Category: Uncategorized
At the recent National Day of Civic hacking here at OSC we dug into a few ways to find relationships between Trademarks files with the USPTO.
If youve ever played with the US trademark data youll know that its both plentiful and scarce. There are lots of trademark fillings, each with the minimum possible data to make them uniquely identifiable.
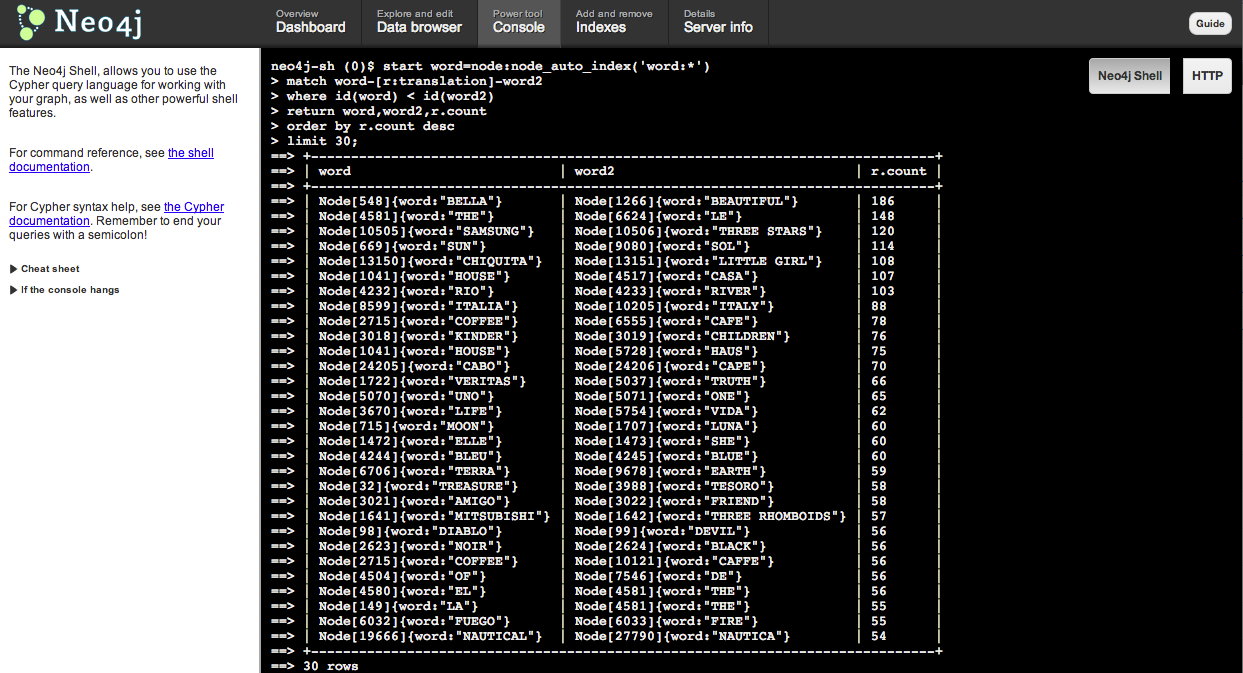
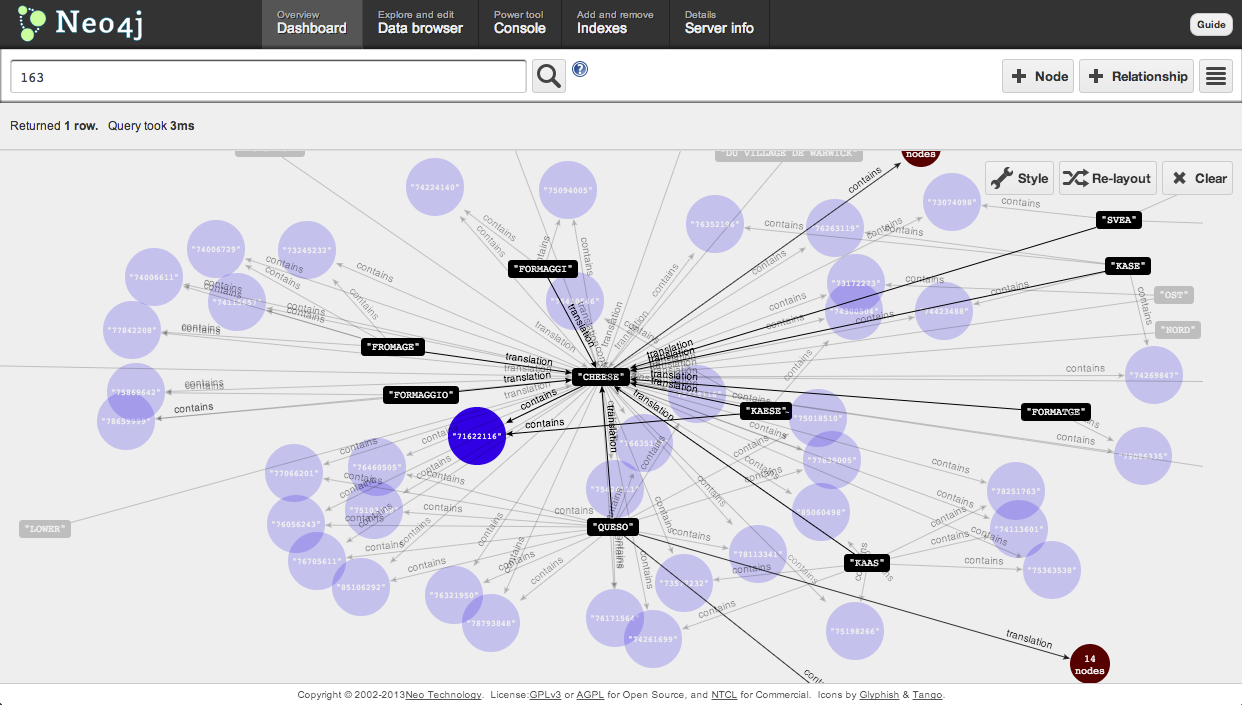
