
 Daniel Wrigley
Daniel Wrigley
Category: Vector Search
Vector Search Hackday with Jina AI
Vector search is one of the hottest topics in the search community – if not the hottest topic. To spread the knowledge about this topic we joined forces with Jina AI and ran a vector search hackday in their office in Berlin one day after Haystack EU 2022.
We were a very heterogeneous group with different backgrounds and different interests, so we split into teams. Each team had a different theme to work on and also a Jina AI expert to guide them into the right direction and assist where necessary. Being part of OSC’s e-commerce search team, the team dealing with vector search in the e-commerce space felt like a natural fit for me. This blog post aims to summarize the output of our collaborative effort.
Why Apply Vector Search in E-Commerce
In the context of this blog post, applying vector search in e-commerce means that instead of having matches based on found keywords or manually curated synonyms we want to retrieve semantically similar products based on a textual input. Leveraging vectors in e-commerce search is an interesting proposition as it allows us to retrieve relevant products from an index without exactly having to match the user’s input which can be challenging for several reasons, e.g.:
- Users use a different language than the language used to describe the product in a catalog e.g. “laptop bag” vs “notebook case”
- Users increasingly use natural language to formulate their needs, e.g. “which cases fit my iphone 14”
- The user may not use traditional search boxes but other devices like Apple’s Siri, Amazon’s Alexa, etc.
- Users often misspell search terms and spelling correction mechanisms based on search indexes are limited
Generally speaking, vector search is a promising technique that is useful for fixing recall issues especially in e-commerce search.
Building Blocks of Vector Search
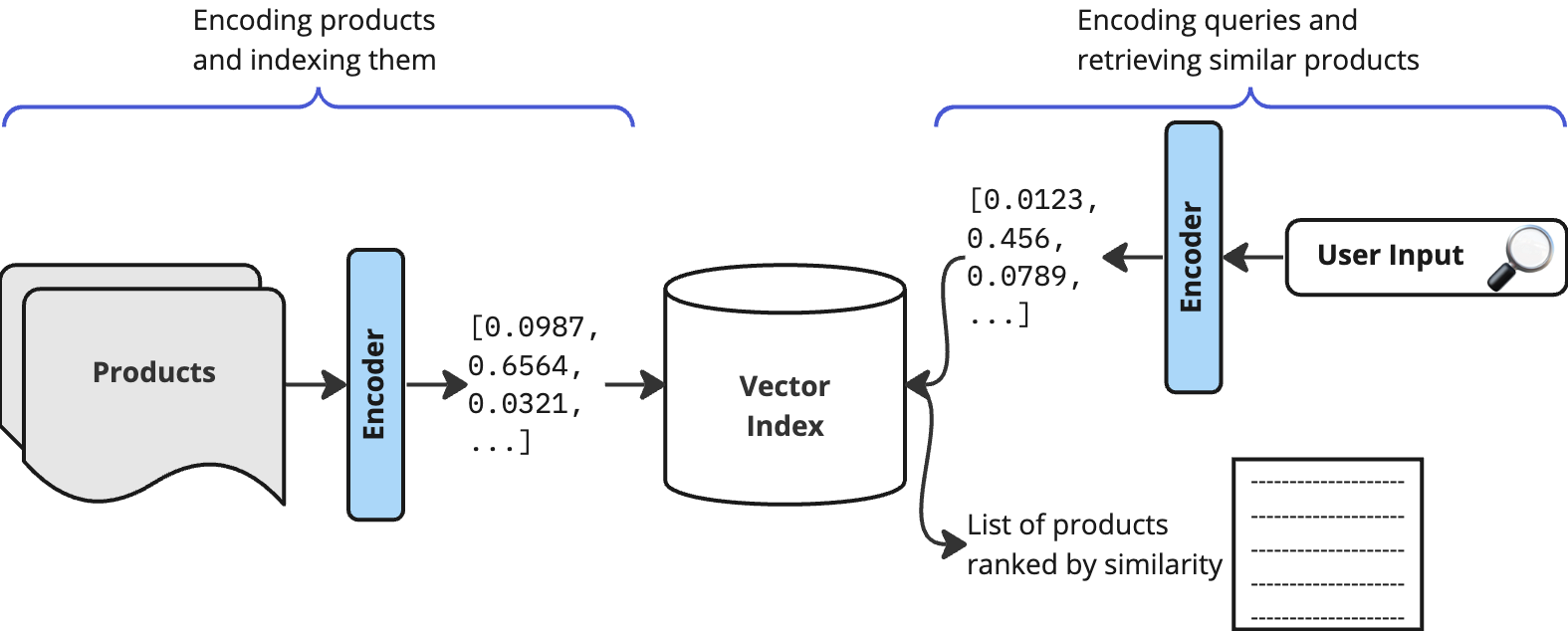
Before applying vector search let’s first understand the components that make up vector search. These are: encoders, language models, embeddings and vectors.
