the input
bbq near atlantathe “Parse Query” step is able to detect thatatlantais referring to a location, “Atlanta, GA, USA” and that the relevant keyword of the remaining ones isbbq, thus dropping the termnear. - Knowledge Graph Lookup: The knowledge graph lookup returns the category this query belongs to (
restaurant) and related terms (brisket, pork, ribs)
These two steps add information and metadata to the query that make the user intent clearer to the search engine which is ultimately responsible for retrieving relevant results for the user. With these steps the search engine has an advantage compared to purely looking for the terms provided to come up with a targeted result set.
Query Pipeline from Query Understanding for Search Engines
Query Understanding for Search Engines is a whole book dedicated to the topic of Query Understanding. The editors have a broad view on query understanding including steps that come after query execution:
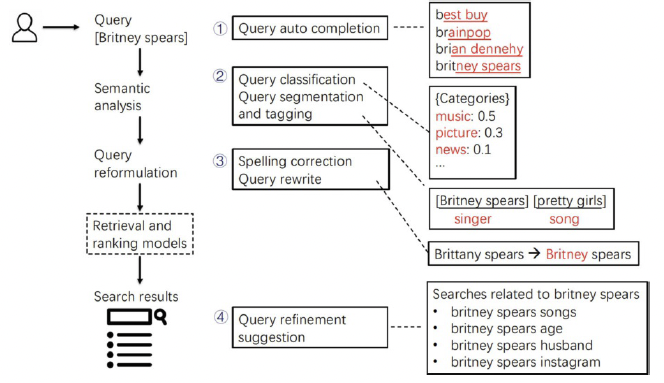
This pipeline contains multiple steps that can be attributed to query understanding:
- Query auto completion: When typing the query the user already gets suggestions on how to complete the (partially entered) query that he or she is typing. This step helps to deflect misspelled words and guides the users in finding what they need early in the query pipeline.
- Query classification: This step predicts a category to which the query presumably belongs. For the query
britney spearsmultiple categories with different levels of confidence are predicted:music 0.5,picture 0.3andnews 0.3. Query classification can help disambiguate the query. - Query segmentation and tagging: This two-step process identifies units within the query and tags these accordingly. For the query
britney spears pretty girlsthe two segmentsbritney spearsandpretty girlsare identified.britney spearsis tagged assingerwhereaspretty girlsis tagged assong. This approach is extremely helpful when matching the units to indexed fields as this can already narrow down the result set to very precise results. Doing this requires high confidence in the detected segments and tags. - Spelling correction and query rewrite: This step aims to avoid empty result sets by correcting misspelled words and rewriting the query accordingly.
- Query refinement suggestion: This pipeline has a step triggered after retrieving and ranking the results presenting suggestions how the user might continue on the platform. These suggestions are related queries that extend the original query and, in this example, add a query term to it.
Query Understanding Pipeline Steps and (Large) Language Models
None of the above mentioned query understanding steps necessarily requires language models to be implemented. However, leveraging the power of language models can add value to your existing query understanding pipeline or simplify the process of setting up a new one.
I want to highlight a few query understanding pipeline steps that can benefit from using language models and how you can utilize the power of them:
- Query Relaxation
- Alternative Queries
- Query Intent Detection
- Query Expansion
This is by no means an exhaustive list of how you can leverage (large) language models in query understanding steps but some of what we have seen in practice, or a concept we have seen in practice transferred to a query understanding task.
Query Relaxation
Query relaxation is a technique where you drop a query term to mitigate zero results and provide the user with results for queries that would otherwise not yield results.
Suppose a query for google pixel watch 3 does not give any results because the most recent model is called Google Pixel Watch 2. For this query I am assuming the user intent is to search for smartwatches by the brand Google. There are four potential query candidates when you drop one term:
- google pixel watch
- google pixel 3
- google watch 3
- pixel watch 3
With the Google Pixel Watch 2 being the most recent Google smartwatch there basically is only one reasonable query to go for: google pixel watch. In this case, dropping the query term 3 is the best option as that would retrieve those products closest to what the user expected.
Using this approach has some benefits over alternatives like dropping query terms randomly with approaches like Solr’s minimum should match parameter, or doing a vector search query instead: it is a much more targeted approach and reduces the randomness in the result set. With queries that have a clear intent showing precise results is recommended. Query relaxation is no silver bullet in mitigating zero results but it can well be a part of your strategy.