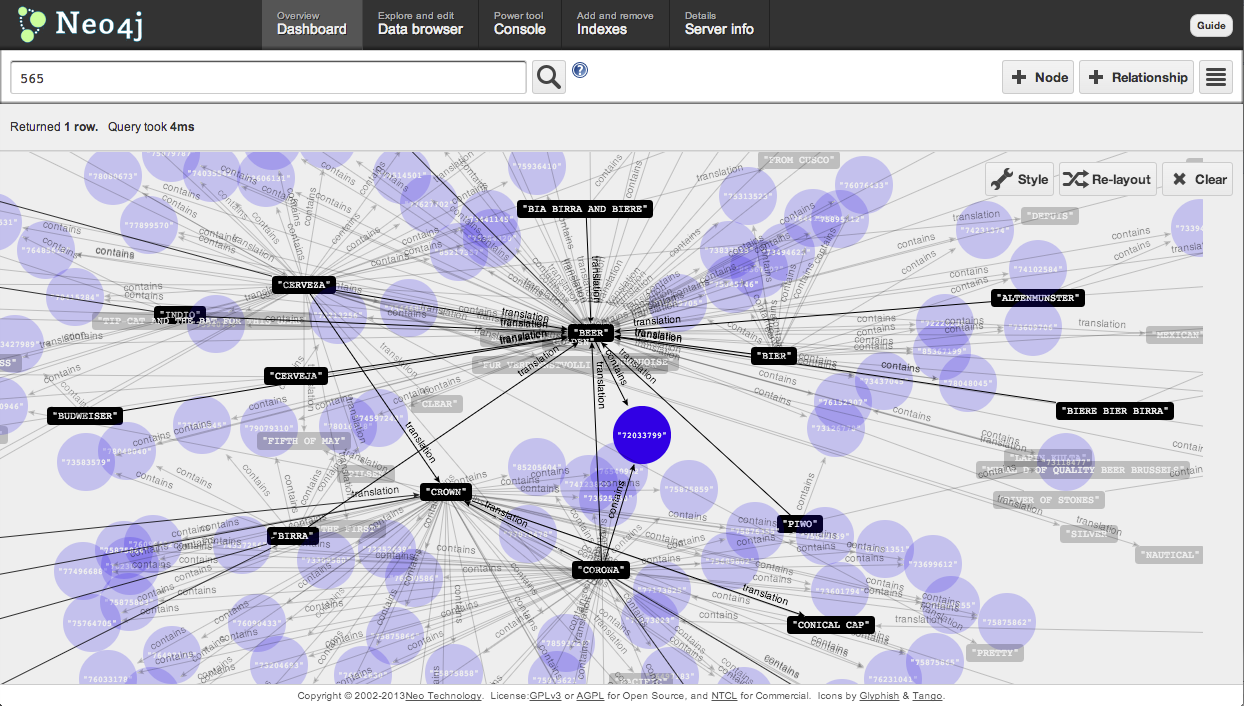
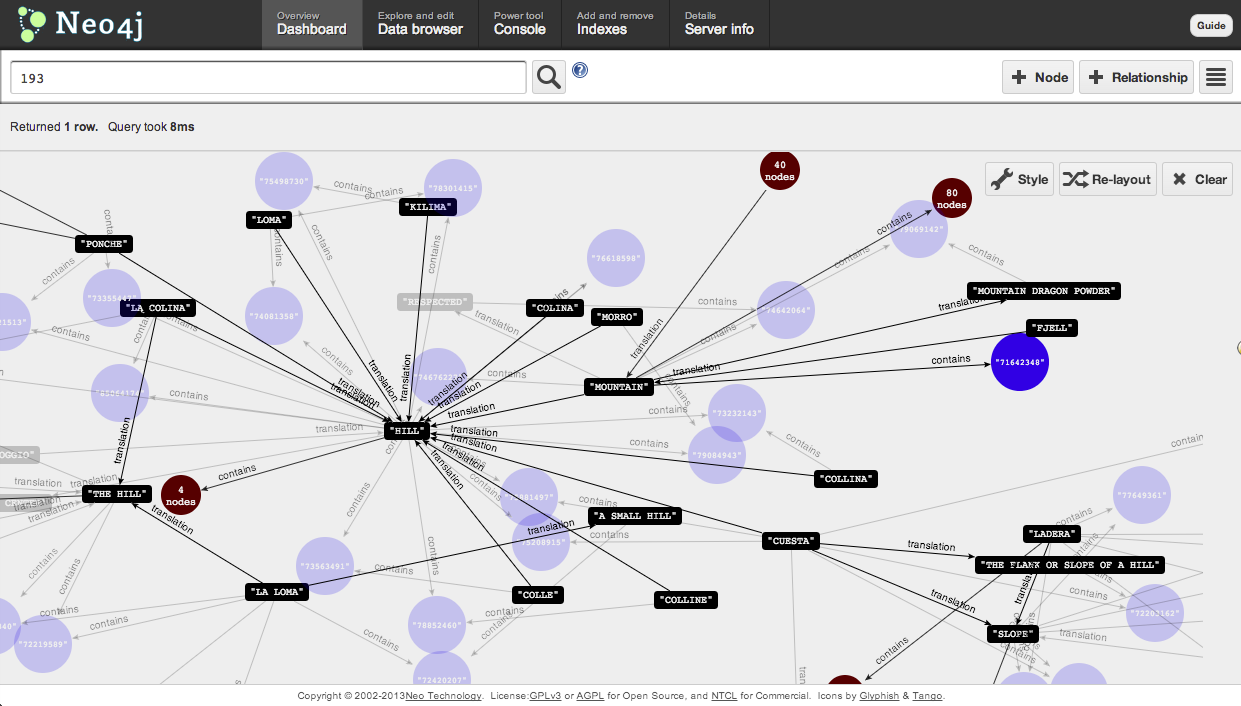
Thats great for streamlined government and citizen anonymity, but no fun for finding the relationships between filings. We needed to suss out more information about the graph of trademarks. Thats when we Eric and Wes tripped over the translations included in many of the patent filings. We wondered if the term space for these translations