On the data side we typically have product data that needs to be indexed. These products need to be represented as vectors. This is what encoders do: they take data as an input and apply a language model to generate embeddings. An index stores these embeddings as vectors.
On the query side the users’ queries need to be converted to a vector of the same dimension to be able to compute the similarity between indexed products and queries. Again, encoders generate these embeddings by applying language models to queries.
This diagram shows these bits and pieces working together:
How to Apply Vector Search in E-Commerce with Jina AI
We created a Google Colab notebook on the hackday to demonstrate the idea that you can clone to follow along.
The dataset we used is sourced from Icecat and also used in the Chorus stack, OSC’s e-commerce search reference implementation. It consists of data describing roughly 19,000 products, formatted as JSON.
Preparing the Data
Jina AI provides us with a framework to build vector search solutions and we use parts of this framework to power our e-commerce vector search use case. Jina AI’s DocArray helps us structure our data. For each of our products we concatenate the “meaningful” fields (title and other textual attributes, short description, name, supplier). These become the basis for the embeddings that represent our products:
da = DocumentArray()
with open('icecat-products-w_price-19k-20201127.json') as f:
jdocs = json.load(f)
for doc in jdocs:
d = Document(text=" ".join([doc[item] for item in doc if item.startswith("title")
or item.startswith("attr_t")
or item.startswith("short_description")
or item.startswith("name")
or item.startswith("supplier")]), tags=doc)
da.append(d)This structures the data in the desired format, all set to be indexed with encodings.
Defining a Flow with an Encoder and and Indexer
We define a so-called Flow with Jina AI that consists of two steps:
- TransformerTorchEncoder
- AnnLiteIndexer
The TransformerTorchEncoder takes our product data as its input and produces embeddings, which the AnnLiteIndexer in turn indexes along with some metadata that we can use later at query time to filter and narrow down result sets:
from jina import Flow
f = Flow()
f = Flow().add(
name='encoder',
uses='jinahub://TransformerTorchEncoder/latest',
install_requirements=True).add(
uses='jinahub://AnnLiteIndexer/latest',
install_requirements=True,
uses_with={
'columns': [
('supplier', 'str'),
('price', 'float'),
('attr_t_product_type', 'str'),
('attr_t_product_colour', 'str')
],
'n_dim': 768
}
)Generating embeddings and indexing them can be an operation that may take some time, so in our notebook we are restricting the number of products in our DocumentArray to 1,000 before applying our flow to the data:
da = da[1:1000]
with f:
da = f.index(da)Query the Index – Vector Search in Action!
With successfully indexed data it is time for our first query. We can use the already defined Flow for this. This means that we will use the TransformerTorchEncoder to generate a vector representation of the query and the AnnLiteIndexer to query the indexed data. Let’s search for laptop case:
query = Document(text='laptop case')
with f:
results = f.search(query)
results[0].matches[0]As a result for the query laptop case we get a black laptop case returned as best hit – a relevant match!
Filtering Results
Filters have a very important role in any search application and the Jina AI framework provides native support for the same. Assuming that black is not the color we are looking for we want to filter the results to contain either white or blue laptop cases:
colors = ["White", "Blue"]
filter = {
"attr_t_product_colour": {
"$in": colors
}
}
text_string = "laptop case"
text_query = Document(text=text_string)
with f:
text_matches = f.search(text_query, show_progress=True,
parameters={"filter": filter})Looking at the color attribute of the retrieved result shows that this worked perfectly:
print(text_matches[0].matches[0].tags['short_description'])
print(text_matches[0].matches[0].tags['attr_t_product_colour'])Our output:
15.6" Crave Laptop Slipcase, Nylon, Blue
BlueConclusion
With only a couple of lines we are able to transform data, compute embeddings to represent the products’ meanings, index the embeddings as vectors and search in this index optionally with filters applied. Is e-commerce search solved by being able to apply vector search in this area so easily? Well, not quite. While frameworks and tools like those that Jina AI provides us with help a great deal in getting started, there still are challenges: our view on e-commerce is “precision first”, so techniques that aim at improving recall can only be a part of the overall solution.
However, hybrid search offers an approach where traditional search methods (sparse vectors, TF/IDF, BM25, etc.) are combined with emerging techniques (dense vectors, neural search, nearest neighbor search, etc.). It will be interesting to see how these will evolve in the near future. With Vespa and Elasticsearch, there already are two search engines capable of combining dense and sparse retrieval. It will be only a matter of time until other main players in the space like Solr or OpenSearch introduce similar features. One of the groups at our vector search hackday was exploring hybrid search with Jina AI…but that’s a story for another blog post, so stay tuned!
In the meantime, feel free to check out the Colab notebook with the code for this blog post. Thanks again to everyone at Jina AI for their kind hosting of the Hackday and all the help they gave participants.
If you need our help with your e-commerce search application or are thinking of applying vector search contact us today.