
 Charlie Hull
Charlie Hull
Category: Vector Search
If you’ve been following new developments in search, or noticed a new buzz from search vendor marketing, you will have heard the terms Neural Search and Vector Search. In this article we aim to make it simpler for you to understand this emerging and important field. We’ll try to demystify and explain the terms, but importantly also help you decide whether you should be paying closer attention to this trend and how your business might benefit.
Originally published in Search Insights 2022 by The Search Network, written by Charlie Hull, Eric Pugh & Dmitry Kan
What is vector search?
Firstly, what exactly is a vector in the context of search? Let’s start by considering how traditional search engines work: essentially they build a data structure much like the index at the back of a book, except they collect and count every single word in the source material. This index makes it very easy to look up relevant documents – if a user types fish as a query, we can quickly find out which documents originally contained that word. To order the documents in terms of relevance, we count how many times fish appears in each document – and indeed across the whole set of documents so we know the local and overall rarity of this word. These calculations are the basis of the Term Frequency/Inverse Document Frequency (TF/IDF) formula used since the 1970s in most text search engines, which works very well in most cases.
The trouble with this approach is that at no point does it capture the meaning or context of the word fish – or indeed the difference or connection between the phrases fresh fish and fishing rod, or a recipe for fish cakes and a legal text about regulating the size of fish catches. It’s also limited to searching text and can’t easily be used for other types of data like images. Luckily, some recent developments in text analysis (like many innovations in search, these were created at large web search companies) have made it much easier to capture the meaning of a piece of text. Machine learning algorithms called Transformers, including BERT and its variants originally developed at Google, can be trained to recognise context and meaning. The result of this training is a mathematical model of a particular language or content area. For the training to work, it needs a large amount of data in this language or context and to indicate success or failure. Feed your source document into a Transformer and the output is a tensor – a multidimensional vector representation for each word in the document, capturing how the model predicts its meaning: note how vectors for similar concepts are close together (this example is of course only three dimensions):
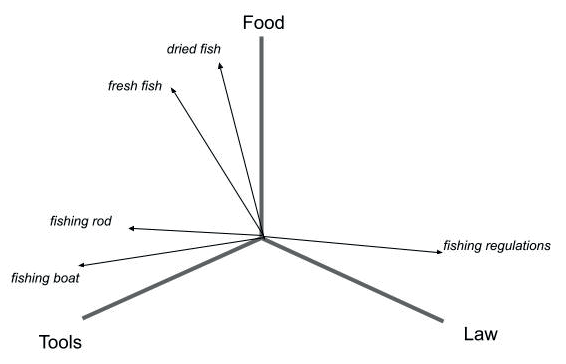
Other machine learning algorithms can be used to extract key features of images, sounds or other types of content as vectors. As these algorithms are often based on neural networks, applications using them are often described as Neural Search engines. The hard part is figuring out what to do with this huge and complex data structure and indeed how on earth to do it at scale – each tensor can have hundreds of dimensions.
Widely used search engine libraries such as Apache Lucene didn’t even have a way to store this kind of data in their index until recently, let alone a mechanism for using it for finding which documents match a query. Max Irwin provides a great example of how this matching might be done in a blog from 2019:
Commonly, the approach is to use a nearest neighbor algorithm. This takes two or more vectors, and calculates the distance (or similarity) between them in an efficient manner. To use a simple example, let’s say we’ve got two people – Alice, standing 5 meters away from a water fountain, and Bob, standing [in a line] 7 meters away from the water fountain. Who is standing closest to the fountain? Alice of course. Now Carrie joins the group and stands 8 meters from the fountain. So who is Carrie standing closest to? Alice or Bob? Well, that’s easy – it’s Bob. That’s similarity with a vector of one feature. We can also have a vector of two features, such as latitude and longitude coordinates, and use that to calculate who is standing closest to the fountain and who are standing in groups close to each other.
Actual algorithms and approaches now appearing in search engine software include K-Nearest Neighbour (KNN), Approximate Nearest Neighbour (ANN) and Hierarchical Navigable Small World (HNSW) graphs (a form of ANN). There is a large collection of software providing vector search capabilities and now many companies providing this as freely available open source or commercial software – here’s a comparison of some current contenders. Recent releases of the Elasticsearch, OpenSearch and Apache Solr search servers (all based on the open source Apache Lucene) include vector search features, whereas the open source Vespa engine natively combines text and vector search at scale.
New approaches to old problems
Let’s first consider why this new vector-based approach might be useful to solve some common problems in search.
Similarity search
A common use case is to find items that are similar to each other in some way. Given a source document, traditional text search engines can easily find other documents that contain some of the same words or phrases, but this approach can lack accuracy. Vector search can power a more accurate similarity search based on meaning. Similarity search can also be useful when the intent of the query isn’t clear.