might be smaller and more consistent then the space defined by the actual trademarks. Translations were less likely to play games with spelling or grammar the way one might with the actual mark.
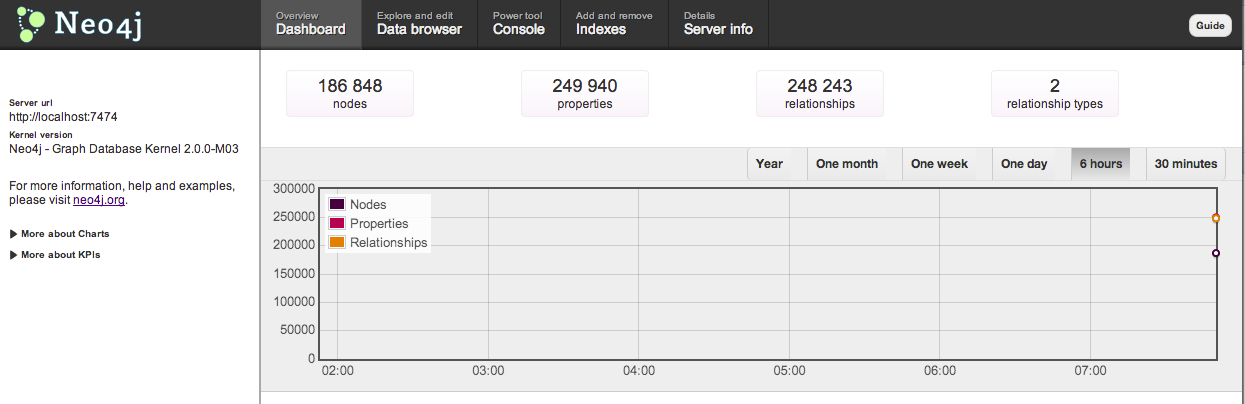
Some Hacking with the data and Neo4j resulted in an intriguing dataset that we are still unpacking. Want to play with the data? Neo4J loaded with data is at this url: http://rosetta.bloom.sh:7474/webadmin/