How language models can help with query relaxation
You can see query relaxation as a token classification task: In a sequence of tokens (the user query) we want to predict which token we should drop and then return the index of the term to drop. However, there is no pre-trained model (to my knowledge) that can do that out of the box. Fine-tuning to the rescue! Simply put, take an off-the-shelf pre-trained language model and fine-tune it with your data. The data for this fine-tuning task are query-label pairs with queries that need to be relaxed and the index of the term to drop as the label.
As a result you have a fine-tuned language model that has some general understanding of language (the pre-trained part of the model) and domain specific knowledge of what label to drop (the fine-tuned part of the model). If you want to dig into this deeper: René Kriegler published the work he did together with our client Wallapop in this area at Haystack EU 2023.
Alternative Queries
Let’s take the query relaxation technique one step further: dropping a query term produces a gap and this gap can be filled with a new query term. This is exactly what fill-mask models do: suggest one or multiple terms that can act as replacements for a dropped query term.
Let’s return to the example from the previous step: we “relaxed” the query google pixel watch 3 to google pixel watch. If we wanted to ask a fill-mask model for alternatives for the dropped query we would need to ask it to “unmask” the following string: google pixel watch [MASK]. The sequence [MASK] signals the model to come up with suggestions for this sequence. There are models that provide this functionality out of the box, e.g. distilbert-base-uncased. Conveniently Huggingface provides us with an API to explore how well this model would do with our query:
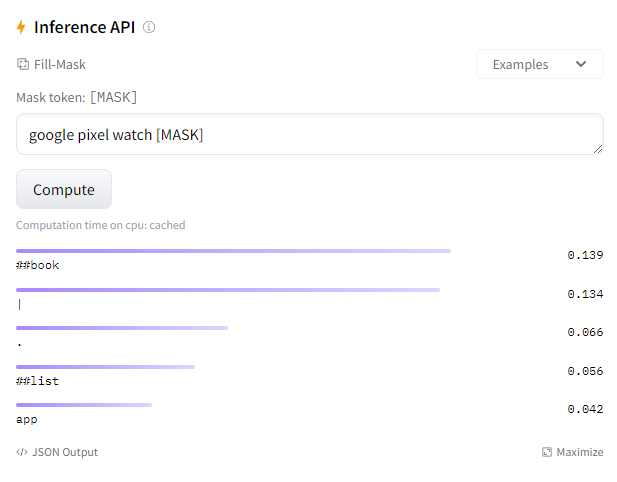
The top suggestion is ##book which means that the suggested character sequence (book) follows directly the preceding token without a delimiter (a space). So the resulting query would be google pixel watchbook. A poor suggestion!
Again it’s fine-tuning to the rescue! We can fine-tune a pre-trained model to help it understand our domain (and thus understand our users) better. Where we used unsuccessful queries to fine-tune the model for query relaxation and tell it what terms to drop we can now use successful queries to tell the model which terms are actually good ones to suggest.
The definition of success is not easy and can have different nuances. The easiest definition might be that a successful query is one that returns results. YMMV here. Most importantly you should see a good variety of different queries in the fine-tuning dataset to let the model pick up the specifics of your domain. What this means is that if there are occurrences of google pixel watch 2 among the successful queries then this is something the fill-mask model then can pick up and make better suggestions than google pixel watchbook – all depending on the fine-tuning data of course.
Fill-mask models pick up their knowledge about language by randomly masking tokens in large texts. When fine-tuning with successful queries it is thus necessary to generate one large text from these queries and then randomly masking tokens in there to derive the knowledge that specifically is in the queries. As a result you have a fine-tuned language model that has some general understanding of language (the pre-trained part of the model) and domain specific knowledge of what query term to suggest for a dropped term (the fine-tuned part of the model).
Alternatively, you can use such a model also to suggest alternative queries as options for users to dive in deeper. This can be especially useful for very broad queries to give users ideas how they can refine their queries to get more precise results like in the “Query refinement suggestion” step shown in the second query pipeline example.
The linked recording of the above mentioned talk on Query Relaxation goes into some more details in case you want to explore generating alternative query terms for dropped ones.
Query Intent Detection
Detecting the underlying intent of a query can be extremely helpful when guiding the user to relevant results. Query intent may mean different things, so I’ll start with the definition of query intent used for the purpose of this paragraph: in this blog post by query intent detection we mean to identify attribute values in the query string provided by the user.
Using the above-mentioned query example of google pixel watch 3 this means we would like to identify the sequence google as a brand. In e-commerce brands and product categories typically are the most important ones so detecting those in user queries is what we see implemented most often. In other domains other attributes are more important. Identifying the most important ones for your use case is a vital preparation for any query intent detection project.