Question answering
If someone asking a question of an expert system doesn’t use the same terms as the system contains, providing a useful answer can be difficult. Let’s consider healthcare: if I am not a doctor, I may not know that a ‘myocardial infarction’ is a common cause of ‘heart attacks’ – but the automatically extracted meaning of these two phrases could create vectors that are close to each other. My system can then answer a question like “What is a myocardial infarction?” with plain language for the non-medical professional. Models like ColBERT are actually trained on pairs of questions and passages of text, so they work on a much more refined level than keyword search systems that work on the whole document.
Multilingual search
Building language models enables vector-based matching between a query in one language and a document in another. Historically, building text analysis systems for each new language almost duplicates the effort of the first language, leading to few economies of scale. Moving into new languages can also be difficult as you may lack behavioural data for this language. It is also possible to build a shared multilingual model to avoid any need for direct translation, allowing for a query in one language to search content in another (here’s a great demo).
Multimodality
A multimodal search includes different types of content at the same time – for example text and images. As above, vectors can be used to capture features of both textual and not-textual data and then used at the same time to search images directly with a textual query – something that has not been possible before now.
Pushing the limits on search tuning
Tuning an existing search engine is already a constant and complicated process – the complexity, size and richness of the source data is always growing and the number of ‘knobs and dials’ that can be adjusted also increases. Vector-based approaches allow you to capture this richness and help you establish connections between documents in the collection and between documents and queries in a much more expressive way. It’s also worth noting that machine learning approaches such as Learning to Rank (a way to automatically ‘learn’ the best way to re-rank search results initially provided by a traditional text search engine) are now commonly used in search applications – so ML isn’t an entirely new tool for search engineers.
Traditional text search is often used as the basis for a search engine but can be enhanced by this vector-based approach in a two-step process – text search is well understood, scalable and fast, whereas vector search can be hard and difficult to scale. Approaches such as doc2query can even be used in a single stage and beat traditional approaches in some cases according to a recent paper.
Picking a vector search engine
Which route you choose will depend on several factors including:
- Which search platform are you currently using – does it have vector search features or can they be added?
- How much can vector search be a separate add-on to your existing search or do you need a completely new approach?
- Are you able to install and run these complex technologies in-house or would you prefer an externally hosted solution?
- Do you have – or can you acquire either by hiring or training – the new skills in machine learning and data science required?
- Are you prepared to invest in relatively new cutting-edge technology, perhaps from a startup, or would you prefer a more established player?
There is an increasing amount of information on the options available, including the Vector Podcast hosted by Dmitry Kan and talks from OSC’s Haystack conference series. As ever, bear in mind that marketing from a vendor may be biased towards their solution or method, and proofs of concept (POCs) using your data and use case are a vital tool. Traditional text search is well known and understood and extremely powerful when correctly applied, and the benefit from vector search approaches may be limited.
The cost of modelling
One thing we rather glossed over above is the cost of training a machine learning (ML) model on your particular content set. Although publicly available pre-trained models are a starting point (for example, you might find one trained on English language news content) these always need to be fine-tuned for your use case to achieve an acceptable level of quality. How effectively this can be done will depend on the data you have available and you will need lots of training data to be successful. A model you find may not easily transfer to your context.
If you haven’t before, you are now going to have to consider the cost of running machine learning models in your organisation, including the time to create and debug models, the cost of running computationally expensive training cycles and how to rapidly and effectively deploy new models at scale (the operations process commonly called ‘MLOps’). You should be constantly training all of your models on a regular ongoing basis and should think of ML as a manufacturing process that is continually running, not like software engineering which is typically project based.
Dmitry Kan has some ideas on how to measure the results of this investment:
- Each model impact should be evaluated on its influence on the business KPIs e.g. transactions per user, gross merchandise value for e-commerce, grounded in the cost for running ML in the company
- Model level metrics should roll-up to a system KPI. Example metrics are accuracy, Precision, Recall, F1 or more specific like Word Error Rate (WER)
- Since MLOps is an organisational problem, measure the percentage of time spent on infrastructure debugging per ML researcher, average time from training to production deployment, model query monitoring and knowing what to monitor is the key to success – such as drift caused by data change for any reason, including bugs in data
Note that some technology providers promise to handle much of this for you – of course, you will still need to supply them with content and data to work with, and you will need confidence in their ability to deliver, their overall approach to machine learning and indeed their models.
Parting thoughts on vector search
Neural and vector search promise to deliver huge leaps in search quality and can enable use cases that have traditionally been difficult to deliver with traditional text-based approaches. However, there is a plethora of approaches, technologies and companies and it can be hard to choose between them. Effective vector search is hugely reliant on high quality training data and may also require significant investment in machine learning and operations, unless you are able to trust third party providers to do the heavy lifting for you. The future of search undoubtedly contains vector and neural approaches, but as ever remember that all that glitters is not gold!
Further reading
- The Haystack conference series features many recorded talks on vector search
- Dmitry Kan’s blog and his Vector Podcast are worth subscribing to
- The free Relevance Slack (nearly 3000 members to date) has a #vectors-in-search channel for discussion of this new area
- Database technology evolves to combine machine learning and data storage from VentureBeat
If you need help navigating the new world of vector and neural search from our expert team, get in touch.
Image by Frontier Vectors by Vecteezy