How to use language models to help us detect the intent in user queries
For this we treat query intent detection as a token classification task. If this sounds familiar, then it should! For query relaxation we predicted whether a token should be dropped or not which you can see as a binary classification task (1=yes, drop the query term, 2=no, do not drop the query term). Now we predict which class (=attribute) for each token in a query. To give you an example, I will be using the BIO encoding format and want to identify brands in user queries. With the BIO encoding format this means we have three classes:
- O (outside) for any token not belonging to a brand.
- B (beginning) for any token representing the beginning of a brand.
- I (inside) for any token following a “B-token” where brands consist of multiple tokens.
For a query with a brand with one token:
Query: google pixel watch 3
google | pixel | watch | 3 |
| B-brand | O | O | O |
For a query with a brand with two tokens:
Query: calvin klein shirt
calvin | klein | shirt |
| B-brand | I-brand | O |
Similarly to the previously described tasks we use a pre-trained language model as the foundation of our work. As fine-tuning dataset we need a labeled dataset that contains queries and the classes as labels. With this dataset we can now integrate the domain-specific knowledge into the pre-trained model and have a fine-tuned model as a result ready to detect the intent of incoming queries.
Now you may wonder what to do with this information. As a rule of thumb you can use detected intents according to your confidence level. When you are very confident that “X” is a detected brand in a user query and “Y” a category you can use these as filters to narrow down the result set you are presenting to the user. When you are less confident you can apply boosts that will not limit recall (and thus maybe eliminate relevant documents from the result) but increase precision.
More sophisticated approaches include rules that depend on the detected intents. Especially in e-commerce (B2C and B2B) we often see the requirement to treat some brands differently than others, for example due to contractual agreements with these brands or higher margins for products made by these brands. Another option is boosting specific products or product groups associated with a certain brand. The German brand Miele produces vacuum cleaners, washing machines and dishwashers (among other things). Knowing that certain products, e.g. vacuum cleaners sell better or mean higher margins for you lets you apply this knowledge as rules for the detected brand Miele in user queries and thus boost results including vacuum cleaners.
If you wanted to detect which product class or category a query belongs to this would become a text classification task, not a token classification task. In that case you don’t extract attribute values from a query but classify or categorize the query as a whole. This is also possible with the help of language models. The labeled dataset for fine-tuning then is a set of queries with categories as labels.
Aritra Mandal showed different advantages for this in his 2021 MICES talk Using AI to Understand Search Intent, e.g. excluding out-of-category results that match keywords. This technique is especially useful nowadays with companies investing in using vector search to mitigate zero result searches and fill up the results with vector retrieved results. This can lead to results that seem similar according to an opaque similarity score calculated by kNN or another algorithm but actually are only very distantly related to the user query. Identifying the product class or category can act as a guardrail by filtering out products retrieved by vector search to exclude products that are irrelevant for a user query.
Query Expansion
User queries are short and as a consequence there isn’t a lot to work with to understand what a user actually wants to express. But what if we could use language models to help users formulate more complete queries that are able to retrieve a more complete result set? To do so we can use an instruction tuned LLM like ChatGPT and ask for similar queries for a given user query. The main query (i.e. the user query) and the similar queries are then executed in parallel in the background to retrieve a result set for each of them. The result sets can then be merged together with reranking algorithms like Reciprocal Rank Fusion (RRF) to present the user one combined and complete result set.
Elsevier demonstrated this approach in a Retrieval Augmented Generation setting at a Meetup in London and published source code for illustration. The process of generating similar queries and merging several result sets may be more expensive and slower than the other described methods to use language models to improve your query understanding pipeline. This means that scenarios like Retrieval Augmented Generation may benefit more from this approach compared to e-commerce search or other high-performance settings.
The more specialized your domain is the more likely you are to rely on fine-tuning in this process as well to integrate domain knowledge in the language model.
There may be cases where you want to provide suggestions to the user rather than executing queries on behalf of her/him. In these situations you can identify the similar queries the same way but instead of directly searching for these alternative queries provide as a selection to the user to choose from e.g. at the bottom of the result list for the executed query. That keeps the user engaged and provides alternative routes to her/his needs. This step comes towards the end of the query pipeline shown in our example above from Query Understanding for Search Engines.
Conclusion
(Large) language models are powerful tools in the toolbox to be used in search applications and can be very useful in query understanding pipelines. A variety of different things can be done with the use of (large) language models to help improve understanding your users; either by mitigating zero results through query relaxation and providing alternative query terms for the dropped ones, by detecting user intent in queries or by expanding the query with similar ones that can help surface the recall that would otherwise go missing.
Do you need help understanding your users through their queries? Get in touch today!
Image by Understanding Vectors by Vecteezy